Loading
|
||
Loading
|
| @IT > @IT Special PR:SPSS Data Mining Day 2007 イベントレポート後編 |

尾崎氏は、近年、インターネットの一般家庭への浸透によって、ブログに代表されるCGM(Consumer Generated Media)と呼ばれるテキストデータが増加、そのデータの活用が注目されていることに触れ、定性的なテキストデータは、分析に大変な労力を要する場合が多いものの、分析者の仮説を超える思いがけない回答が得られる可能性を指摘する。 従来、テキストマイニング手法としては、次の2つがあったという。
例えば、「住宅購入の目的は何ですか」という設問に対する回答として「自宅で店をやるため」というものがあった場合、分析結果は以下のようになる。
こうした分析は、上記のような設問に対する答えであったり、要点が絞られているテキストデータであれば有効な情報を抽出できるが、特に制約のないブログのような自由記述の場合、文章が長くなりがちなため従来の分析方法では課題が残るという。というのは、出現するすべての単語、または係り受けを抽出してしまうためあまり意味のないごみ情報が多数抽出されてしまうため、効果的なテキストデータ分析が困難になってしまうからだ。 そこで、テキスト情報から「感性情報」を見つけることが、テキスト情報の効果的な分析につながると考えて開発されたのがテキストマイニング・ツール「なずき」である。
「なずき」では、単語+単語+ニュアンスの組み合わせから感性を示す表現を収集し、感性と表現の組み合わせのルール化を行っているという。これによって、感性情報の抽出と感性のタイプによる分析を実現している。同氏は次のような具体例を示してくれた。
上記のような、単語+単語+ニュアンスの組み合わせから生じる感性表現と、感性のタイプの対応関係は360億のルール(知識)も「なずき」に格納されており、精度の高い評価情報の抽出が可能となっているそうだ。例えば、ある温泉旅館についてのWeb上に記載された口コミデータをなずきで分析すると、評価の対象となる「料理」「温泉」などに対するさまざまな評価、すなわち「好評」「苦情」「要望」など感性表現のタイプ別の件数が自動的に算出される。 こうした評価情報は、従来は形容詞(良い、悪い)と簡単なニュアンス(である・ではない)の組み合わせによる「ポジティブ(肯定的)な表現vsネガティブ(否定的)な表現」といった2分法で行うのが精一杯だったが、なずきでは、多様な感性タイプ(最大81種類)別の分析ができるため、それだけ精緻な分析が可能という。 また、テキスト情報活用の有効性について、仮説では抽出できない情報が得られること、加工されていない生の声(気持ち:感性)が現れること、ブログなどの活用によってリアルタイムに偏りのない多様な情報を収集/分析できることの3点を挙げて講演を終えた。
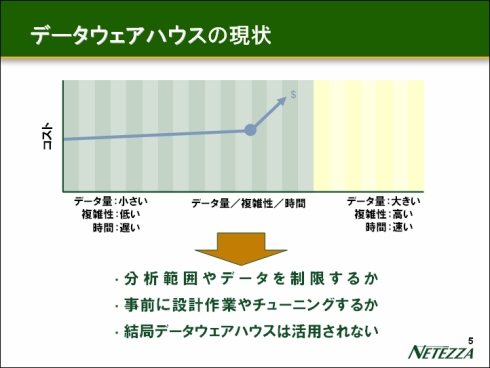
当講演では、大規模データを対象とするデータマイニングシステムが、SPSS、日本ネティーザ、日本電気の3社がそれぞれの強みを結集することによって実現できることが示された。3社の強みとは、具体的には、SPSSがデータマイング、日本ネティーザがデータウェアハウス、日本電気がシステムインテグレーション(SI)である。 SPSSの鈴木貴志氏による3社連携の全体像の紹介に続いて、日本ネティーザのエッツエル氏によって、まず同社のDWHアプライアンス(サーバ)の紹介が行われた。同氏は、現在のデータウェアハウスを取り巻く環境として、次の3つのポイントを挙げた。
同氏は、データ量が増大したり、分析ニーズが複雑かつ高度化したり、分析スピードの短縮化が求められる場合、ある時点から急激にコスト負担が増大すると指摘する。そして、コストを抑えるために、分析範囲や分析対象となるデータの量そのものを制限せざるを得なくなったり、システム設計の見直しやチューニングに手間をかけなければならなくなる。その結果、データウェアハウスは利用されないシステムとなってしまう。
同社のDWHアプライアンス「Netezza Performance ServerTM(NPS)」は、従来のデータウェアハウスの10〜100倍のパフォーマンスを、通常の半額程度のコストで提供する製品であるという。
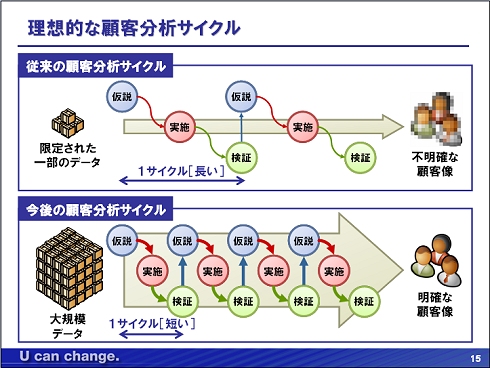
このおかげで、大規模データに対する複雑な分析要求にも分析結果を迅速に返すことのできるデータウェアハウスが構築可能になるのだそうだ。 次に、日本電気の外賀氏より、大規模データを活用した顧客分析例の説明が行われた。まず外賀氏は、企業が、継続的な顧客分析サイクルを実施することで、常に変化し続ける顧客のニーズや新たな消費スタイルを正確に把握し、迅速な意思決定を行うことができるようになることを強調、そして、大規模データに対して、仮説→実施→検証の顧客分析サイクルをできるだけ短い周期で回すことによって、顧客像がより明確になることを示した。
大規模データを活用しようとすると、データの増大につれてデータ処理時間が夜間バッチでも追いつかなくなり、高価なハードウェアが必要とされてくるのが現状だという。すなわち、大規模データの顧客分析においては、「処理時間の壁」「コストの壁」をどうやって乗り越えるかが課題となる。
続けて同社の孝忠大輔氏より顧客分析のデモンストレーションが行われた。それは、1000店舗を擁するコンビニエンスストアの1年間のPOSデータの分析を行ったものであった。ここで扱われたデータは、どの顧客がどんな商品を買ったのかを識別できるものであり、5億レコード、約40GBのボリュームがある。同氏は、このデータを用いて、店舗別のRFM分析や、店舗別の顧客セグメント分析や併売分析などを実行してくれたが、大規模データにもかかわらず、レスポンスの良さには驚かされるものがあった。まさに、SPSS、日本ネティーザ、日本電気の3社の強みが合わさることで優れた分析システムが構築できることが実感できた。
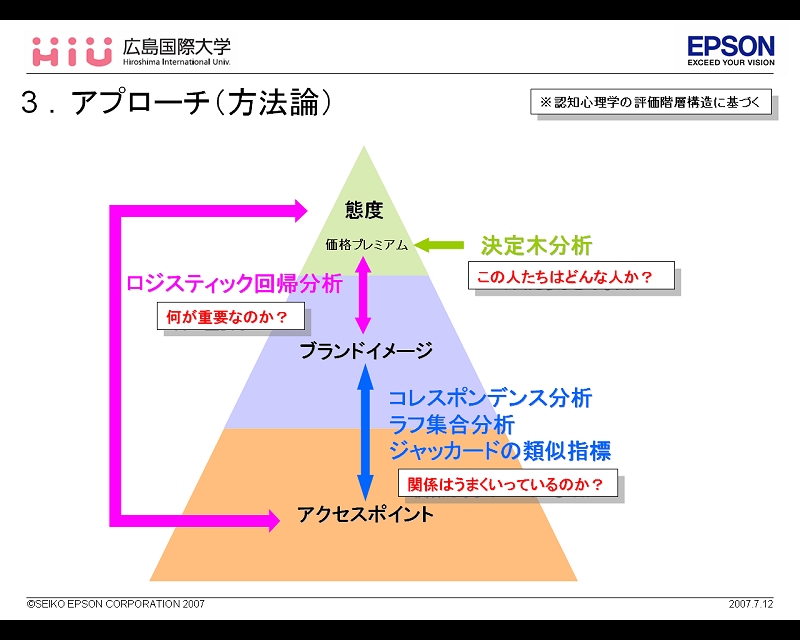
野本氏、布施氏によれば、セイコーエプソンでは、商品デザイン分野で活用されている分析手法である「感性工学的アプローチ」を用いて、同社のコーポレートブランド力向上のためのプロセスと方法論を研究しているという。 野本氏は、コーポレートブランドの研究に着手する以前は、消費者が「買いたい」と思ってもらえるためには、製品はどんなイメージやデザイン(形状)を持たせるべきかを研究していたそうだ。例えば、「“買いたい”プリンタとはどのような造形のプリンタなのか」といったテーマに取り組み、認知心理学の知見に基づき、「態度」「イメージ」「認知部位」の3つの階層構造で分析を行っていたという。 この階層構造において「態度」とは、消費者の「買いたい」「魅力的」「かっこいい」といった製品に対する評価を指す。そして、「態度」は「イメージ」による影響を受けていると考えられる。「イメージ」とは、「斬新な」「シンプルな」「高級な」といった製品から受ける印象のことを指す。また、このイメージは、「認知部位」、すなわち、製品の全体形状や造形処理、色彩などの要素を持つ。逆にいえば、消費者は、認知部位(製品の形や色など)を見て、なんらかのイメージ(製品から受ける印象)を抱き、その結果として「買いたい」「魅力的」といった態度(製品への評価)を形成するということだ。 野本氏は、この考え方をデザインだけでなく、ブランドにも適用することにしたという。そうした場合、「態度」に該当するのはそのブランドへの評価、すなわち「ブランドロイヤルティ」となり、同様に「イメージ」はブランドへの印象、そして「認知部位」は消費者がそのブランドに接触する場面、つまり「アクセスポイント(企業側が仕掛けるさまざまなコミュニケーション施策)」と置換することができる。
そして、この枠組みに基づき、つぎのような項目について検証を行ったそうだ。
次に、布施氏が行った情報機器業界のほかの8社との比較を通して、具体的に何が分かったかを説明してくれた。 例えば、「コレスポンデンス分析」においては、ブランドイメージとアクセスポイントとの傾向の類似性について、 2次元上のプロットされた点の距離の近さによって、視覚的に関係性をとらえらることができた。また、「ジャッカードの類似指標」ではほかの8社との差分の大きさを色分けすることで、一目で自社の強みと弱みを視覚的に把握することができ、さらに「ラフ集合分析」では、ロイヤルティのある人とない人とのアクセスポイントの経験差をクロス集計し、分析することで新たな知見を得たという。 最後に野本氏が、感性工学的アプローチを採用することのメリットを以下のようにまとめてくれた。
また、今後は定量と定性の合わせ技として、定性情報を定量化し、両方を組み合わせた分析を行っていきたい、と締めくくり講演を終えた。
提供:エス・ピー・エス・エス株式会社 企画:アイティメディア 営業局 制作:@IT 編集部 掲載内容有効期限:2007年9月27日 |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||