Loading
|
||
Loading
|
| @IT > オラクルの可用性ソリューションとMAA |
BCP(ビジネス継続性計画)やリスク管理の考え方が広がる中、ITシステムの可用性についても要求が高まっている。しかし、一般に高可用ソリューションは高価で、導入に二の足を踏むユーザーも多々見られる。それに対してオラクルは、いまあるソフトウェア機能を有効活用して可用性を高めることを提唱する。
システム設計における予算配分で、システム設計担当者が大いに頭を悩ますのが、高可用性に対する投資である。 サービスを止めずにメンテナンスやトラブル対応ができるような仕組みを備えようとすると、それなりの投資が必要となることはいうまでもない。しかし、エンドユーザーからの要求が見えやすいアプリケーションの開発やシステムパフォーマンス向上に対する投資とは異なり、有事の際にしかその有用性が見えない高可用性ソリューションへの投資は理解が得られにくかった。 しかし、業務停止のリスクとその影響の大きさを考えれば、可用性向上にコストを配分する必要性が高いことはいうまでもない。特に米国の9.11テロ以降、BCP(ビジネス継続性計画)というキーワードが重視されるようになり、加えて企業の日常オペレーションに多数のITシステムが利用されている今日、ITシステムを“止めない”という要求は重要度を増している。この重要性に気付いている企業は、高可用性の分野に積極的な人的・予算的コストの配分を行っている。 対して技術面では高可用性ソリューションは、どのような仕組みが用意されているのだろうか。オラクルの可用性ソリューションを見てみよう。
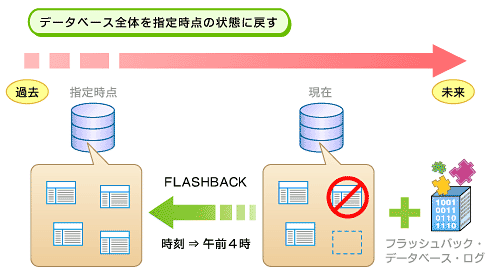
システムの停止は、大きく「計画内」「計画外」の2つに分けることができる。OSやミドルウェアなどのパッチを当てるといった作業は通常、業務が休止する夜間や休日などに計画的に行われる。これが計画内停止である。一方、システム障害が発生するなど意図せざるシステム停止に追い込まれることがある。これが計画外停止だ。 近年はインターネットを介した24時間取引などもあり、計画内停止が難しいという状況が生まれている。他方、計画外停止は一度発生すれば、業務が停止したり、サービスレベルが維持できないといった事態に直結するため、より深刻だ。 つまり、今日的には(1)サービスを止めずにメンテナンスが行えること、(2)障害発生の確率を低くすること、(3)障害からの復帰時間を短くすること、の3つが求められているわけである。 (2)と(3)は従来からある要求だが、基本中の基本でもある。以下、バックアップとリカバリ、ハードウェアおよびネットワーク障害、人為ミス対策、それぞれの障害対策について、それぞれ用意されている解決策を見ていこう。 ■ バックアップとリカバリ データのバックアップと障害時のリカバリ対策機能の装備は常識だ。問題は個々の機能がいかに日常的な業務を遮断しないか、そしていかに障害から素早く復帰できるかが評価のポイントとなる。 Oracle Database 10gにも各種のバックアップ機能が用意されており、増分バックアップも当然装備されているが、高速な増分バックアップを取れるよう、特別な工夫が施されている点がポイントだ。 Oracle Database 10gはデータベースの更新時、データブロックの変更ポイントを記したBlock Change Tracking Fileを生成することができる。このため、データベースの増分を抽出してからバックアップを取る必要がなく、実に素早い高速なバックアップを行える。加えてバックアップ中にかかるデータベースへの負荷が小さいため、バックアップ時におけるシステム・パフォーマンスへのダメージも最小限に抑えることが可能だ。 また、Oracle Secure Backupを用いれば、バックアップデータそのものを暗号化できる。情報漏えいのトラブルとして、バックアップ・テープなどのメディアの盗難・紛失が意外に多いが、メディアに記録されたデータが暗号化されていれば、最悪の結果を防ぐことができる。 ■ ハードウェアおよびネットワーク障害対策 ハードウェア障害に最も有効な手法が、システムの多重化にあることはいうまでもない。オラクルはOracle Real Application Clusters(Oracle RAC)によりデータベースのクラスタリングをサポートしているが、クラスタシステムのポイントはフェイルオーバーをいかに短時間に行えるかだ。 ハードウェアを多重化していても、障害発生時にバックアップシステムへの切り替えに時間がかかると、実質的にはその間、システムが止まってしまうことになる。一般にそうしたシステム停止に許容される時間の目安は5分といわれており、5分以内ならばパフォーマンス低下の問題として処理できるが、5分を超えてシステムが応答しなくなると「システム障害」として認識され、障害レポートの提出などを行わなければならないというSLAが多いようだ。 Oracle RACはすべてのシステムをアクティブな状態で稼働させることが可能で、システムの切り替えを素早く行い、速い場合で数秒、遅くとも数分以内には正常な状態へと復帰できる。実際の事例としてはシステムからの障害メッセージを読むまで、体感的には障害発生に気付かなかったというケースがあるほどだ。 復帰時間はシステム高性能複雑さやアプリケーションによっても変化するが、後述するMAAに基づいてクラスタを構成することで、容易にその切り替えパフォーマンスを引き出すことができる。 ■ 人為ミス対策 人為ミスに対するもっとも有効なOracle Database 10gの機能がフラッシュバック機能である。これは誤ったデータ更新を行ってしまった場合のリカバリを最短化する機能だ。
通常、データベースに誤った処理、指示を出して内容に不整合が起きてしまった場合、バックアップからデータベースを復元し、そこからデータベース更新のジャーナルを用いて不正な更新が行われた時点までのトランザクションを再現、復帰させる。しかし、この方法では完全な復元までにかかる時間が長くなり、システムが長時間にわたってダウンしてしまう。 これに対してフラッシュバックは、時間軸順に記録されたログを参照し、現時点から時間を遡ってデータベースを元の状態に戻すため、バックアップデータのリストアが不要である。これにより、復帰までの時間が短くなるだけでなく、表単位での復帰が可能になるといった柔軟性も引き出せる。
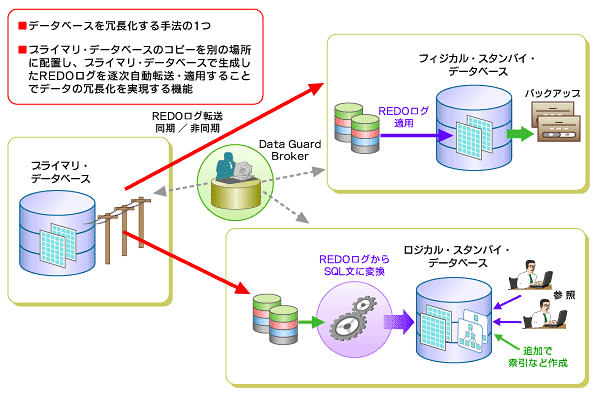
上述のように、オラクル製品には高可用性を実現するための道具が一式そろっているが、さらにそれらとは別に知っておきたいのが、Oracle Data Guardという機能だ。これはソフトウェアの機能でデータベースの複製を自動的に作成し、それをスタンバイデータベースとして待機させておく機能である。
Oracle RACとの違いは、データのコピーを自動的に作成するソフトウェアの機能であることだ。このため、 Oracle RACとは性格が異なり、両者を併用することもできる。 具体的にはREDO(再実行)用のログを別のサーバに転送することで実現しており、ネットワークで接続されていれば、物理的なサーバの場所は問われない。例えば東京にあるメインシステムのデータベースを、大阪にあるサブシステムのデータベースと同期させておくこともできる。ネットワーク透過であればよいだけなので、実にさまざまな形態でスタンバイデータベースを構築できる。 Oracle Data Guardにはフィジカル・スタンバイとロジカル・スタンバイの2種類がある。フィジカル・スタンバイは、データベース上の物理的な配置までを同一化する完全なスタンバイを作成する機能だ。 これに対してロジカル・スタンバイは論理的に同一のデータベースを作る手法で、物理的なデータブロックの配置は変更可能で、表単位のデータを同一化する機能。従って物理的なデータベースの構成はシステム設計に依存する。 両者はスタンバイ用データベースをREDOログから生成する点は同じだが、フィジカル・スタンバイが障害時、即座に元のシステムに取って代わることに特化しているのに対して、ロジカル・スタンバイは、REDOログの内容をSQL文に変換してからデータベースを更新する仕組みを取っており、同じデータベースを参照用として利用することができる。例えば東京のロジカル・スタンバイを大阪に作成しておけば、大阪のユーザーは東京にあるオリジナルのデータベースではなく、大阪にある複製されたデータベースを参照用に利用することでレスポンスを改善できるという使い方もある。
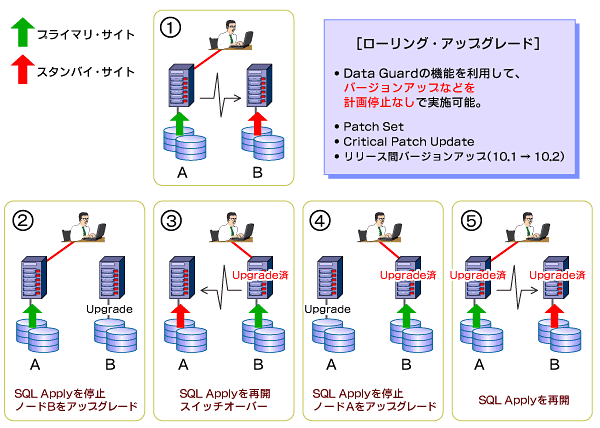
このほか、無停止でデータベースのアップグレードを行うために、ローリング・アップグレードという手法も提供されている。これはサーバをスタンバイ側に切り替え、メインのサーバのソフトウェアをアップグレード。制御をメイン側に戻し、次にスタンバイ側のアップグレードを行うというものだ。
特にWebからコンシューマ向けのサービスを提供している企業などでは、最新機能をフルに活用して常に新機能を提供し続けなければならないといった事情もあり、最新パッチを細かく当てていく場合などには有効な手法といえる。 ところで、これら機能が製品に実装されているというだけでは、最良の価値が顧客に提供されたことにはならない。他ライバルにはない多くの機能を持つオラクルの製品だからこそ、高可用なシステムを実現するための方法や構成の具体的なベストプラクティスが求められる。 例えばOracle Data Guardは、基本的にはフィジカル・スタンバイで構成する。しかし、上述のローリング・アップグレードのように、アップグレード専用のスタンバイサーバを追加構築するというのであれば、ロジカル・スタンバイの構成が必要になる。すなわち、適材適所に機能を組み合わせることが重要なのである。
これまで見てきたように、オラクルは提供する各種製品に、可用性を高めるためのさまざまな機能を組み込んでいる。選択肢が数多く用意されているのはうれしいことだが、逆に問題も発生する。具体的に“可用性を高める”ためには、想定する状況や解決すべき問題に応じて、適用すべき機能をよく見極めて、適切に選ばなければならないのだ。 システム全体を見渡し、効率よく可用性を高める機能を最適な状態で組み合わせるにはどうすればいいのか? 多様な機能、高度な機能が提供されているほど、実際のシステムの状況に合わせた最適解を導くのは難しい。 そこでオラクルが用意したのが「Maximum Availability Architecture(MAA)」である。これはオラクルが製品に実装している数多くの高可用性を実現する機能を組み合わせ、最適なシステム構築を行うためのベストプラクティスをまとめたブループリント(青写真)だ。 MAAは、高可用システムに関する問題解決のための具体的な方法が記されたドキュメントで、ユーザーに対して無償で公開されている。シティコープやメリルリンチといった金融企業も、システムをノンストップで運用するためのソリューションとしてMAAを採用しているという。高可用性システムを設計するための虎の巻といってもいいだろう。 可用性を高める方法としては、高機能なハードウェアに投資するといったやり方があるが、それだけではコストパフォーマンスが悪い。ソフトウェアの機能やシステム構成を見直すことで解決できる部分も少なくないのだ。MAAを参照することで、ユーザーは個々の案件に対し、個別に可用性を高める投資やシステムの変更を行い、ITシステム全体が複雑化しすぎてしまうといったリスクを回避し、少ない投資で最大限の効果を得ることができるのだ。 MAAは製品に実装される機能の増加や仕様変更に応じて、また幅広く数多くの大規模顧客への適用経験を経てアップデートが続けられている。こうしたアイディアは、すべて先人たちが工夫をする中で見つけてきたことだ。そしてそのノウハウはMAAの中に息づき、継承され、日夜進化しているのである。
提供:日本オラクル株式会社 企画:アイティメディア 営業局 制作:@IT編集部 掲載内容有効期限:2007年5月31日 |
|