Loading
|
پ—ITپbپ—ITژ©•ھگي—ھŒ¤‹†ڈٹپbQAپ—ITپbƒCƒxƒ“ƒgƒJƒŒƒ“ƒ_پ[پ{ƒچƒO | |
|
Loading
|
| پ@پ—IT > SPSSژ–—ل’T‹پ ‘و10‰ٌ “ْŒo‚a‚oƒRƒ“ƒTƒ‹ƒeƒBƒ“ƒO•ز |
| پ@ | |
| ٹé‰وپEگ§چىپFƒAƒbƒgƒ}پ[ƒNپEƒAƒCƒeƒB
‰c‹ئٹé‰و‹ا Œfچع“à—e—LŒّٹْŒہپF2003”N7Œژ31“ْ |
|
|
|
|
| پ@ |
پ@‹ك”NپAڈ¤•iپEƒTپ[ƒrƒX‚ج‹دژ؟‰»‚ھگi‚فپAگ»•i‚ج‹@”\‚âگ«”\‚ب‚ا‚ً‘i‹پ‚·‚邾‚¯‚إ‚حپA‚à‚ح‚â‹£چ‡‘¼ژذ‚ةچ·‚ً‚آ‚¯‚邱‚ئ‚ھ“‚‚ب‚ء‚ؤ‚«‚ؤ‚¢‚éپB‚»‚¤‚µ‚½’†‚إپAٹé‹ئ‚ج‹ئگر‚ة‘ه‚«‚ب‰e‹؟‚ً—^‚¦‚éƒLپ[ƒڈپ[ƒh‚ئ‚µ‚ؤپAٹé‹ئ‚âگ»•i‚ج‚à‚آپuƒuƒ‰ƒ“ƒhپv‚ة‘خ‚·‚éٹضگS‚ھچ‚‚ـ‚ء‚ؤ‚¢‚éپBپuƒuƒ‰ƒ“ƒhپv‚ئ‚¢‚ء‚ؤ‚àپAٹCٹO‚جچ‚‹‰•i‚ج‚±‚ئ‚إ‚ح‚ب‚¢پB پ@—ل‚¦‚خپAپuƒ\ƒjپ[پvپuVAIOپvپuƒfƒBƒYƒjپ[پvپuUNIQLOپv‚ب‚اپAٹé‹ئ–¼‚»‚ج‚à‚ج‚â‚»‚جٹé‹ئ‚جگ»•i–¼‚ھƒ†پ[ƒUپ[‚ة—^‚¦‚éپuگM—ٹ‚إ‚«‚éپvپuٹvگV“Iپvپuگe‚µ‚ف‚â‚·‚¢پv‚ئ‚¢‚ء‚½پgچDٹ´“xپh‚âگ»•i‚ً‘I‘ً‚·‚éچغ‚جٹîڈ€‚ئ‚à‚ب‚éپgƒvƒ‰ƒXƒCƒپپ[ƒWپh‚ً”؛‚ء‚½–¼ڈج‚ج‚±‚ئ‚إ‚ ‚éپB‚±‚جˆê’©ˆê—[‚إچ\’z‚·‚邱‚ئ‚ح‚إ‚«‚ب‚¢پuƒuƒ‰ƒ“ƒhپv‚ھپAٹé‹ئ‚ج‹£‘ˆ—Dˆتگ«‚ًٹm•غ‚·‚é‹Mڈd‚بŒo‰cژ‘ژY‚ج1‚آ‚ئ‚µ‚ؤ”F’m‚³‚ê‚ؤ‚¢‚éپB پ@چ،‰ٌ‚حپA“ْŒo‚a‚oƒRƒ“ƒTƒ‹ƒeƒBƒ“ƒO‚ھژہژ{‚µ‚½ƒuƒ‰ƒ“ƒhƒCƒپپ[ƒW’²چ¸پuƒuƒ‰ƒ“ƒhپEƒWƒƒƒpƒ“2003پv‚ة‚¨‚¢‚ؤپASPSS‚ئ‹¦—ح‚µپAژ©—R‰ٌ“ڑƒfپ[ƒ^‚ًƒeƒLƒXƒgƒ}ƒCƒjƒ“ƒO‚·‚é‚ئ‚¢‚¤گV‚µ‚¢ژژ‚ف‚ة‚آ‚¢‚ؤڈع‚µ‚کb‚ً•·‚‚±‚ئ‚ھ‚إ‚«‚½پBژوچق‚ة‚²‹¦—ح‚¢‚½‚¾‚¢‚½‚ج‚حپA“ْŒo‚a‚oƒRƒ“ƒTƒ‹ƒeƒBƒ“ƒO ’²چ¸‘و“ٌ•” ‰غ’· âV“،ŒP”Vژپ‚إ‚ ‚éپB
پ@پuƒuƒ‰ƒ“ƒhپEƒWƒƒƒpƒ“پv‚حپAƒmƒ~ƒlپ[ƒgƒuƒ‰ƒ“ƒhگ”‚ج‚×1500پA’²چ¸‘خڈغژزگ”3–œ8000گl‚ئ‚¢‚¤چإ‘ه‹K–ح‚ًŒض‚é’²چ¸‚ئ‚µ‚ؤپA“ْŒo‚a‚oƒRƒ“ƒTƒ‹ƒeƒBƒ“ƒO‚ھ2001”N‚©‚ç”N‚P‰ٌژہژ{پB’²چ¸Œ‹‰ت‚ح•ٌچگڈ‘‚ئ‚µ‚ؤ‚ـ‚ئ‚ك‚ç‚êپA100ˆبڈم‚جٹé‹ئپE’c‘جپEŒ¤‹†‹@ٹض‚ب‚ا‚إٹˆ—p‚³‚ê‚ؤ‚¨‚èپA‚à‚ء‚ئ‚àگM—ٹگ«‚جچ‚‚¢ƒuƒ‰ƒ“ƒh•]‰؟‚ج1‚آ‚ئ‚µ‚ؤ”F’m‚³‚ê‚ؤ‚¢‚éپB2003”N4Œژ‚ة‚حپAچإگVƒŒƒ|پ[ƒgپuƒuƒ‰ƒ“ƒhپEƒWƒƒƒpƒ“2003پv‚ھ”•\‚³‚ꂽپB
پ@پuƒuƒ‰ƒ“ƒhپEƒWƒƒƒpƒ“پv‚ج’²چ¸‚حپA‘ه‚«‚‚Q‚آ‚ة•ھ‚¯‚ç‚ê‚ؤ‚¢‚éپB‚P‚آ‚حپAˆê”تڈء”ïژز‚ةƒuƒ‰ƒ“ƒh‚ً•]‰؟‚µ‚ؤ‚à‚炤ƒRƒ“ƒVƒ…پ[ƒ}پ[ژsڈêپiBtoCپj•ز‚إپA—X‘—–@پA‚¨‚و‚رƒCƒ“ƒ^پ[ƒlƒbƒg’²چ¸‚ً•ہچs‚µ‚ؤژہژ{پB‚à‚¤‚P‚آ‚حپAƒrƒWƒlƒXƒpپ[ƒ\ƒ“‚ةƒrƒWƒlƒX‚ئ‚¢‚¤ٹد“_‚إƒuƒ‰ƒ“ƒh‚ً•]‰؟‚µ‚ؤ‚à‚炤ƒrƒWƒlƒXژsڈêپiBtoBپj•ز‚إپA‚±‚؟‚ç‚حƒCƒ“ƒ^پ[ƒlƒbƒg’²چ¸‚ج‚ف‚ًژہژ{‚·‚é‚ئ‚¢‚¤‚à‚ج‚إ‚ ‚éپB پ@پuƒuƒ‰ƒ“ƒhپEƒWƒƒƒpƒ“2003پv‚إ‚حپABtoC’²چ¸‚إ–ٌ1000ƒuƒ‰ƒ“ƒhپABtoB‚إ‚ح–ٌ500ƒuƒ‰ƒ“ƒh‚ً‘خڈغ‚ئ‚µ‚ؤپA‘ه‹K–ح‚ب’²چ¸‚ھچs‚ي‚ꂽپB‚؟‚ب‚ف‚ةپABtoCژsڈê‚ة‚¨‚¯‚éڈمˆت3ˆت‚حپAپu1ˆتپFƒ\ƒjپ[پvپu2ˆتپFƒfƒBƒYƒjپ[پvپu3ˆتپFƒtƒWƒeƒŒƒrپv‚إ‚ ‚ء‚½پB‚ـ‚½پABtoBژsڈê‚ة‚¨‚¢‚ؤ‚حپu1ˆتپFƒ\ƒjپ[پvپu2ˆتپFƒzƒ“ƒ_پvپu3ˆتپFƒgƒˆƒ^ژ©“®ژشپv‚ئ‚¢‚¤Œ‹‰ت‚ھڈo‚ؤ‚¢‚éپB
پ@پuƒuƒ‰ƒ“ƒhپEƒWƒƒƒpƒ“پv‚إ‚حپAŒِگ³‚إچ‚“x‚ب•]‰؟پE•ھگح‚ًچs‚¤‚½‚ك‚ةپA“Œ‹‘هٹwŒoچدٹw•”‹³ژِ •ذ•½ڈG‹Mژپ‚ھˆدˆُ’·‚ً–±‚ك‚éپAƒuƒ‰ƒ“ƒhپEƒ}پ[ƒPƒeƒBƒ“ƒOپE“Œvٹw‚جگê–ه‰ئڈW’cپuƒuƒ‰ƒ“ƒhپEƒWƒƒƒpƒ“ٹé‰وˆدˆُ‰ïپv‚ًگف’u‚µ‚ؤ‚¢‚éپB‚»‚µ‚ؤپAپg‹¤•ھژUچ\‘¢•ھگحپi*پjپh‚ئ‚¢‚¤چ‚“x‚ب•ھگحژè–@‚ًٹˆ—p‚µ‚ؤپAƒuƒ‰ƒ“ƒh‚ج‘چچ‡—ح‚ًŒˆ‚ك‚é—vˆِپiˆِژqژwگ”پj‚ً“ء’肵پAƒ‚ƒfƒ‹‰»‚µ‚ؤ‚¢‚邱‚ئ“_‚ھ“ء’¥‚ئ‚¢‚¦‚éپB پ@ƒuƒ‰ƒ“ƒhپEƒWƒƒƒpƒ“‚ھژہژ{‚·‚éپg‹¤•ھژUچ\‘¢•ھگحپh‚إ‚حپABtoC•ز‚ة‚¨‚¢‚ؤ‚حپuƒtƒŒƒ“ƒhƒٹپ[پiگe‚µ‚فپjپvپuƒCƒmƒxپ[ƒeƒBƒuپiٹvگVپjپvپuƒAƒEƒgƒXƒ^ƒ“ƒfƒBƒ“ƒOپi‘ى‰zپjپvپuƒRƒ“ƒrƒjƒGƒ“ƒgپi•ض—کپjپv‚ئ‚¢‚¤4‚آ‚جگِچف•دگ”پABtoB•ز‚ة‚¨‚¢‚ؤ‚حپuگeکa—حپvپuگM—p—حپvپuٹˆ—حپvپuگوŒ©—حپvپuگlچق—حپv‚ئ‚¢‚¤5‚آ‚جگِچف•دگ”‚ً”؛‚¤‰¼گà‚ً—§‚ؤپA‚±‚ê‚ة‚µ‚½‚ھ‚ء‚ؤپA’²چ¸‚ًگفŒvپA•ھگح‚ًچs‚¤‚ئ‚¢‚¤“ئژ©‚ج’²چ¸ژè–@‚ًٹm—§‚µ‚ؤ‚¢‚éپB
پ@âV“،ژپ‚حپA‚±‚جƒ‚ƒfƒ‹‰»‚³‚ꂽƒuƒ‰ƒ“ƒh•]‰؟ƒpƒXگ}‚جˆس‹`‚ًژں‚ج‚و‚¤‚ةŒê‚éپB
پuƒuƒ‰ƒ“ƒh‰؟’l‚ً“¾“_‰»‚إ‚«‚éˆê•ûپA1‚آ‚جƒuƒ‰ƒ“ƒh‚ة‚آ‚¢‚ؤƒuƒ‰ƒ“ƒh‰؟’l‚جچ\‘¢‚ً‚±‚جƒ‚ƒfƒ‹‚إ–¾‰ُ‚ةژ¦‚·‚±‚ئ‚ھ‚إ‚«‚é‚ج‚إپAƒ†پ[ƒUپ[‚©‚ç‚حپAپw—‰ً‚µ‚â‚·‚¢پxپwژ©ژذƒuƒ‰ƒ“ƒh‚ج‚ا‚±‚ة–â‘è‚ھ‚ ‚é‚©‚ھپA–¾ٹm‚ة‚ي‚©‚éپx‚ئ‚¢‚ء‚½•]‰؟‚ً‚¢‚½‚¾‚¢‚ؤ‚¢‚ـ‚·پv پ@‚µ‚©‚µپAâV“،ژپ‚ة‚و‚ê‚خپA’²چ¸‚ًڈd‚ث‚é‚ة‚آ‚êپAƒ†پ[ƒUپ[‚جˆسŒ©پE—v–]‚ح–¾‚ç‚©‚ة•د‰»‚µ‚ؤ‚«‚ؤ‚¢‚éپA‚ئ‚¢‚¤پB
پu‘O‰ٌ‚ـ‚إ‚حپA‘چچ‡—ح‚ھ‰½“_‚إڈ‡ˆت‚ح‰½ˆت‚إ‚ ‚èپA‚»‚جŒ´ˆِ‚ئ‚µ‚ؤ‚حپA‚±‚جˆِژqژwگ”‚ھ‚±‚¤‚¾‚ء‚½‚©‚ç‚إ‚·پA‚ئ‚¢‚ء‚½گà–¾‚إپA‚¨‹q—l‚ح‚ظ‚ع–‘«‚³‚ê‚ؤ‚¢‚ـ‚µ‚½پB‚ئ‚±‚ë‚ھپA2‰ٌ–ع‚ج’²چ¸Œ‹‰ت‚ة‘خ‚µ‚ؤ‚حپAپwƒCƒپپ[ƒW‚ًŒüڈم‚·‚邽‚ك‚ة‚حپA‹ï‘ج“I‚ة‚ا‚¤‚µ‚½‚ç‚¢‚¢‚ج‚©پxپwPR‚ة‚ح’چ—ح‚µ‚ؤ‚«‚½‚آ‚à‚肾‚ء‚½‚ج‚ةپA‚ب‚؛پA‚±‚ٌ‚ب’ل‚¢Œ‹‰ت‚ة‚ب‚é‚ج‚©‚ي‚©‚ç‚ب‚¢پx‚ئ‚¢‚ء‚½پA‚و‚èگ[‚¢•ھگح‚ً•K—v‚ئ‚·‚é‚و‚¤‚بژ؟–â‚âˆسŒ©‚ھ‘½‚‚ب‚ء‚ؤ‚«‚ـ‚µ‚½پv
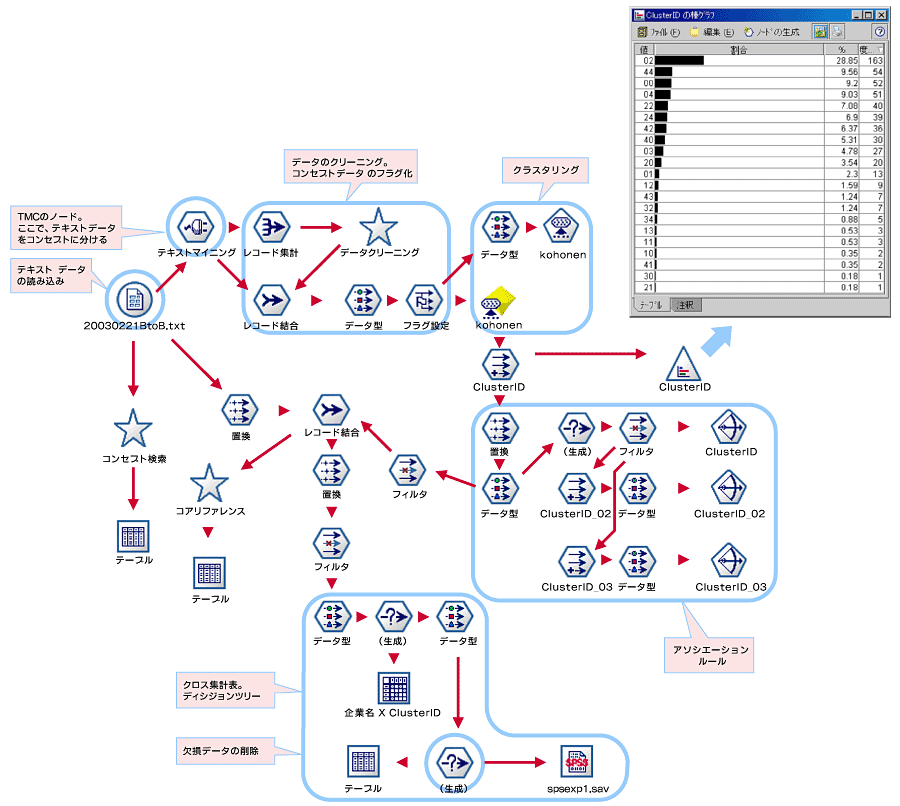
پ@‚±‚¤‚µ‚½ƒ†پ[ƒUپ[‚جگ؛‚ح‘و2‰ٌ‚ـ‚إ‚ة‚à‚¢‚‚آ‚©ٹٌ‚¹‚ç‚ê‚ؤ‚¨‚èپAچ،Œم‚و‚葽‚‚جƒ†پ[ƒUپ[‚©‚ç‚à“¯—l‚جگ؛‚ھٹٌ‚¹‚ç‚ê‚邱‚ئ‚ھ—\‘ھ‚³‚ꂽ‚½‚كپA‰½‚ç‚©‚جگV‚½‚ب•ھگحژè–@‚ض‚جژو‚è‘g‚ف‚ھ•K—v‚¾پA‚ئٹ´‚¶‚é‚و‚¤‚ة‚ب‚ء‚½‚ئ‚¢‚¤پB پ@‚»‚±‚إپAپuƒuƒ‰ƒ“ƒhپEƒWƒƒƒpƒ“ 2003پv‚ج’²چ¸‚إ‚حپAƒCƒ“ƒ^پ[ƒlƒbƒg’²چ¸‚ج‰ٌ“ڑƒtƒHپ[ƒ€‚ةپAگV‚½‚ةژ©—R‰ٌ“ڑ—“‚ًگف‚¯‚½‚»‚¤‚¾پB‘I‘ًژˆ‚©‚ç‰ٌ“ڑ‚ً‘I‚ش‚¾‚¯‚إ‚ب‚پAژ©—R‚ة‹Lڈq‚µ‚ؤ‚à‚炤‚±‚ئ‚ة‚و‚ء‚ؤپA‰ٌ“ڑژز‚جگ¶‚جگ؛‚ئ‚¢‚¤’èگ«“I‚بƒfپ[ƒ^‚ًژûڈW‚µپA•ٌچگڈ‘‚ة“Y•t‚·‚éCD-ROM‚ةژûک^‚µ‚½پB‚½‚¾‚µپAچ،‰ٌ‚حƒeƒLƒXƒgƒ}ƒCƒjƒ“ƒO‚جŒ‹‰ت‚ً•ٌچگڈ‘‚ةگ·‚èچ‚ٌ‚إ‚ح‚¢‚ب‚¢پBژژŒ±“I‚ةژ©—R‰ٌ“ڑƒfپ[ƒ^‚ج•ھگح‚ًچs‚¢پAچ،Œم‚جƒeƒLƒXƒgƒ}ƒCƒjƒ“ƒOٹˆ—p‚ج‰آ”\گ«‚ً’T‚邱‚ئ‚ھ–ع“I‚¾‚ء‚½‚ئ‚¢‚¤‚±‚ئ‚¾پB پ@ژہچغ‚ج•ھگحچى‹ئ‚ة‚¨‚¢‚ؤ‚حپASPSS‚جپuText Mining for Clementineپv‚ئ‚¢‚¤ƒcپ[ƒ‹‚ً—p‚¢‚½ƒeƒLƒXƒgƒ}ƒCƒjƒ“ƒO‘S”ت‚ةٹض‚ي‚éƒRƒ“ƒTƒ‹ƒeƒBƒ“ƒO‚ئ‚µ‚ؤپASPSS‚©‚ç‚ج‘S–ت“I‚ب‹¦—ح‚ً“¾‚½‚ئ‚¢‚¤پBâV“،ژپ‚ئ‹¤“¯‚إ•ھگحچى‹ئ‚ًگi‚ك‚½‚ج‚حپASPSS ƒvƒچƒtƒFƒbƒVƒ‡ƒiƒ‹ƒTپ[ƒrƒXƒOƒ‹پ[ƒv ƒVƒjƒAƒRƒ“ƒTƒ‹ƒ^ƒ“ƒg گى“ˆ“ضژqژپ‚إ‚ ‚éپBگى“ˆژپ‚حپAƒeƒLƒXƒgƒ}ƒCƒjƒ“ƒO‚ة‚و‚é•ھگح‚ً—p‚¢‚½”ژژmک_•¶‚ً’ٌڈoپAڈî•ٌƒRƒ~ƒ…ƒjƒPپ[ƒVƒ‡ƒ“‚ج”ژژmچ†‚ً—L‚·‚éپA‚¢‚ي‚خپAƒeƒLƒXƒgƒ}ƒCƒjƒ“ƒO‚جژہ‘HŒoŒ±ژز‚إ‚ ‚éپB
پ@ژ©—R‰ٌ“ڑƒfپ[ƒ^‚ً•ھگح‚·‚邽‚ك‚ة‚حپA‚ـ‚¸پA•¶ڈح‚ًپuƒRƒ“ƒZƒvƒgپv’Pˆت‚ـ‚إچוھ‰»‚·‚é•K—v‚ھ‚ ‚éپBƒRƒ“ƒZƒvƒg‚ئ‚حپAˆس–،‚ج‚ ‚郌ƒxƒ‹‚إ’PŒê‚ًٹ‡‚ء‚½‚à‚ج‚إ‚ ‚èپA‚±‚جƒRƒ“ƒZƒvƒg‚ً’ٹڈo‚إ‚«‚é“_‚ھپuText Mining for Clementineپv‚ج‚à‚ء‚ئ‚à—D‚ꂽ‹@”\‚ج1‚آ‚إ‚ ‚éپB پ@•¶ڈح‚ً•ھ‰ً‚·‚éژè–@‚ئ‚µ‚ؤ‚حپAŒ`‘ش‘f‰ًگح‚ئ‚¢‚¤‚â‚è•û‚à‚ ‚éپB‚µ‚©‚µپA‚±‚ê‚حپA•¶ڈح‚ًچإڈ¬‚ج’Pˆت‚إ‚ ‚éپu•iژŒپv‚ة‚ـ‚إ•ھ‚¯‚ؤ‚µ‚ـ‚¤‚½‚كپAپu•iژŒپv‚P‚آ‚P‚آ‚©‚çپA‚ـ‚ئ‚ـ‚ء‚½ˆس–،‚ً‹‚‚فژو‚邱‚ئ‚حچ¢“ï‚إ‚ ‚éپB—ل‚¦‚خپAŒ`‘ش‘f‰ًگحƒcپ[ƒ‹‚إ‚ ‚éپu’ƒâ£پv‚ئپuText Mining For Clementineپv‚إ“¯ˆê‚ج•¶ڈح‚ً‰ًگح‚µ‚½ڈêچ‡‚جŒ‹‰ت‚ً”ن‚ׂؤ‚ف‚و‚¤پB
پ@پu’ƒâ£پv‚إ‚حپAپu‹ê‚¢ƒrپ[ƒ‹پv‚ئ‚¢‚¤ƒtƒŒپ[ƒY‚ھپu‹ê‚¢پv‚ئپuƒrپ[ƒ‹پv‚ئ‚¢‚¤2‚آ‚ج’PŒê‚ة•ھ‰ً‚³‚ê‚ؤ‚µ‚ـ‚¤‚½‚كپA–{—ˆ“`‚¦‚½‚¢پu‚ة‚ھ‚ف‚ج‚ ‚éƒrپ[ƒ‹پv‚ئ‚¢‚¤ˆس–،‚ً1‚آ1‚آ‚ج’PŒê‚¾‚¯‚©‚ç”»’f‚·‚邱‚ئ‚ح“‚‚ب‚ء‚ؤ‚µ‚ـ‚¤پB‚µ‚©‚µپAپuText Mining For Clementineپv‚إ‚ ‚ê‚خپAپu‹ê‚¢ƒrپ[ƒ‹پv‚ئ‚¢‚¤‚ذ‚ئ‚‚‚è‚ج’PŒê‚ة•ھ‰ً‚³‚ê‚é‚ج‚إپA‚»‚ꂾ‚¯‚إڈ\•ھˆس–،‚ھ’ت‚¶‚éپB‚±‚ج‚±‚ئ‚©‚炾‚¯‚إ‚àپAƒRƒ“ƒZƒvƒg’ٹڈo‚ھƒeƒLƒXƒgƒ}ƒCƒjƒ“ƒO‚ة‚¨‚¢‚ؤپA‚¢‚©‚ةڈd—v‚ب‹@”\‚©‚ھ‚¨•ھ‚©‚è‚¢‚½‚¾‚¯‚邾‚낤پB پ@SPSS‚جClementine‚ة‚حپACEMIپiClementine External Module Interfaceپj‚ج‹@”\‚ًٹˆ—p‚µ‚ؤƒeƒLƒXƒgƒ}ƒCƒjƒ“ƒOƒcپ[ƒ‹پuText Mining for Clementineپv‚جƒmپ[ƒh‚ً‘g‚فچ‚ق‚±‚ئ‚ھ‚إ‚«‚éپB‚ـ‚½پAپu’ƒâ£پv‚ًƒCƒ“ƒXƒgپ[ƒ‹‚µپA“¯‚¶‚CEMI‚ًژg‚ء‚ؤپu’ƒâ£پv‚ًپuClementineپv‚جƒmپ[ƒh‚ئ‚µ‚ؤ‘g‚فچ‚ق‚±‚ئ‚à‰آ”\‚¾پB‚»‚µ‚ؤپAƒOƒ‰ƒtƒBƒJƒ‹‚إژg‚¢‚â‚·‚¢پuClementineپvڈم‚إپA–ع“I‚ة‰‚¶‚ؤ—¼ژز‚ًژ©—Rژ©چف‚ةژg‚¢•ھ‚¯‚ب‚ھ‚ç•ھگح‚ًگi‚ك‚邱‚ئ‚ھ‚إ‚«‚éپBچ،‰ٌ‚ج•ھگح‚إ‚حپAپu’ƒâ£پv‚ة‚و‚éŒ`‘ش‘f‰ًگح‚ة‚و‚èپAژ©—R‰ٌ“ڑƒfپ[ƒ^‚ج‘چ’PŒêگ”‚â“®ژŒپA•›ژŒپAŒ`—eژŒ‚ب‚اپAٹe•iژŒ‚جڈoŒ»•p“xگ”‚ب‚ا‚جٹî–{“I‚ب•ھگح‚ًچs‚¢پA‚³‚ç‚ةپuText Mining For Clementineپv‚ة‚و‚éƒRƒ“ƒZƒvƒg’ٹڈo‚ة‚و‚ء‚ؤپA•ھگحگ¸“x‚ًچ‚‚ك‚½‚»‚¤‚¾پB پ@•¶ڈح‚©‚çƒRƒ“ƒZƒvƒg‚ً’ٹڈo‚µ‚½‚ج‚؟پA1‰ٌ‚µ‚©ڈoŒ»‚µ‚ب‚¢’PŒê‚âپA•ھگح‚ة’l‚µ‚ب‚¢‚ئژv‚ي‚ê‚é•s—v‚بƒfپ[ƒ^‚ً”rڈœ‚·‚éپAƒfپ[ƒ^ƒNƒٹپ[ƒjƒ“ƒO‚ًٹ®—¹‚·‚ê‚خپA’تڈي‚ج’è—تƒfپ[ƒ^‚ج•ھگح‚ئ“¯—l‚ةپuClementineپvڈم‚إ‚³‚ـ‚´‚ـ‚بƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO‚ً—eˆص‚ةچs‚¤‚±‚ئ‚ھ‚إ‚«‚éپB‚µ‚©‚µپA•ھگحŒ‹‰ت‚ً“¾‚½Œم‚إ‚ ‚ء‚ؤ‚àپA•ھگحƒvƒچƒZƒX‚ً‚³‚©‚ج‚ع‚èپAƒfپ[ƒ^ƒNƒٹپ[ƒjƒ“ƒO‚©‚ç‚â‚è’¼‚·‚±‚ئ‚à‚و‚‚ ‚é‚炵‚¢پB‚±‚ج“_‚ة‚آ‚¢‚ؤپAگى“ˆژپ‚حچ،‰ٌ‚ج•ھگح‚ًگU‚è•ش‚ء‚ؤژں‚ج‚و‚¤‚ةکb‚µ‚ؤ‚‚ꂽپB پ@پuچ،‰ٌ‚ج•ھگح‚إ‚حپA•ھگحŒ‹‰ت‚ً’‚كپA‚±‚جƒRƒ“ƒZƒvƒg‚ًڈœٹO‚µ‚½‚ç‚ا‚¤‚ب‚é‚©‚ئ‰¼گà‚ً—§‚ؤ‚ؤپAƒfپ[ƒ^ƒNƒٹپ[ƒjƒ“ƒO‚©‚ç‚â‚è’¼‚·پA‚ئ‚¢‚¤•ھگحƒvƒچƒZƒX‚ًŒJ‚è•ش‚µچs‚¤‚±‚ئ‚ة‚و‚ء‚ؤپA•ھگحŒ‹‰ت‚جگ¸“x‚ھ‘ه‚«‚Œüڈم‚µ‚ؤ‚¢‚«‚ـ‚µ‚½پBپgClementineپh‚جڈêچ‡پAپwƒXƒgƒٹپ[ƒ€پx‚ئ‚¢‚¤–ع‚ةŒ©‚¦‚éŒ`‚إ•ھگحƒچƒWƒbƒN‚ً’ا‚¤‚±‚ئ‚ھ‚إ‚«‚ـ‚·‚µپAٹeƒmپ[ƒh‚إ‚ا‚ٌ‚بچى‹ئ‚ًچs‚ء‚½‚ج‚©‚ً‚¢‚آ‚إ‚àٹm”F‚·‚邱‚ئ‚ھ‚إ‚«‚ـ‚·پB‚µ‚½‚ھ‚ء‚ؤپAژژچsچِŒë“I‚ة•ھگحƒvƒچƒZƒX‚ًŒJ‚è•ش‚·ڈêچ‡‚إ‚àپA‰ك‹ژ‚جچى‹ئ“à—e‚ًٹm”F‚µ‚ب‚ھ‚çگi‚ك‚邱‚ئ‚ھ‚إ‚«پAŒّ—¦“I‚ة•ھگح‚ًگi‚ك‚邱‚ئ‚ھ‚إ‚«‚ـ‚µ‚½پv پ@•ھگحƒvƒچƒZƒX‚»‚ج‚à‚ج‚ً–ع‚ةŒ©‚¦‚éŒ`‚إ•غ‘¶‚·‚é‚ئ‚¢‚¤پuClementineپv‚ج“ء’¥‚ة‚آ‚¢‚ؤ‚حپAâV“،ژپ‚àچ‚‚•]‰؟‚µ‚ؤ‚¢‚é‚و‚¤‚¾پB‹¤“¯‚إچى‹ئ‚ًگi‚ك‚é‚ة‚ ‚½‚ء‚ؤپAگى“ˆژپ‚ھ‚ا‚ج‚و‚¤‚بƒچƒWƒbƒN‚إ•ھگح‚ًگi‚كپA‹ï‘ج“I‚ة‚ا‚ج‚و‚¤‚بچى‹ئ‚ًچs‚ء‚½‚ج‚©‚ًٹm‚©‚ك‚ب‚ھ‚çپA—‰ً‚·‚邱‚ئ‚ھ‚إ‚«‚½‚ئ‚¢‚¤پB
پ@چ،‰ٌ‚ج•ھگح‚إ‚حپAKohonenƒlƒbƒgƒڈپ[ƒNپi**پj‚ة‚و‚éƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚ًچs‚¢پAˆب‰؛‚ج‚و‚¤‚بƒNƒ‰ƒXƒ^‚ً“¾‚½پB
‚³‚ؤپA‚»‚ꂼ‚ê‚جƒNƒ‰ƒXƒ^‚ة—^‚¦‚ç‚ꂽ–¼ڈج‚ً’‚ك‚ؤ‚ف‚ؤ—~‚µ‚¢پBژ@‚µ‚ج‚و‚¢•û‚إ‚ ‚ê‚خپA‚·‚إ‚ة‚¨‹C‚أ‚«‚©‚à‚µ‚ê‚ب‚¢‚ھپAٹùڈo‚جBtoB•ز‚جƒuƒ‰ƒ“ƒh•]‰؟ƒpƒXگ}‚ً‚ظ‚¤‚س‚آ‚³‚¹‚é‚à‚ج‚إ‚ ‚é‚ئ‚¢‚¦‚邾‚낤پB‚آ‚ـ‚èپAچ،‰ٌ‚جƒeƒLƒXƒgƒ}ƒCƒjƒ“ƒO‚ة‚و‚éژ©—R‰ٌ“ڑƒfپ[ƒ^•ھگح‚جŒ‹‰ت‚ة‚و‚èپAپuƒuƒ‰ƒ“ƒhپEƒWƒƒƒpƒ“پv‚ھٹˆ—p‚µ‚ؤ‚¢‚éƒuƒ‰ƒ“ƒh‰؟’l‚جچ\‘¢ƒ‚ƒfƒ‹پuƒuƒ‰ƒ“ƒh•]‰؟ƒpƒXگ}پv‚ج‘أ“–گ«‚ھŒںڈط‚إ‚«‚½‚ئŒ¾‚¢ٹ·‚¦‚邱‚ئ‚ھ‚إ‚«‚éپB
پ@ƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO‚ة‚¨‚¢‚ؤˆê”ت“I‚ب–@‘¥‚ً“±‚±‚¤‚ئ‚·‚éڈêچ‡پA‰پX‚ة‚µ‚ؤڈ¬گ”ˆسŒ©‚ح”rڈœ‚³‚ê‚éŒXŒü‚ة‚ ‚éپBچ،‰ٌژژ‚ف‚ç‚ꂽƒeƒLƒXƒgƒ}ƒCƒjƒ“ƒO‚إ‚àپA‚±‚ج‚و‚¤‚بڈˆ—•û–@‚ح’èگخ‚إپAژ©—R‰ٌ“ڑƒfپ[ƒ^‚©‚çƒRƒ“ƒZƒvƒg‚ً’ٹڈo‚µپAƒfپ[ƒ^ƒNƒٹپ[ƒjƒ“ƒO‚ًچs‚¤چغ‚ةپA1‰ٌ‚µ‚©ڈoŒ»‚µ‚ب‚¢’PŒê‚حڈœٹO‚µ‚½‚»‚¤‚¾پB پ@‚µ‚©‚µپA‚±‚¤‚µ‚½’ل•p“x’PŒê‚ة‚آ‚¢‚ؤپAگى“ˆژپ‚حˆسٹO‚ب”Œ©‚ً‚µ‚½‚ئ‚¢‚¤پB‚³‚ـ‚´‚ـ‚ب’ل•p“x’PŒê‚إŒ`—e‚³‚ꂽƒuƒ‰ƒ“ƒh‚ھ‚ ‚é‚©‚ئژv‚¦‚خپA’ل•p“x’PŒê‚ھ‚»‚ê‚ظ‚اڈoŒ»‚µ‚ب‚¢ƒuƒ‰ƒ“ƒh‚ھ‚ ‚ء‚½‚ئ‚¢‚¤‚ج‚¾پBگى“ˆژپ‚حپA‚±‚ج“_‚ة‚آ‚¢‚ؤژں‚ج‚و‚¤‚ةŒê‚éپB
پu‚³‚ـ‚´‚ـ‚بŒ¾—t‚إŒ`—e‚³‚ê‚ؤ‚¢‚éƒuƒ‰ƒ“ƒh‚حپA“¯‚¶‚و‚¤‚بŒ¾—t‚إŒê‚ç‚ê‚ؤ‚¢‚éƒuƒ‰ƒ“ƒh‚ئ”نٹr‚·‚ê‚خپA‚و‚葽—l‚ب•]‰؟‚ًژَ‚¯‚ؤ‚¢‚éپA‚آ‚ـ‚èپwکb‘èگ«پx‚ًژ‚ء‚ؤ‚¢‚é‚ئچl‚¦‚ç‚ê‚é‚ج‚إ‚ح‚ب‚¢‚إ‚µ‚ه‚¤‚©پB‚µ‚½‚ھ‚ء‚ؤپA’ل•p“x‚ج’PŒê—ت‚ة’…–ع‚µپAپwˆظ‚ب‚èŒêپx‚ھ‚ا‚ج‚‚ç‚¢ٹـ‚ـ‚ê‚é‚©‚ئ‚¢‚¤‚±‚ئ‚ً’²‚ׂ邱‚ئ‚ة‚و‚ء‚ؤپA—ل‚¦‚خپAƒuƒ‰ƒ“ƒh‚جپwکb‘èگ«پx‚ً‘ھ‚邱‚ئ‚ھ‚إ‚«‚é‚©‚à‚µ‚ê‚ـ‚¹‚ٌپB‹ï‘جگ«پE‘½—lگ«‚ًژ¦‚·ژw•W‚ئ‚µ‚ؤپA’ل•p“xŒê‚ج•ھگحژè–@‚ًٹm—§‚µ‚ؤ‚¢‚¯‚ê‚خ‚ئچl‚¦‚ؤ‚¢‚ـ‚·پv پ@ˆê•ûپAâV“،ژپ‚حچ،‰ٌ‚ج•ھگح‚ً’ت‚¶پAƒuƒ‰ƒ“ƒh•]‰؟’²چ¸‚ةƒeƒLƒXƒgƒ}ƒCƒjƒ“ƒO‚ًٹˆ—p‚·‚邱‚ئ‚ض‚ج‰آ”\گ«‚ً‹‚ژہٹ´‚µ‚½‚و‚¤‚¾پBپuƒuƒ‰ƒ“ƒhپEƒWƒƒƒpƒ“پv‚جژ©—R‰ٌ“ڑ‚ً‘خڈغ‚ئ‚µ‚½ƒeƒLƒXƒgƒ}ƒCƒjƒ“ƒO‚حپA’è—ت“I‚ب’²چ¸پE•ھگح‚ج—LŒّگ«‚ً— •t‚¯‚邱‚ئ‚ھ‚إ‚«‚½‚¾‚¯‚إ‚ب‚پAژ©—R‰ٌ“ڑƒfپ[ƒ^‚إ‚ ‚é‚ھ‚ن‚¦‚جگV‚½‚ب’mŒ©‚ً“¾‚邱‚ئ‚ھ‚إ‚«‚½پB‚»‚¤‚µ‚½’mŒ©‚ً–c‘ه‚بژ©—R‰ٌ“ڑ‚©‚猩ڈo‚·‚½‚ك‚ة—ح‚ة‚ب‚ء‚ؤ‚‚ê‚é‚ج‚ھپAپuClementineپv‚إ‚ ‚èپAپuText Mining for Clementineپv‚إ‚ ‚éپB‚»‚µ‚ؤپASPSS‚إ‚ح•ھگحƒcپ[ƒ‹‚ج’ٌ‹ں‚¾‚¯‚إ‚ب‚پAگV‚½‚ب•ھگحژè–@‚ًژژ‚ف‚و‚¤‚ئ‚·‚éٹé‹ئ‚ض‚جƒTƒ|پ[ƒg‚ة‚آ‚¢‚ؤ‚àپAگد‹ة“I‚ةژو‚è‘g‚ٌ‚إ‚¢‚éپBژں”N“x‚جپuƒuƒ‰ƒ“ƒhپEƒWƒƒƒpƒ“ 2004پv‚إ‚حپAƒeƒLƒXƒgƒ}ƒCƒjƒ“ƒO‚ة‚و‚éƒuƒ‰ƒ“ƒh•]‰؟Œ‹‰ت‚ھ‚ـ‚ئ‚ك‚ç‚êپA•ٌچگ‚³‚ê‚邱‚ئ‚ًٹْ‘ز‚µ‚½‚¢پB
|
پ@ |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| پ@ | ||
Copyright © ITmedia, Inc. All Rights Reserved.
|