日本語の文字符号化
文字符号化の基本についての確認が終わったところで、Shift_JIS、EUC-JPといった日本語の文字符号化およびUnicodeについて理解を深めましょう。
Shift_JIS、Windows-31
Shift_JISは、JIS X 0208:1997付属書1で規定されている文字符号化方式です。符号化文字集合としてはJIS X 0201とJIS X 0208を対象としています。
Shift_JISと同じ方式で文字符号化をするWindows-31Jという文字符号化方式もあります。これは、Shift_JISが対象とする符合化文字集合へMicrosoft Windowsで使われている符合化文字集合を加えたものを対象としています。Shift_JISと区別して使用しないと正しく文字を扱うことができません。
どんな場合に問題が発生するのか、プログラムで確認をしてみましょう。Shift_JISとWindows-31Jで問題が発生するのは、Windows-31Jに加えられている符号化文字集合を使った場合です。例えば、①;のように数字を丸で囲んだ文字などが含まれます。
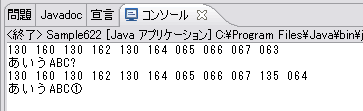
“あいうABC①”の文字列を次のようにShift_JISとWindows-31Jの文字符号化方式を使ってbyte型配列を取得した後、同じbyte型配列に対して同じ文字符号化方式を使ってString型オブジェクトへ変換してみます。
import java.io.UnsupportedEncodingException;
import java.text.DecimalFormat;
import java.text.NumberFormat;
public class Sample622 {
public static void main(String[] args) {
NumberFormat nf = new DecimalFormat("000 ");
try {
String s = new String("あいうABC①");
byte[] bs = s.getBytes("Shift_JIS");
for (int i=0 ; i<bs.length ; i++) {
System.out.print(nf.format(toInt(bs[i])));
}
System.out.println("\n"+new String(bs, "Shift_JIS"));
bs = s.getBytes("Windows-31J");
for (int i=0 ; i<bs.length ; i++) {
System.out.print(nf.format(toInt(bs[i])));
}
System.out.println("\n"+new String(bs, "Windows-31J"));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
private static int toInt(byte b) {
int n = 0x000000FF & b;
return n;
}
}
Javaのbyte型は符号付きであるため、取得したbyte型配列の各要素の値をそのまま表示すると、最上位ビットが1となる128以上の値については負の値として表示されてしまいます。これを正の値として表示するために、「&」を使ったビット演算を行ってint型へ変換するtoIntメソッドを用意しています。整数型のビットイメージについては、「第5回 EclipseでJavaの型を理解する」を参照してください。
これを実行すると、対象となる符号化文字集合に①を含む文字符号化方式であるWindows-31Jは問題がありませんが、そうではないShift_JISでは①に相当する文字の変換に失敗して「?」と表示されてしまいます。こういった違いがあることをよく覚えておきましょう。
コラム
シフトJIS
一般的に使用されるシフトJISという用語はShift_JISを指しているとは限りません。Windows-31Jを指している場合もありますし、Shift_JISとWindows-31Jの両方を意味している場合もあります。さらに、Windows-31J以外にも、独自に拡張した符号化文字集合を対象としてShift_JISと同じ方式で文字符号化をするものがあります。ひとつは、いわゆるApple Japaneseといわれるもので、Macintosh用の独自に拡張した符号化文字集合を対象とする文字符号化です。また、いわゆるIBM CP942/943といわれるOS/2用の独自に拡張された符号化文字集合を対象とする文字符号化もあります。このため、シフトJISという用語を使うときには注意が必要です。
EUC-JP
ECU-JPは、UNIX系のOSで日本語を利用するときによく使われている文字符号化方式です。EUC(Extended UNIX Code)自体は日本語に限らず多言語に対応できるように定められています。そのままでは中国語や韓国語のための文字符号化方式なども含まれてしまいますから、日本語を扱うものについては特にEUC-JPと言って区別します。基本的に対象とする符号化文字集合はJIS X 0201 ローマ字、JIS X 0208になります。JIS X 0201 カタカナ、JIS X 0212を含めることもできます。符号化の方式はISO 2022で定められている8ビットで文字を表現するものを使っているため、7ビットで文字を表現するISO-2022-JPとは違って、エスケープシーケンスによる処理対象となる符号化文字集合の切り替えはありません。このため処理は単純になります。
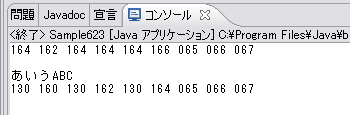
Javaでは、Windows-31JもEUC-JPもサポートしているので、簡単な文字符号化の変換処理ならすぐにできてしまいます。次のプログラムでは、「あいうABC」を表現するEUC-JPの文字符号化方式によるバイト列を、Windows-31Jの文字符号化方式によるバイト列へ変換しています。一度、JavaのString型オブジェクトへ変換してから、Windows-31Jのbyte型配列へ変換するというのがポイントです。
import java.io.UnsupportedEncodingException;
import java.text.DecimalFormat;
import java.text.NumberFormat;
public class Sample623 {
public static void main(String[] args) {
NumberFormat nf = new DecimalFormat("000 ");
try {
byte[] bs = new byte[]{ -92, -94, -92, -92, -92, -90, 65, 66, 67 };
for (int i=0 ; i<bs.length ; i++) {
System.out.print(nf.format(toInt(bs[i])));
}
System.out.println("");
String w = new String(bs, "EUC-JP");
System.out.println("\n"+w);
bs = w.getBytes("Windows-31J");
for (int i=0 ; i<bs.length ; i++) {
System.out.print(nf.format(toInt(bs[i])));
}
System.out.println("");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
private static int toInt(byte b) {
int n = 0x000000FF & b;
return n;
}
}
実行結果は次のようになります。
Unicode
Java2 Platform SE 5.0の文字表現では、「Unicode Standard、バージョン 4.0」を使っています。Unicodeに関する情報はUnicode Home Pageにあります。対象となる符号化文字集合としては16ビットで文字を表現するUCS-2(Universal Character Set coded in 2 octets)、31ビットで文字を表現するUCS-4(Universal Character Set coded in 4 octets)といったものがあります。これらはISO/IEC 10646により定義されています。ISO-2022-JP、Shift_JIS、EUC-JPと比較して、符号化文字集合に含まれる文字は非常に多くなっています。なお、UCS-2、UCS-4は名称からしても符号化文字集合のことなのですが、文字に割り当てられた数値をそのまま使っても処理しやすいため、ASCIIと同様に文字符号化方式と考えることもできます。ちなみに、Unicode標準では文字に割り当てられた数値を表すために「U+XXXX」といった表記を使います。XXXXの各Xは十六進数で指定します。
文字符号化方式についてはUTF-8(UTF-8 Encoding Scheme)、UTF-16(UTF-16 Encoding Scheme)といったものがあります。ここで、Glossary of Unicode Termsによると、単にUTF-8といった場合には、The UTF-8 encoding form、The UTF-8 encoding scheme、UCS Transformation Format 8の意味があるということなので、用語の使い方には注意が必要です。
Javaでは文字を表現する型としてchar、java.lang.Characterクラスがあります。文字列を表現する型としてjava.lang.Stringクラスがあります。java.lang.Characterはcharのラッパクラスですから、ここではcharとjava.lang.Stringクラスを使ってみましょう。次に示すSample630クラスを作成してください。このプログラムではcharの配列を使っています。csの各要素には1文字ずつ文字を指定し、cusの各要素にはcsへ代入したものと同じ文字を「\uXXXX」といったUnicodeエスケープシーケンスで表したものを指定しています。XXXXの各Xは十六進数です。最後の4行ではchar型配列cs、cusから生成したjava.lang.String型オブジェクトを使った場合と文字列リテラルを使った場合の例を示しています。
public class Sample630 {
public static void main(String[] args) {
char[] cs = new char[] {
'あ','い','う','A','B','C'
};
char[] cus = new char[] {
'\u3042', '\u3044', '\u3046',
'\u0041', '\u0042', '\u0043' };
for (int i=0 ; i<cs.length ; i++) {
System.out.print(cs[i]);
}
System.out.println("");
for (int i=0 ; i<cus.length ; i++) {
System.out.print(cus[i]);
}
System.out.println("");
System.out.println(new String(cs));
System.out.println(new String(cus));
System.out.println("あいうABC");
System.out.println("\u3042\u3044\u3046\u0041\u0042\u0043");
}
}
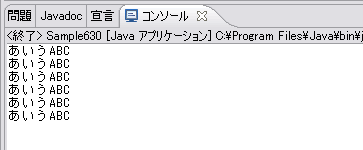
Sample630クラスのプログラムを実行すると結果は次のようになります。どれも「あいうABC」とコンソールへ出力されていることがわかります。
native2ascii
Microsoft Windows環境で開発をして、Linux環境で統合ビルド、運用をするという場合を考えてみましょう。こういった時には、Windows-31Jの文字符号化を使ってプログラムコードを記述して、それをLinux環境へ持っていくことになります。ここで、Linux環境ではEUC-JPの文字符号化を基本的に使うことになりますから、Windows-31Jの文字符号化で記述されたソースはコンパイルができないという問題が発生します。
そんなときはjavacのコンパイルオプションでソースコードで使われている文字符号化を指定すれば解決します。例えばWindows-31Jを使っている場合は、次のようにします。
javac -encoding Windows-31J Sample621.java
native2asciiツールを使って、ソースコードに含まれる日本語をUnicodeエスケープシーケンスへ変換してからコンパイルをするという方法もあります。例えば、あらかじめ変換後のソースコードを保存するディレクトリtargetを用意した上で、Windows-31Jで記述されているソースコードに対して、次のように使います。なお、例では変換される部分だけを抜き出しています。
実行例 native2ascii -encoding Windows-31J Sample621.java > target/Sample621.java
変換前 String s = new String("あいうABC");
変換後 String s = new String("\u3042\u3044\u3046ABC");
ASCIIの符号化文字集合に含まれる文字については変換されませんが、そうでない文字についてはUnicodeエスケープシーケンスによる表現に置き換わります。
Copyright © ITmedia, Inc. All Rights Reserved.