前編では、SSL/TLSプロトコルを規定する基本コンセプトと、そこに含まれる各構成要素の機能概要を見てきた。難解なイメージのあるSSL/TLSだが、その根底に流れるアイデアは、理解が容易なシンプルなものであることは感じていただけたと思う。そうやって全体的な構造が把握できたところで、いよいよこの後編でSSL/TLSの核心部分である暗号化技術に関する内容に踏み込んでゆく。前回同様、可能な限り噛み砕いて分かりやすい説明を心がけてゆくので、最後までじっくりお付き合い願いたい。
Recordレイヤ内部で起きていること
前回の「暗号化パラメータとHandshake Protocol」のセクションでは、通信に先立ってHandshake Protocolで暗号化パラメータを決定し、そのパラメータに従ってRecord Protocolが機能する様子を説明した。Record Protocolは、主にデータの圧縮と暗号化をつかさどっていて、ほかのプロトコルはRecord Protocolを利用して通信相手とデータをやりとりする。いってみれば、SSL/TLSにおける通信基盤のような位置付けである。
Record Protocolを使って、実際に圧縮・暗号化が提供される部分は、Recordレイヤと呼ばれている。後編のはじめは、まずこのRecordレイヤ内部で行われていることを調べてゆき、そこからSSL/TLSで行われるデータ圧縮・暗号化の具体的な姿を追いかけてみよう。
ここで1つ留意しておいていただきたい点がある。それは、ここでのRecordレイヤの説明が、あくまでもRecordレイヤ内部の話を取り扱っているという点だ。
説明では、ブラックボックスであるはずのレイヤ内部をさらに複数の構成要素に分けて、各構成要素間で行き交うデータを構造体(特定のフォーマットに整形されたデータ群)として明示的に記述している。このようにデータ構造が明示されると、なんらかの形で観察できると誤解しがちだ。しかし、これらの構造体はあくまでもレイヤ内部データであって、一部を除いて、外部とやりとりされることはない。説明を読み進めるにあたっては、この点を誤解しないよう注意を払っておいていただくといい。
また実際の通信では、上位プロトコルからのメッセージが、Recordレイヤを介してネットワークに送出されるデータのほかに、ネットワークからのデータが、Recordレイヤを介して上位プロトコルに届けられるデータが存在する。だが、ここでは主に上位プロトコルからのデータをRecordレイヤで取り扱うケースで説明してゆくことにする。
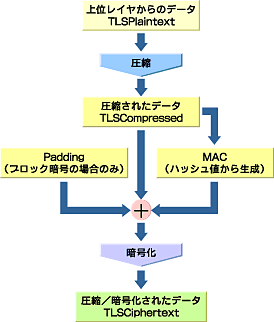
では本題に移ろう。図10はRecordレイヤの動作を模式的に表したものだ。ここでは上位レイヤのメッセージを通信相手に送出するときの動作を示している。
ひとまず大雑把に見ていこう。上位レイヤから受け取ったデータ(TLSPlaintext)は、最初に圧縮されて、圧縮済みデータ(TLSCompressed)が生成される。次に、そのデータに加えて、データのハッシュ値(またはメッセージダイジェスト値)、また暗号アルゴリズムによってはパディング(Padding:穴埋め)がミックスされる。そしてそのデータに暗号化処理を施して、最終的な形である圧縮・暗号化されたデータ(TLSCiphertext)が生成される。ここまでがRecordレイヤの機能である。
こうして生成したデータは、さらにRecordレイヤから下位レイヤ(TCP/IP)に引き渡され、TCPパケット/IPパケットとなってネットワークに送出されてゆく。このときに送出されたパケットをネットワークモニタで観察すると、TCPパケットのデータ部分に、この圧縮・暗号化されたデータ(TLSCiphertext)が含まれていることが観察できる(図11)。図では1TCPパケットに1TLSCiphertext構造体が含まれるように描かれているが、場合によっては1つのTCPパケットに複数のTLSCiphertext構造体が含まれる場合もある。
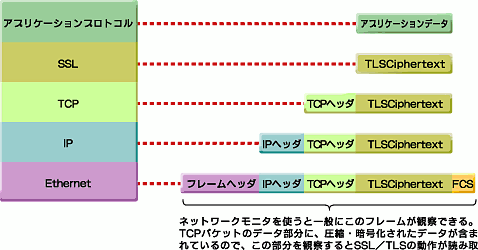
また、このRecord Protocolは、その上位に位置するHandshake Protocol、Alert Protocol、Change Cipher Spec Protocol、Application Data Protocolの各プロトコルが通信基盤として利用している。そのため、TLSPlaintext〜TLSCiphertextの各データには、これら上位プロトコルが取り扱うデータがそれぞれ含まれることになる。具体的に言えば、Handshake Protocolなどによるネゴシエーション情報はもちろん、Application Data Protocolによるアプリケーションデータにいたるまで、いずれも暗号化の対象である。
画面1は実際のやりとりをモニタした様子だ。このTCPパケットには、Change Cipher Spec Protocolのデータと、Handshake Protocolのデータが、それぞれ含まれている。各プロトコルのフォーマットは前編に説明があるので、併せてご覧いただくと内容が把握できると思う。

なお、このモニタ結果では、Change Cipher Spec Protocolのfragment部分はまだ暗号化されていない。これはSSL/TLS通信の初期状態にあり、まだ暗号化パラメータが決定していないためだ。このChange Cipher Spec Protocolメッセージによって暗号化パラメータが確定し、その後のHandshake Protocolからはfragment部分の暗号化が始まっている。読み取る際にはこの点に注意しておこう。
ではここでTLS〜と表されている各構造体の形を詳しく見ておこう。冒頭でも触れたとおり、TLS〜はRecordレイヤ内部でやりとりされるデータの塊である。構造体という言葉は、主にプログラミング言語で使われるもので、単純な型のデータが複数集まって、複雑な情報を構成しているものを指す。ここではデータフォーマットと同意と考えて構わない。
TLSPlaintext
上位プロトコルが通信相手とやりとりするメッセージは、TLSPlaintext構造体としてRecordレイヤに引き渡される。図12にTLSPlaintext構造体の内容を示した。構造体の各フィールドには次のようなものがある。
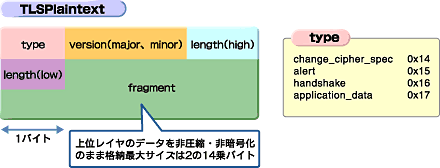
最初のtypeフィールド(1バイト)には上位プロトコルの種別を表す値が入る。具体的な値は、Change Cipher Spec Protocolが0x14、Alert Protocolが0x15、Handshake Protocolが0x16、Application Data Protocolが0x17である。これによって、この構造体に含まれるメッセージが、どの上位プロトコルのものかを表している。
次のversionフィールド(2バイト)には、メジャーバージョン番号(1バイト)とマイナーバージョン(1バイト)番号が、連続して格納される。例えばTLSならメジャーバージョン3、マイナーバージョン1となる。SSL 3.0ならメジャーバージョン3、マイナーバージョン0だ。
その後のlengthフィールド(2バイト)は、続くfragmentフィールドの長さをバイト単位で表した値を格納するフィールドである。fragmentフィールドの長さは一定ではない。そこで、lengthフィールドにその長さが指定されている。2バイトのフィールド中には、長さを表す値の上位バイト、下位バイトの順に格納されてゆく。
最後のfragmentフィールドは上位プロトコルからのデータを収容する部分だ。Recordレイヤで取り扱う上位プロトコルには複数の種類が存在しており、それらのメッセージの中には可変長のものもある。そのため、fragmentフィールドは可変長として定義されている。フィールド長は前出のlengthフィールドに指定する。最大サイズは2の14乗バイトである。
TLSPlaintext構造体では、fragmentフィールドに含まれるデータは、非圧縮・非暗号化のままである。この構造体はRecordレイヤと上位レイヤのインターフェイスに用いられるため、当然といえば当然のことである。Recordレイヤ内部において、このTLSPlaintext構造体を基にして、さまざまな必要な処理を施してゆき、最終的な圧縮・暗号化されたデータを含むTLSCiphertext構造体を生成していくことになる。
TLSCompressed
Recordレイヤ内部では、最初にTLSPlaintextに対してデータの圧縮が施される。そしてその際に使用する圧縮アルゴリズムは、上位レイヤでのネゴシエーションによって決定される。
ここでちょっと混乱してしまいそうなのは、そのネゴシエーションにもRecordレイヤが利用される点だ。卵が先か鶏が先かの問題ではないが、圧縮アルゴリズムを決める際の圧縮アルゴリズムには何が使われるのか、これだけでははっきりしない。そこでSSL/TLSでは、何もネゴシエーションが行われていないまったくの初期状態で使用する圧縮アルゴリズムは、「圧縮アルゴリズムなし(CompressionMethod.null)」と定義している。つまりまったくの初期状態では圧縮を行わずにネゴシエーションを行うのである。そしてその後に、合意した圧縮アルゴリズムの利用が開始されることになる。
こうして決定したアルゴリズムにより、圧縮したデータを格納するのが、図13に示すTLSCompressed構造体だ。
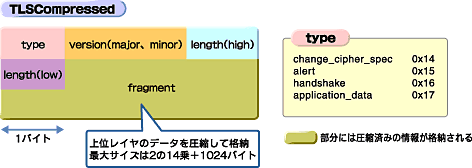
このTLSCompressed構造体の生成は次のように行われる。まずTLSPlaintext構造体の各フィールドは、fragmentを除いてそのままTLSCompressedに写される。また、fragmentフィールドに関しては、TLSPlaintextの内容をネゴシエーションで合意した圧縮アルゴリズムによって圧縮し、それをTLSCompressedのfragmentフィールドに格納する。
この手順からも分かるように、fragmentフィールドを除けば、ほかのフィールドはそのままTLSPlaintextから写されるため、TLSCompressed構造体そのものはTLSPlaintext構造体と大変よく似ていることが見て取れると思う。
唯一異なるframgentフィールドについては、格納可能な最大サイズが2の14乗+1024バイトになるよう定義されている点が異なる。ここで不思議に思われる人もいるだろう。非圧縮データを含むTLSPlaintextのfragmentフィールドの最大サイズが2の14乗なのに、圧縮データを含むTLSCompressedのfragmentフィールドの最大サイズが2の14乗+1024バイトと増えているのはなぜか。
その答えはファイルアーカイバの動作から推測できる。zipでもlhaでもいいのだが、適当なアーカイバを使ってテキストファイルを圧縮して、出来上がったzipファイルなどをさらに圧縮したとする。そこで、圧縮済みファイルと、それを再圧縮したファイルのサイズを比較してみると、圧縮前よりも圧縮後ファイルサイズが大きくなるという、逆転現象が観察されることがある。
これは、情報の圧縮に論理的な限界があるため発生する現象だ。すでに圧縮され、論理的な圧縮限界に達した情報は、それ以上の圧縮ができない。それにもかかわらず再圧縮を行うと、圧縮に関する管理情報や圧縮のための辞書情報(下記の脚注を参照)が付加された分だけ、全体のサイズが再圧縮前より大きくなってしまうのである。
TLSCompressedのfragmentフィールドでも、これと同様のことが考慮されているものと考えればよい。TLSPlaintextのfragmentフィールドは、Application Data Protocolでも利用されている。Application Data Protocolは、アプリケーションがやりとりするデータを透過的に含むため、結果としてfragmentフィールドに圧縮済みデータが含まれることが考えられる。
もし、そこにRecordレイヤでの圧縮処理を適用すると、fragmentフィールドのデータはどうなるだろうか。そう、データの圧縮は行われず、管理情報や辞書情報の分だけサイズが大きくなる可能性が大きいのである。こういったケースを考慮して、TLSCompressedのfragmentフィールドには1024バイト分の余分なフィールドが見込まれているものと考えられる。
なお、ここまで説明しておいて話をひっくり返すようで恐縮だが、SSL/TLSの基本的な仕様の範囲には、データ圧縮の具体的なアルゴリズムは定義されていない。現段階では、データ圧縮を利用する枠組みだけが用意されていて、その実装については行われていないのが実情である。使用する圧縮アルゴリズムを含め、詳細は今後の仕様拡張として定義されるものと思われる。
圧縮のための辞書情報●
圧縮アルゴリズムの中には、頻出する値の並びを辞書に登録しておき、値の並びを辞書のエントリ番号で置き換えることで、全体のデータサイズを小さくするというアプローチを行うものがある。LZ77符号、LZ78符号などはその代表例だ。
これらのアルゴリズムでは、その結果出力には、本来の圧縮済みデータと共に、使用した辞書が添付される。もし、圧縮対象データの圧縮率がゼロに近いと、添付した辞書のサイズ分によって、圧縮後データの方がサイズが大きくなることがある。
TLSCiphertext
データ圧縮機能により圧縮されたデータはTLSCompressed構造体に格納されている。そこに格納されたデータと、そのデータから算出したダイジェスト値、そして暗号アルゴリズムによってはパディングを加え、それら全体に暗号化を施したデータは、次にTLSCiphertext構造体に格納される。
TLSCiphertext構造体には2つのパターンが存在する。その違いは、使用する暗号化アルゴリズムの性質、具体的には暗号化対象データの取り扱い単位に起因するものだ。このうちの1つは、暗号化対象データを一連のストリームとしてみなして、バイトまたはビット単位で暗号化処理を行うものだ。このタイプの暗号はストリーム暗号と呼ばれる。もう1つのタイプは、暗号化対象データを一定サイズのブロックに区切って、そのブロック単位で暗号化処理を行うものだ。こちらはブロック暗号と呼ばれている。
ストリーム暗号は、それを適用する対象データのサイズに制約がない。そのため、暗号操作を行う前処理は不要である。一方、ブロック暗号では、暗号化対象データは特定のブロックサイズ(暗号アルゴリズムによって異なる)でなければならない。ブロックサイズに満たない場合に、パディングと呼ばれる詰め物をして、あらかじめブロックサイズとなるよう調整した上で、暗号操作を適用する必要がある。このための構造がブロック暗号使用時には必要となるため、TLSCiphertext構造体の構成には2パターンが存在しているという事情なのである。
なお、具体的な暗号アルゴリズムとしては、ストリーム暗号の代表例としてはRC4、またブロック暗号の代表的なものとしてはDESやFEALなどがある。また、IPAのWebページ「暗号アルゴリズムの登録状況」(http://www.ipa.go.jp/security/enc/regist-3.htm)には、国際的に登録されている暗号アルゴリズムの一覧があり、ストリーム暗号、ブロック暗号の区別が記してあるので参照してみるとよい。
Copyright © ITmedia, Inc. All Rights Reserved.