‘愛’で学ぶ文字コードと文字化けの常識:プログラマーの常識をJavaで身につける(6)(2/4 ページ)
本連載は、Java言語やその文法は一通り理解しているが、「プログラマー」としては初心者、という方を対象とします。Javaコアパッケージを掘り下げることにより「プログラマーの常識」を身に付けられるように話を進めていきます。今回は、文字コードや文字化けについて。OSや携帯電話の機種の違い、メール、Webブラウザ、DB入出力、国の違いなどさまざま原因で起きる文字化けを徹底解説!
Javaで文字エンコーディングを使ってみよう
前述のように、Javaは内部的に文字エンコーディングとしてUTF-16を用いています。このUTF-16をほかの文字エンコーディングに変換するための機能がJava APIとして提供されています。世の中にあるさまざまな文字エンコーディングを取り扱うために、この機能は必要になります。
バイト配列を16進表記文字列にする便利クラスを差し上げます
まず、バイト配列を一般的な16進表記文字列にするためのユーティリティクラス(HexStringUtil.java)を準備しておきます。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
これ以降のソースコードは、このユーティリティクラスが存在することを前提としています。なお、このようなユーティリティは文字コードを調べる目的以外でも有益である場合があります。ぜひご活用ください。
文字列 → シフトJISのバイト配列
最初に、日本語の文字エンコーディングとしてよく用いられているシフトJISの文字エンコーディングを調べます。Java上の文字列をシフトJISのバイト配列に変換する例を見てみましょう。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
実行すると、下記のような結果を取得できます。
実行結果
[愛植岡]をシフトJISのバイト配列に変換
88 a4 90 41 89 aa
この例では3文字が6個のbyteへと変換されていることが分かります。ただこれでは、どの文字がどの文字に変換されたのか分からないので、1文字だけ変換してみます。上記ソースコード中の桃色の個所を下記のように書き換えます。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
すると、‘愛’の文字が88 a4 という2バイトへと変換されることが分かります。
実行結果
[愛]をシフトJISのバイト配列に変換
88 a4
シフトJISのバイト配列 → 文字列
これとは逆に、バイト配列から文字列を作ることができます。今回得られたバイト配列を下記ソースコード中の桃色の個所のように与えて、文字列へと変換します。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
実行結果は下記のようになります。元の文字列に戻っていることが分かります。
実行結果
[88 a4 90 41 89 aa]をシフトJISのバイト配列として文字列に変換
愛植岡
文字列とバイト配列の相互変換は、下記のような対応になります。
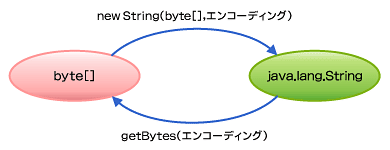
それ以外の文字エンコーディングを調べるための事前準備
それでは、シフトJIS以外の文字エンコーディングも調べていきます。まず、簡単に文字エンコーディングを切り替えられるように、先ほどのStringToBytesSample.javaのソースコードを少し拡張し、文字エンコーディング指定を外部から変更できるようにしておきます。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
準備ができたので、サンプルプログラムを動作させてみましょう。私たちはプログラマーなので、こういった事象をプログラムを使って検証できます。
EUC-JPエンコーディング
まず、UNIXなどで日本語を扱う際によく使われているEUC-JPエンコーディングを指定して動作させてみます。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
実行結果
[愛植岡]を[EUC-JP]バイト配列に変換
b0 a6 bf a2 b2 ac
ここで指定できる文字列は 前述のサポートされているエンコーディングのページで調べることができます。EUC-JP以外にも、よく知られる文字エンコーディングを与えてみましょう。
ISO-2022-JPエンコーディングを指定した場合
実行結果
[愛植岡]を[ISO-2022-JP]バイト配列に変換
1b 24 42 30 26 3f 22 32 2c 1b 28 42
エスケープシーケンスと呼ばれるものが付与されているため、かなりバイト数が増えます。エスケープシーケンスについての詳細は、『文字コード超研究』の316ページなどを参照ください。
UTF-8エンコーディングを指定した場合
特に、XMLなどにおいて頻繁に利用されるのが、UTF-8エンコーディングです。UTF-8はUnicodeの文字エンコーディングのひとつです。
実行結果
[愛植岡]を[UTF-8]バイト配列に変換
e6 84 9b e6 a4 8d e5 b2 a1
UTF-16エンコーディングを指定した場合
同じく、XMLなどにおいてよく利用されるのが、UTF-16エンコーディングです。UTF-16はUnicodeの文字エンコーディングのひとつです。
UTF-16エンコーディングはバイト配列表現に変換する際に注意が必要になります。というのも、16ビットであるchar型を8ビットであるbyte型に詰め込む際に、上位8ビットと下位8ビットのいずれのbyteを配列として先に位置させるのか(エンディアン)を明示する必要があるからです。
UTF-16BEはビッグエンディアン(big endian)を明示したUTF-16です。上位8ビットの方が先に配置されます(先ほど‘愛’は611bだったことを思い出してください)。
実行結果
[愛植岡]を[UTF-16BE]バイト配列に変換
61 1b 69 0d 5c a1
UTF-16LEはリトルエンディアン(little endian)を明示したUTF-16です。下位8ビットの方が先に配置されます。
実行結果
[愛植岡]を[UTF-16LE]バイト配列に変換
1b 61 0d 69 a1 5c
UTF-16はエンディアンを明示していません。その代わり、先頭に「バイト順マーク(BOM:Byte Order Mark)」というものを2バイト付与してエンディアンを表現します。この2バイトでリトルエンディアンかビッグエンディアンかを判断できるようになっています。
実行結果
[愛植岡]を[UTF-16]バイト配列に変換
fe ff 61 1b 69 0d 5c a1
なお、この実行例はビッグエンディアンです。リトルエンディアンの際には、先頭にff fe の2バイトが付与されます。
サポートされていない文字エンコーディングを指定すると例外発生
ここでもし、Javaでサポートされていない文字エンコーディングを指定すると、例外が発生します。例えば、存在しない名称の“ARIMASEN”エンコーディングを指定してみて動作させてください。下記のような例外が発生します。
実行結果
[愛植岡]を[ARIMASEN]バイト配列に変換
サポートされないエンコーディング[ARIMASEN]が指定されました。
java.io.UnsupportedEncodingException: ARIMASEN
at sun.io.Converters.getConverterClass(Unknown Source)
at sun.io.Converters.newConverter(Unknown Source)
at sun.io.CharToByteConverter.getConverter(Unknown Source)
at java.lang.StringCoding.encode(Unknown Source)
at java.lang.String.getBytes(Unknown Source)
at StringToBytesSampleEnc.process(StringToBytesSampleEnc.java:18)
at StringToBytesSampleEnc.main(StringToBytesSampleEnc.java:6)
このように、文字エンコーディング名は少しでも間違えると、サポートしないエンコーディング名を指定したことになり、例外が発生します。
Copyright © ITmedia, Inc. All Rights Reserved.