ThreadとHashMapに潜む無限回廊は実に面白い?:現場から学ぶWebアプリ開発のトラブルハック(10)(2/3 ページ)
本連載は、現場でのエンジニアの経験から得られた、APサーバをベースとしたWebアプリ開発における注意点やノウハウについて解説するハック集である。現在起きているトラブルの解決や、今後の開発の参考として大いに活用していただきたい。(編集部)
【第三章】突刺(ささ)る
さて、実際に解析してみよう。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
CPU使用率が高いプロセスのLWPIDを上から3つ抜き出すと、「13779」「13799」「13815」となった。スレッドダンプでのnidは、16進数になることに注意する。16進数に変換すると、「0x35d3」「0x35e7」「0x35f7となり」、次の3つのスレッドが問題スレッドとなる。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
なんと、HashMapクラスのputメソッドでCPUを消費していたのだ。こればかりはA君も私も、「へぇ?」と間抜けな声を発してしまった。
「たまたまHashMapのputメソッドで止まっているのではないか」「実はものすごく大きいHashMapなんだ」とか仮説の域を出ない話に盛り上がるのに終止符を打つため、それ以外のスレッドダンプについても確認した。すると、TP-Processorの中でCPU使用率が異様に高いスレッドはすべてHashMapのputメソッドで止まっていた。さすがにこれは奇妙である。
もやもやしたまま、該当部分のソースコードレビューを開始した。
■あっけない終焉
ソースコードを確認したが、一見して特別変わった使われ方ではなかった。当たり前だが、要素を挿入する、ただそれだけのことを行っていた。HashMapの宣言部分を確認すると、該当HashMapはstatic宣言されていた。
static宣言であれば話は早い。A君の「synchronizedされてないね」という、たったその一言でソースコードレビューは完了してしまった。
早速、synchronizedブロックでHashMapを同期化して試験を行ってみると、何度試験しても再現しなくなっていた。あっけない終焉(しゅうえん)である。帰り際にA君がポツリと、「何で同期化してないだけで、CPUが100%も上昇するんだろう」と漏らしていたことが、最後まで私の心に突き刺さっていた。
【第四章】裏取(うらをと)る
先ほどの調査より、CPUを多大に消費しているスレッドは、すべてHashMap.putメソッドで停止していることが分かった。そして、その原因が、HashMapを同期化せずに利用していたことが起因とも分かった。
しかし、なぜHashMap.putメソッドで停止しているのか、そしてHashMap.putメソッドで停止していると、なぜCPUが100%で停止しているのか、裏を取らなければ、本物のトラブルハッカーとはいえない。
■HashMap.putメソッドのおさらい
まず、HashMap.putメソッドのおさらいをしよう。そのために、HashMapクラスのJavadocで確認を行うと、以下のようになっていた。
「この実装は同期化されません。複数のスレッドが同時にこのマップにアクセスし、それらのスレッドの少なくとも1つが構造的にマップを変更する場合には、外部で同期をとる必要があります」
このように、HashMapの構造に変化を与える場合、外部で同期化する必要がある。いい換えれば、synchronizedブロックで囲むだけで事象が再現しなくなるという発生条件は、HashMapの構造が変わるタイミングで何らかの出来事が起きたと考えるのが自然だろう。
HashMap.putのソースコードを追ってみよう。マルチスレッド系のバグであるならば、ソースコードを追うことで、問題を検出できるはずだ。
■HashMapの仕組み
まず、HashMapクラスの構造を簡単に説明しよう。
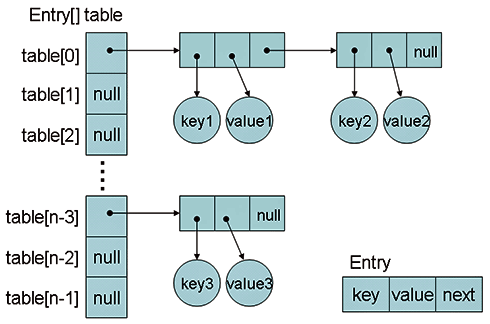
JavaにおけるHashMapクラスは、主に要素リストの配列(図1の「Entry[] table」)および要素(図1の「Entry」)で表現されている。
項目を参照する際、キーのハッシュ値から配列のインデックスを計算し、インデックスから参照されるリスト内より「key」の値が一致する要素を検索する。項目を追加するときも参照と同様に、インデックスを計算し、該当するリストの先頭に項目を追加する。全部の項目を探索せずに済むため、HashMapは検索、挿入、削除ともに良好な性能を出すことができる(最も良い場合、0/1で実行可能)。
ただし、項目数が多くなると、各インデックスにひも付けられたリストの大きさが大きくなり、性能劣化の要因となる。そのため、HashMap内に一定以上の項目が収められたとき、配列の大きさを大きくし、HashMap内のデータの並びを作り直すという作業が行われる。
■HashMap.putメソッドのソースコードを確認
さて、問題となっているのは、項目を追加するHashMap.putメソッドである。早速ソースコードを確認しよう。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
ここで注目していただきたいのは、6行目だ。putメソッド内で無限ループとなるためには、この6行目のforループが終了しないことが条件となる。終了条件が「e!=null」となっているため、リストに循環参照が発生している必要がある。
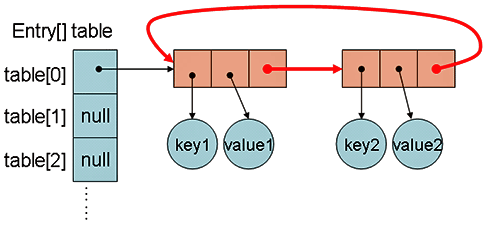
果たして、そのようなことが発生するのだろうか。検証してみよう。
■HashMap内に発生した無限回廊とは?
ここでいったん、HashMap.transferメソッドに注目したい。これは、HashMap内の項目が多くなり過ぎたときに、構造を作り直すためのメソッドだ。いわば、HashMapの構造を大幅に作り直すメソッド、すなわち一番問題が起きやすいメソッドだ。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
ここで注目したいのは、8行目から14行目にかけて行われる処理だ。ここでは、各リストの要素について、先頭から順にそれぞれのハッシュ値から新しいインデックスを計算し、該当リストの先頭に追加する処理を行っている。
いい換えると、この処理を完了すると、リストの順序が逆転する。トラブルハッカーとしての直感が、そうささやいた。それでは、机上シミュレーションにより、循環リストが発生するパターンを検討しよう。
Copyright © ITmedia, Inc. All Rights Reserved.