Loading
|
||
|
Loading
|
| �@ |
| �@��IT > �e���o�C�gOK�I ��e�ʃf�[�^�ł������������\�ɂ���XML�f�[�^�x�[�X�uTX1�v |
| �@ |
|
|
| �@ |
�@XML�f�[�^�x�[�X�ւ̗v���͔N�X���܂��Ă���B�ق��̃f�[�^�����Z�p�A�Ⴆ��RDB���g�p���Ă���肭�����ł��Ȃ��j�[�Y������A����ɑ��������Ƃ���XML�f�[�^�x�[�X�����߂��Ă���B �@�������A���̗v������������Ă������Ƃ����A�K�����������ł͂Ȃ��B�]����XML�f�[�^�x�[�X�ɂ́A�������̖�肪�������B�Ⴆ�A���i�̑I����₪���Ȃ��A�傫�ȃf�[�^�������Ƌɒ[�ɉ������x���Ȃ�A���G�ȃN�G�����d���i�`���[�j���O�ł��Ȃ��j�ȂǁB���ɑ傫�Ȗ��́A���\�Ƃ���邽�߂̃R�X�g�ɂ���Ƃ����Ă����B�܂�A�����ȃf�[�^�A�ȒP�ȃN�G���̏ꍇ�͂��܂����삷��XML�f�[�^�x�[�X�ł����Ă��A�傫�ȃf�[�^�A���G�ȃN�G�����g���Ƌɒ[�ɏd���Ȃ�A�����������邽�߂ɂ͊Ǘ��R�X�g�������グ��T�[�o�䐔�̑�����v�������̂��B
�@���̂悤�Ȗ����������邽�߂ɐ��܂ꂽ�̂��A���Ń\�����[�V������XML�f�[�^�x�[�X�uTX1�v�ł���BTX1�́A�e���o�C�g���̃f�[�^�������\�͂����ƂƂ��ɁA���G�ȃN�G����f�������s���邽�߂̐V�@���𓋍ڂ��Ă���B �@�v�V�I�ȃe�N�m���W�𓋍ڂ��Ďs������ꂽTX1�ɂ��āA���� �v���b�g�t�H�[���\�����[�V�������ƕ� ���i��敔 �Q�� �V�������́uTX1�͓��Ђ�����܂łɐςݏグ�Ă������{�ꏈ���A�i���b�W�}�l�W�����g�A�t�@�C���V�X�e���Ǘ��Ƃ��������ЋZ�p�̎��Y���W�听�����Ƃ����鐻�i�ł��v�ƌ��B �@�Ȃ�TX1���e���o�C�g���f�[�^�╡�G�ȃN�G�������������ł���̂��A���̎d�g�݂��ڂ������Ă������B
�@���́AXML�f�[�^�x�[�X�̍������Ƃ͉������l����͓̂���B�Ȃ��Ȃ�AXML�f�[�^�x�[�X�ɗv������錟�������ɂ́A�܂������قȂ鐫��������2�̎�ނ����邽�߂��B1�́AXML�Ȃ�ł̗͂v�f�⑮���Ƃ������\����f������������Z�p�B����1�́A�v�f�⑮���̒l�ƂȂ镶�����f������������Z�p�ł���B�������肷��ƁA�O�҂�����XML�f�[�^�x�[�X�ŏd�v�ȃ|�C���g�ł���Ǝv�������ł��邪�A���p�V�X�e���̃j�[�Y���l����ƌ�҂���������炸�d�v�ł���B�Ⴆ�A�V���L��������̌����Ƃ����V�X�e�����l�����ꍇ�A���͂̒��̓���̒P�����������S�������I�ȃj�[�Y�͓��R�z�肳���B �@����2�̃j�[�Y�������߂ɁATX1��XML�I�ȍ\�������łȂ��A���͂ȃt���e�L�X�g�����@�\������Ă���B����́A�ŐV�̃t���e�L�X�g�����Z�p��ɂ��݂Ȃ����������̂ł���B�����āA�������XML�I�ȍ\���̌����������ł���B�������������邽�߂ɐ��ݏo���ꂽ�u2�̐V�@���v�ɂ��ĉ�����悤�B �V�@��1 �g�X�L�[�}�A�i���C�U�h �@�X�L�[�}�A�i���C�U�́u�\���������o�Z�p�v�A�܂�K�w�\���̌��������������邽�߂̋Z�p�ł���B �@XML�̓c���[�\���ł���W��A�������邽�߂ɂ͊K�w�\�������ɂ��ǂ��Ă����Ȃ���Ȃ�Ȃ��B������TX1�ł́A��e�ʃf�[�^�ł��g�K�w�p�^�[���ƍ��h�������ɍs�����߂̓Ǝ��̍����������̗p���Ă���BXML�f�[�^����\���������I�ɒ��o���āA���̂��߂̍������쐬����Z�p���X�L�[�}�A�i���C�U�ł���i�}1�j�B
�@�N�G���́A�X�L�[�}�A�i���C�U���쐬�����\�������ƁA�S�������@�\�iN-gram�����j���쐬�����ꂢ�����ɂ���č����Ɏ��s����A�����Ɏ��Ԃ�������f�[�^�{�̂ւ̎Q�Ƃ͍ŏ����ɗ}�����Ă���B���ꂪ����XML�f�[�^�x�[�X�ւ̕��G�ȃN�G�����������s�ł��闝�R����1�ł���B �V�@��2 �g�N�G���I�v�e�B�}�C�U�h �@�N�G���I�v�e�B�}�C�U�́u�₢���킹�œK���Z�p�v�A�܂蕡�G��XQuery�ł������Ɍ������邽�߂̋Z�p�ł���B �@����ȃf�[�^�x�[�X�ւ̖₢���킹�́A���G�ȃN�G�����v������邱�Ƃ������B�P���ȃN�G���ł͂��܂�ɑ����̃m�[�h���q�b�g���Ă��܂��\�������邽�߁A�K�R�I�ɃN�G���̏����͕��G������B�������AXML�̕W���₢���킹����XQuery�͕��G�Ȗ₢���킹�������\�ł��邪�A����̓N�G���̎��s�v�掟��Ō��I�ɑ��x���ς��ꍇ������B�N�G���������Ɏ��s���邽�߂ɁA���o�����\���ƌꂢ�̓��v�����q���g�ɁA�œK�Ȗ₢���킹�v����������Z�p���A�N�G���I�v�e�B�}�C�U�ł���i�}2�j�B
�@�}2�̗�ł́A�N�G����2�̏�����t���Ă���B�ǂ���̏������Ɍ������Ă����ʂ͓��������A��Ɍ�₪���Ȃ������ׂ�ƁA�ォ�珈������������`�F�b�N����Ώۂ����Ȃ��Ȃ�A���Z�����Ԃŏ����������ł���B�܂�A�uXML�v���ɒ��ׂ�����A�u��܃^�O�v���ɒ��ׂ�����A�S�̂Ƃ��đ����Ȃ�Ƃ������Ƃł���B���̂悤�ȃN�G���̍œK���́A����f�[�^�x�[�X�ł͓��ɗL����������B���ꂪ����XML�f�[�^�x�[�X�ւ̕��G�ȃN�G�����������s�ł��闝�R����2�ł���B
�@�ł́A�����̋Z�p�����p������̓I�Ȑ��\�͂ǂ̒��x�Ȃ̂��낤���B�ȉ��ɓ��������̌�����XMark�̃x���`�}�[�N�̌��ʁi�ǂ�������Ń\�����[�V�����v���j���������B
���������̌��� �@���̃x���`�}�[�N�́A���p�f�[�^���������ꍇ�̐��\�����邱�Ƃ��Ӑ}���Ă���B���̂��߁A���ۂ̓������J����̖�8�N���A��300�������i��100Gbytes�j��ΏۂƂ��Ă���i�ߋ���SGML�`���̌����XML�`���ɕϊ����Ă���o�^���Ă���j�B
�@�����ł́A���p�f�[�^��XML�I�\���╶����ɑ��镡���I�ȃN�G�����f�������s����Ă��邱�Ƃɒ��ڂ��悤�B XMark �@���̃x���`�}�[�N�́A���J���ꂽ�W���I�ȏ����ł̐��\�����邱�Ƃ��Ӑ}���Ă���B���̂��߁AXQuery�ɂ��₢���킹�̃x���`�}�[�N�ł���XMark���g�p���Ă���i�C���^�[�l�b�g�I�[�N�V���������f���Ƃ���f�[�^�j�B
�@�ȒP�ȃN�G���ł͑��А��i�ł������x�̐��\�ł��邪�ATX1�͕��G�ȃN�G���ł����p�����̉������ԂŌ��ʂ��o�����Ƃ��ł��Ă���B����͑��А��i�Ɣ�r���āA���{�ȏ�̐��\�ł���B �@�ȏ�̂悤�ɁATX1�͒P�Ƀe���o�C�g���̋���ȃf�[�^�x�[�X�������|�e���V���������Ƃ��������łȂ��A����ȃT�C�Y�Ɍ������������ȃN�G�������s�ł���\�͂������Ă��邱�Ƃ�������B
�@TX1�����s���邽�߂ɓ����OS��n�[�h�E�F�A�͕K�v�Ƃ���Ȃ��BTX1�́AWindows�ł̂ق��ɁASolaris�ł��������\�肳��Ă���B�܂��AJava�AC++�AVisual Basic�Ȃǂ��g�p���ĉ��p�\�t�g���J�����邱�Ƃ��ł���B�₢���킹����Ƃ��ẮAXML�f�[�^�x�[�X�̕W���Ƃ�������XQuery���T�|�[�g����ق��AJDBC�AODBC���x�[�X�ɂ����Ǝ�API���T�|�[�g���Ă���B
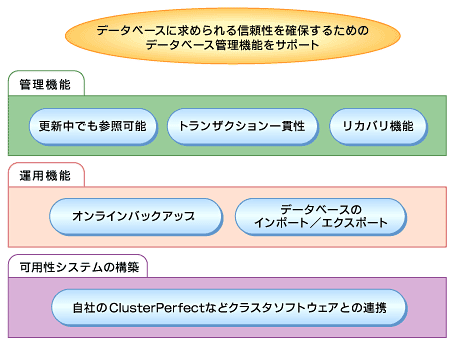
�@�@�\�A���\�ʂ͂��Ƃ��A�Ǘ��@�\�E�^�p�@�\�����ɍ����i�}3�j�B�܂��ɐ^�̎��pXML�f�[�^�x�[�X�ƌĂԂɂӂ��킵�����e�ł���B
�@���ڂ��ׂ��_�́A���͐��\�̍��������ł͂Ȃ��BTX1�́A���Ń\�����[�V�������g�̂��q�l�̃j�[�Y�ɉ����邽�߂ɊJ�������\�t�g�ł���Ƃ����������A���ڂ��ׂ��_�ł���B�V���A���Z�i�ی��̖Ȃǁj�A�s���i�����Ȃǁj�A�����i��Ɠ��R���e���c�̈ꌳ�Ǘ��Ȃǁj�Ƃ��������Ń\�����[�V�����̌ڋq�Ɩ��͑�e�ʂ�XML����������j�[�Y������Ă����B����������邽�߂ɐ��ݏo���ꂽ�\�t�g�́A�܂��Ɍ��ꃌ�x���Ŗ𗧂��p���̍����\�t�g�ł���B �@�e���o�C�g���Ƃ����L���p�V�e�B�͈ꌩ���ċ���V�X�e����p�\�t�g�̂悤�Ɍ����邪�A�����ł͂Ȃ��B�e���o�C�g���Ƃ������t�́A���Ȃ��f�[�^�ʂ̃V�X�e���Ŏg�p�����ꍇ�́A�f�[�^�ʂ��������ꍇ�ł��Ή��ł���Ƃ������S����^���Ă����B�����āA����1�����Ƃ��Ȃ��̂��A1��̃T�[�o�ɋ����XML�f�[�^�������\�͂�^���邱�ƂŁA�T�[�o�䐔�̏��Ȃ��V�X�e�����\�Ƃ��邱�Ƃł���B����ɂ��A�n�[�h�E�F�A�ւ̏o���}���ł��A����ɊǗ��R�X�g�̍팸���B���ł���B���������V�X�e�����x���ł̃R�X�g�p�t�H�[�}���X���A�b�v�����邱�Ƃ��ATX1�̓����Ƃ�����B �@�����A�����XML�f�[�^�x�[�X�����p����ŏ��̈���ݏo�������͂ł����BXML�f�[�^�x�[�X�̗̍p�����߂炤���R�͂������݂��Ȃ��̂ł͂Ȃ����낤���H �F���Ń\�����[�V�����������
���F�A�C�e�B���f�B�A �c�Ƌ� ����F��IT �ҏW�� �f�ړ��e�L�������F2005�N9��30�� |
�@ |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| �@ | ||
Copyright © ITmedia, Inc. All Rights Reserved.
|


.gif)