米HP、ビッグデータ活用基盤製品を強化。「原点回帰」を強調:「HP Discover 2012」をラスベガスで開催
米HPは6月3日、米国ラスベガスで年次イベント「HP Discover 2012」を開幕した。6日までに多数のセッションを予定している中、4日のプレスカンファレンスでは、バックアップ製品「HP StoreOnce」シリーズのバックアップ、リカバリ作業を大幅に効率化する重複排除ソリューション「HP StoreOnce Catalyst」などを発表。他社製品と比較しながら大量データの確実・効率的な管理、保護の優位性を訴えるなど、ビッグデータトレンドへの積極的な対応と、サーバ、ストレージ、ネットワークなど、目的に応じたIT基盤を統合的かつシンプルに管理可能にする概念「HP Converged Infrastructure」の強みをあらためて強調した。
1時間当たり100テラバイトのバックアップを実現
近年、企業を取り巻くデータ量は爆発的に増大し、構造化データのみならず、ソーシャルメディア上のデータなど“人にまつわる”非構造化データも企業にとって重要な資産となっている。これに伴いデータを蓄積するストレージも大規模化、複雑化し、スペックに対して十分なデータが蓄積できていない、管理が煩雑になるなど、時間、コスト面で企業に負担をかけている。
 米HP エグゼクティブバイスプレジデントのデイブ・ドナテリ氏
米HP エグゼクティブバイスプレジデントのデイブ・ドナテリ氏カンファレンスで最初に登壇した米HP エグゼクティブバイスプレジデントのデイブ・ドナテリ氏は、この点について、「現在はストレージの進化の過渡期にある。管理が難しく、コストも掛かり、過去の仕様で構築されているため十分に活用し切れていない。弊社ではこの点に着目し、ミッドレンジからハイエンドのエンタープライズ向けまで、共通のアーキテクチャを持つ、よりシンプルなストレージを提供し、あらゆる顧客企業のROI向上に寄与したい」と解説した。
この話を引き継いで登壇した米HP シニアバイスプレジデント ゼネラルマネージャのデビッド・スコット氏は、「ストレージのパフォーマンスを左右する要因は、特にデータの重複にある」と指摘し、これを解決するものとして、バックアップ製品「HP StoreOnce Backup System」シリーズに、重複排除ソリューション「HP StoreOnce Catalyst」を追加したと発表した。
HP StoreOnce CatalystはHP StoreOnce Backup Systemにデータが転送される前に、アプリケーションサーバ、あるいはバックアップサーバ上でデータの重複排除を実現するソフトウェア。バックアッププロセスの最適化、無駄なリソースの排除、ネットワーク帯域幅のコストダウン、バックアップスループットの向上を実現する。中でもHP StoreOnce Backup Systemシリーズのハイエンド製品、「HP StoreOnce B6200 BackupSystem」と組み合わせると、1時間当たり100テラバイトのバックアップ、1時間当たり40テラバイトのデータリカバリが可能になるという。
 EMC製品とバックアップ性能を比較して優位性をアピールする米HPのデイブ・スコット氏
EMC製品とバックアップ性能を比較して優位性をアピールする米HPのデイブ・スコット氏スコット氏はここでHP StoreOnce B6200 BackupSystemとHP StoreOnce Catalystを組み合わせた場合と、EMCの重複除外バックアップ製品「EMC Data Domain DD990」に、重複除外のフローをバックアップサーバとストレージに分散させてバックアップのスピードを高める「EMC Data Domain DD Boost」を組み合わせた場合のパフォーマンスを比較。「バックアップ速度は約3倍、データリカバリ速度は約5倍となり、他社製品では1週間かかるリカバリ作業も1日で終えられる」と述べ、競合製品に対する強い自信をうかがわせた。
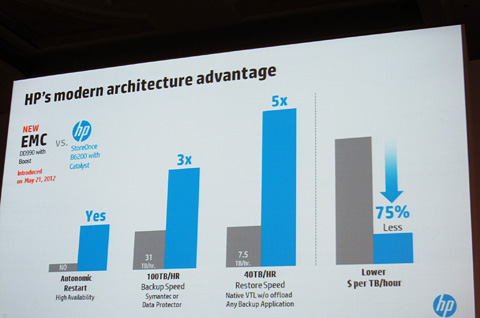 「EMC Date Domain DD Boost」を組み合わせた場合のパフォーマンスの違いを比較。「バックアップ速度は約3倍、データリカバリ速度は約5倍」になるという
「EMC Date Domain DD Boost」を組み合わせた場合のパフォーマンスの違いを比較。「バックアップ速度は約3倍、データリカバリ速度は約5倍」になるというこのほか、ビッグデータへの取り組みの一環として、2つのソリューションを紹介。1つは2011年、米HPが買収したオートノミーの解析エンジン「Autonomy Intelligent Data Operating Layer(IDOL)」に、HPのサーバ向けバックアップソフトの最新版「HP Dataprotector 7」を搭載したこと。構造化/非構造化データの内容からカテゴリ化、リンク付け、要約作成などを自動的に行うIDOLの機能を利用し、情報のコンテキストに基づく合理的なバックアップ、リカバリを実現。データの内容に配慮した、より正確な情報の保護、検索、リカバリを可能にしたという。
2つ目はサーバとストレージを接続する専用ホストバスアダプタ、スイッチ、関連ケーブルを不要にするI/O仮想化テクノロジを活用した「HP Virtual Connect for 3PAR with Flat SAN technology」だ。従来の多層構成のファイバチャネルネットワークでは、変化するネットワークトラフィックパターンに合わせた、ネットワークカード、相互接続、ケーブル、スイッチの複雑な構成が必要だったが、「ストレージプロトコルレイヤを削減することで、複雑性を排除し、従来型のアーキテクチャよりレイテンシを55%減少させる」と解説した。
「原点回帰――ITインフラをコアビジネスにする」
一方、午後のセッションでは、ビッグデータの「分析」にフォーカス。まず大量データの管理・活用基盤として「Apache Hadoop向けHP App System」を紹介した。HP App Systemは、例えばデータベースやBI、コラボレーションツールなど、特定のアプリケーションの性能を最大化できるようハードウェアの構成を最適化して提供するアプライアンス製品。これにHadoopを利用することで処理速度を大幅に向上させたという。
登壇した米HPバイスプレジデントのポール・ミラー氏は、「このApache Hadoop向けHP App Systemに、リアルタイム分析製品、Vertica 6を組み合わせることで、膨大な量のデータ処理とリアルタイムでの高速分析を実現する」と解説。さらに、Vertica担当役員 コリン・マホニー氏、オートノミー担当役員 ラフィグ・モハマディ氏らに話を引き継ぎ、Vertica 6と、映像やソーシャルメディア上の情報など、非構造化データの分析に強みを持つ「Autonomy IDOL」とを組み合わせることで、「大量・多種のデータから次のアクションにつながる知見をリアルタイムに引き出す強力な分析基盤が整う」(コリン氏)と力説した。
また、米HPでは、ビッグデータをビジネスに有効に活用していくために、企業の目標とデータ活用のためのITインフラ整備の在り方を連携させるノウハウを解説する「HPビッグデータ戦略ワークショップ」と、Hadoopの活用を成功に導くためのロードマップ策定を支援する「HP Hadoopロードマップサービス」も併せて提供するなど、ビッグデータ管理基盤強化に対する姿勢をさまざまな角度からアピールした。
このように本カンファレンスを俯瞰すると製品の多さばかりが印象に残りがちだが、2つのカンファレンスを通じて登壇者らが最も強調していたのは、サーバやストレージ、ネットワーク、アプリケーションなどを統合的に管理可能にする「HP Converged Infrastructure」という同社が2009年から訴えてきた概念だ。
 ビッグデータ管理・活用基盤の製品ポートフォリオを拡充。「インフラをコアビジネスとする」という姿勢がうかがえた
ビッグデータ管理・活用基盤の製品ポートフォリオを拡充。「インフラをコアビジネスとする」という姿勢がうかがえたオートノミー、3PAR、Verticaなど買収企業の製品も加わり、非常に幅広い製品ポートフォリオを持っているが、それらを企業の戦略・目的に合わせてピックアップ、有機的に統合し、シンプルな形で提供するという。
クラウド、ビッグデータのトレンドに対応するために、多くの企業がITインフラの運用管理の複雑化、コスト増大に悩んでいる。その解決にフォーカスした今回の発表内容からは、2011年9月にメグ・ホイットマン(Meg Whitman)氏が社長兼CEOに就任して以降の、「原点回帰――ITインフラをコアビジネスにする」という同社の姿勢が強くうかがえた。
Copyright © ITmedia, Inc. All Rights Reserved.
注目のテーマ




人気記事ランキング
- 生成AIは検索エンジンではない 当たり前のようで、意識すると変わること
- VPNやSSHを狙ったブルートフォース攻撃が増加中 対象となる製品は?
- 大田区役所、2023年に発生したシステム障害の全貌を報告 NECとの和解の経緯
- ランサムウェアに通用しない“名ばかりバックアップ”になっていませんか?
- 標的型メール訓練あるある「全然定着しない」をHENNGEはどう解消するのか?
- “脱Windows”が無理なら挑まざるを得ない「Windows 11移行」実践ガイド
- HOYAに1000万ドル要求か サイバー犯罪グループの関与を仏メディアが報道
- 「Gemini」でBigQuery、Lookerはどう変わる? 新機能の詳細と利用方法
- 爆売れだった「ノートPC」が早くも旧世代の現実
- 攻撃者が日本で最も悪用しているアプリは何か? 最新調査から見えた傾向
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。