JFSのファイル管理とジャーナリングの実装:Linuxファイルシステム技術解説(6)(1/3 ページ)
AIXで生まれ、OS/2 WarpのソースがLinuxに移植されたJFS。そのファイル管理機構とジャーナリングがどのように実装されていいるのかを解説する。(編集局)
JFSとは
JFS(Journaled File System)は、IBMが開発している高性能ファイルシステムである。開発開始当初よりジャーナリングを前提としており、商用UNIXで10年以上にわたって利用・改善されてきた歴史がある。
Linuxに移植されたのは、JFSの歴史の中では比較的最近である。だが、JFSはもともと性能はもとより信頼性に重点を置いた技術的な蓄積が豊富であるため、今後のエンタープライズでの利用が期待される。
JFS開発史
JFSは1990年、AIX v3.1に初めて実装された。その後も改良が重ねられ、v5.0以降はJFS2(Enhanced Journaled File System)になっている。
現在のオープンソース・コードは、1999年にOS/2 Warp Serverに導入されたものが基になっている。2000年2月からLinuxへの移植が始まり、2001年6月にバージョン1.0.0がリリースされた。これは、Alan Cox氏によってカーネル2.4.18pre9-ac4にマージされた。2002年2月には、Linus氏が安定版1.0.20をカーネル2.5.6-pre2にマージし、カーネル2.6から正式に標準カーネルに取り込まれることになった。
コラム LinuxにおけるJFSの利用
前述したように、JFSが標準カーネルに取り込まれたのはカーネル2.6からである。ただし、カーネル2.4にJFSをデフォルトで組み込んでいるディストリビューションもある。この場合は、特に設定を行わなくてもJFSを利用できる。そうではない場合は、カーネルの再構築が必要となる。
カーネルの再構築では、make menuconfig(gconfigなど)で「JFS filesystem support」をONにする。モジュールとして利用する場合は、モジュール機能を有効にして「M」を選択する。
JFS 1.0.21以降では、実験的ではあるがACLも利用できる。xattrシステムコール系(extended attribute for security module)への対応やLSMなどのセキュリティモジュールのAPIにも対応している。
JFS for Linuxは、IBMのオリジナルのJFS設計・開発者らを中心に開発されている。開発速度も速く、2001年に19回、2002年は15回と、ハイペースでバージョンアップを繰り返している。2002年はバージョンアップの回数こそ減少したが、ACLやquotaの導入など、重要な拡張が行われている。
JFSのコード量はext3の約3倍もあるが、設計は明確で実装も洗練されている。
JFSの目標は、高い信頼性、性能、スケーラビリティ(SMP)の実現である。JFSはこれらの目標を満たすため、明確なアルゴリズムを用いている。例えば、信頼性を実現するためにデータベースが採用していたジャーナリング技術を取り込み、メタ・データのみを保存し、かつトランザクション管理を行う方法を提示した。また、高性能を実現するためにB+-Treeによるオブジェクト管理、スケーラビリティに対応するための動的iノードやエクステント方式を採用し、信頼性と効率というトレードオフに対して最大限の解決を図っている。
JFSのスケーラビリティ
JFSはエクステント方式の採用により、ファイルの入出力が効率化されている。また、B+-Treeを用いることで、大容量ファイルの高速なアクセスを実現している。
JFSが扱えるファイルサイズは、512bytesブロック使用時で最大512Tbytes。4kbytesブロック使用時は最大4Pbytesである。また、ファイルシステムの最大サイズは4Pbytes(512bytesブロック時)、32Pbyets(4kbytesブロック時)である。
ただし、64bit化されていないLinuxの場合、これらの値はI/Oアーキテクチャの限界値によって制約される。32bit Linuxでは、32bitで扱える2Tbytesが実際の上限となる。
JFSの構造
初めに、JFSのファイルおよびデータの管理方法について見てみよう。
■パーティションとファイル
JFSはほかのファイルシステムと同様、パーティション上に作成される。ブロックサイズは512、1024、2048、4096bytesの中の1つを選択できる。
JFSはディスクの分散環境などをサポートするために、ディスクスペースの割り当てを「集合体」(aggregate)として管理する。集合体には複数のファイルセットが含まれる。各ファイルセットは図1のように、マウントするディレクトリとファイルのサブツリーを管理する。例えば、図1のファイルセット0は/etcと/home以下のディレクトリのサブツリーを管理している。
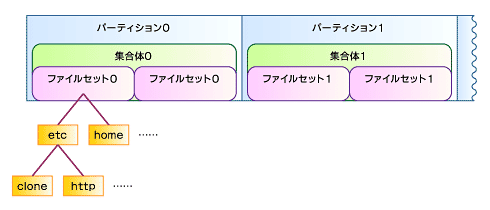
サブツリーに含まれるファイルとディレクトリは、エクステント方式で管理されている。第3回で解説したように、エクステントはディスク上の物理的なアドレスに対してファイルのオフセットと開始アドレスを与え、効率的にファイル管理を行う方式である。
JFSでは、割り当てグループ(AG:allocation group)という単位でファイルにiノードを割り当てる。AGは、ディスクを効率的に利用するために集合体の中のスペースを分割し、ディスク内でのiノードおよびディスクブロックを最適に配置するように管理する。
エクステントがAG単位でファイルのスペースを割り当てる際、ファイルは複数のAGにまたがることができるが、最大限連続した割り当てを行う。エクステント長は24bitであるため、512bytesブロックサイズ時の最大エクステントは512×2^24となり、8Gbytesまで表現できる。ブロックサイズを4kbytesとした場合、扱えるファイルサイズは4k×2^24で64Gbytesまでになる(注)。
注:これらの制限はシングルエクステントにのみ適用されるため、それ以上のファイルサイズの場合制限はない。
以上のように、ファイルセットはiノードをグループ化して集合体単位で扱い、その集合体のマップと制御用管理領域を持つものとして定義されている。
図2は、ファイルセットと集合体のレイアウトを示している。iノードの集合体とマッピングの詳細を(1)〜(3)に示す。
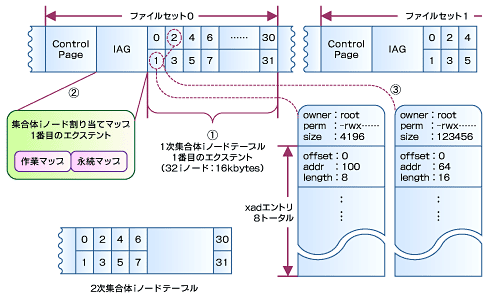
(1)集合体iノードテーブル
集合体iノードテーブルはiノードの配列を含み、ディレクトリもファイルもiノードとして管理する。集合体iノードテーブルには1次と2次の2つがあり、2次集合体iノードテーブルには、1次集合体iノードテーブルから複写したiノードが収められている。2次集合体iノードテーブルは検索に使用するだけなので、iノードの実データではなくアドレッシング構造とiノードそのもののみが複写される。
(2)集合体iノード割り当てマップ(Aggregate Inode Allocation Map)
集合体のiノードに関する情報とiノードのディスク上の位置を記録する。これは後述する動的iノードの管理に用いられる。
集合体iノード割り当てマップに含まれる作業マップと永続マップは、ジャーナリング情報としても用いられる。永続マップはコミット済みの割り当てを記録する。割り当てが行われると作業マップが更新され、集合体ブロックが解放される際は最初に永続マップが更新される。
(3)集合体iノード
集合体iノードは、集合体が作成された時点で最初のiノードのエクステントが割り当てられる。追加のiノードエクステントは、その都度必要に応じて動的に割り当てられたり解除されたりする。
動的iノード
JFSは、動的iノードをサポートしている。第2回で解説したように、BSDのFast File System(BSD FFS)から派生したブロックアルゴリズムをベースとしたファイルシステムでは、iノードはブロックの位置に固定されている。それ故に、ディレクトリやファイルを移動した際は、iノード番号を新しいブロック上の位置の番号に変更しなければならない。
これに対して動的iノードの場合、iノード構造体はブロック上の位置に固定されておらず、要求に応じて動的に割り当てられる。iノードを動的に割り当てることで、iノードディスクブロックをどのディスクアドレスにも置けるようになり、iノード番号を位置と無関係に扱える。これにより、ディレクトリのコピーなどでもiノードの更新を行う必要がなくなった。大きなファイルへのiノードの割り当てが複数のブロックグループにまたがる場合でも、連続性が確保される(注)。
注:静的な割り当ての場合、連続して確保できないことが多いためにギャップが生じる。
動的iノードの問題点としては、iノードとブロックの対応付けのために別個のマップが必要となることが挙げられる。これは、静的な割り当ての場合はiノードテーブルとディスク上のレイアウトが一致するが、動的な場合は一致しないためである。
もう1つの問題点として、iノードとディスク上のブロックの位置を高速検索する必要があることである。動的iノードの割り当てでは、iノード番号が近いとしても実際のブロック配置が近いとは限らない。逆に、離れた番号を持つiノード同士がディスク上では近くに位置することもあり得る。
このように、動的iノードではiノードとディスク上のブロックの位置が一致しないため、検索によって互いの位置を高速に探す仕組みが必要となる。高速検索を実現するため、JFSのデータ構造は、B+-Treeからたどれるように順方向、逆方向、フリーiノード番号のルックアップという3種類の操作をサポートしている。
B+-Treeによる検索の効率化
JFSはB+-Treeを用いることで、ファイルのエクステントの読み書き、追加・削除を効率的に行っている。ここでは、その基となるデータ構造を紹介する。
エクステントの割り当ては、xad構造体(xad:extent allocation descriptor)を利用する。xad構造体はエクステントの記述とともに、ファイルの表現に必要なオフセットとフラグフィールドを提供する。
xad構造体により、2つの値が求められる。1つ目が、ディスクブロックの物理的な範囲の値である。これは、集合体ブロック番号xad_addressによる開始位置とxad_lengthによる長さ(集合体ブロックの個数)で導き出せる。
もう1つは、ファイル内のバイトの論理的な範囲である。同じくバイト番号xad_offset×AGBS(集合体ブロックサイズ)による開始位置とxad_length×AGBSによる長さで計算できる。このとき、物理的な範囲と論理的な範囲は同じバイト長となる。
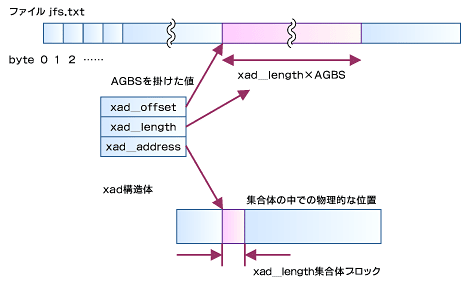
エントリは、xad構造体のオフセットによってソートされる。xad構造体はB+-Treeのノード内エントリとなっている。
図2の(3)のように、iノードテーブルが持つ集合体iノードにはB+-Treeのルートに関する8つのxad構造体が入る。これらがB+-Treeのリーフノードまたは内部ノードへの参照などのポインタを保持する。ファイルのエクステントが8個を超えた場合は、xad構造体を得るためにiノード内のデータフィールドを使用する。さらにそれも使用してしまった場合、B+-Treeは分割される。
エクステントを使用したアドレッシングの例として、17Mbytesのファイルと16Gbytesのファイルがどのように割り当てられるかを見てみよう。ブロックサイズを1kbyteとした場合、17Mbytesのファイルはブロックを1700個使用する。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
同じxad構造体で、1739777(1699×1024+1)?1740801(1700×1024+1)の範囲の連続ファイルを表現できる。エクステントディスクリプタが表現するサイズは、最低でもブロックサイズまでに限られるためである。
次に、連続的に割り振られる16Gbytesのファイルを見てみよう。xad構造体のlengthフィールドは24bit長なので、このフィールドが保持できる値は最大で2^24?1である。集合体ブロックサイズが1024bytesの場合、単一のxad構造体で表現できる最長のエクステントは(2^24?1)=1677215で、16Gbytes(1677216)に1kbytes足りない値となる。つまり、16Gbytes以上の場合は複数のエクステントが必要となる。
集合体ブロック番号5555から始まって、1kbytesの集合体ブロックが1677216個(16Gbytes)連続するので次のようになる。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
この場合、ディスク上でのファイルの連続性にかかわらず、最低2つのxad構造体が必要となる。これらのxad構造体が、B+-Treeの中に配置される。B+-Treeの中にxad構造体とそこから参照されるiノードが配置された状態は、ブロック割り当てマップに保存される。
ブロック割り当てマップ
iノードのトラッキングを集合体全体で行うために利用されるのが、ブロック割り当てマップ(Block Allocation Map)である。割り当てマップは、集合体の拡大/縮小に合わせて動的に拡大/縮小する。このマップは、制御データの更新を信頼できる方法で行うために、ディスクに書き込まれるタイミングも調整されている。ここでいう「信頼できる更新」とは、システム障害時にも一貫したJFS構造とリソース割り当て状態が維持されるという意味である。
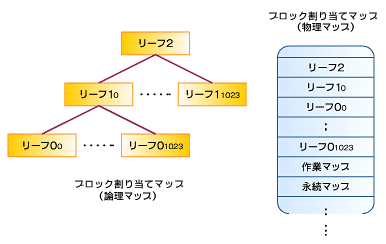
JFSでは、ブロック割り当てマップを確実に整合性のある状態にするために、2つのマップを用意している。作業マップ(working map)と永続マップ(persistent map)である。このようにマップを常にバックアップすることで、現在のiノードの割り当てをできる限り障害発生直前に近い状態で復旧できるようにしている。
Copyright © ITmedia, Inc. All Rights Reserved.