memcached+PostgreSQLで実現する ハイパフォーマンスWebアプリケーション構築:memcachedの使い方(1)(2/4 ページ)
大規模Webサイトでの利用事例が公開されたこともあり、キャッシュサーバを使ったデータベースシステムが注目を集めつつあります。中でもmemcachedは多くのサービスで運用実績がある注目株です。MySQLでの事例が多く取り上げられていますが、本稿では安定性抜群のPostgreSQLと組み合わせた場合の実装方法を紹介していきます。
memcachedの仕組みと新機能
ここからはmemcachedの仕組みそのものと、最近のバージョンで実装された機能について見ていきましょう。
memcachedの仕組み
memcachedの仕組みを3つの部分に分けて説明します。
1:通信管理とイベント処理
2:データ操作(保存、検索、削除)
3:メモリ管理
1:通信管理とイベント処理
通信管理とイベント処理はライブラリlibeventを利用しています。これを使ってデータの受信からコマンドの解析、データ操作、結果の送信までコンパクトに実装しています。
libeventは大量の同時アクセスも軽々こなす高性能なライブラリとして有名で、memcachedのレスポンスの高速化にも寄与しています。
2:データ操作
データ操作は保存、検索、削除の3種類に大別できます。
(1)保存の場合
データの保存を行うaddコマンドがmemcachedに届くと、(キーとデータの組である)itemを保存する領域を確保、キーのハッシュ値を求め、ハッシュテーブルに追加します。
簡単な例を使って説明しましょう。県庁所在地をキー、都道府県名をデータとするitemを保存します。
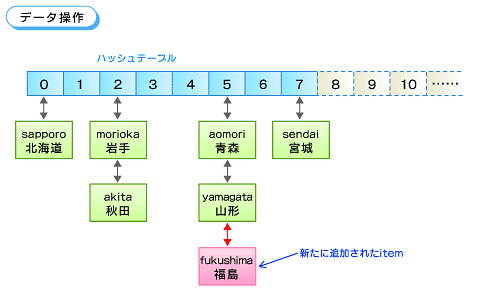
ここで、キー「sapporo」のハッシュ値は0、「aomori」は5、「morioka」は2、などとします。
新たにitem(キー「fukushima」、データ「福島」)を保存する場合、最初に「fukushima」のハッシュ値5を求め、次にハッシュテーブルの5に当たる要素のリストに追加します。ここではすでにitem(「aomori」、「青森」)とitem(「yamagata」、「山形」)がリストになっているので、その末尾に追加します。
(2)検索の場合
データの検索を行うgetコマンドが届くと、キーのハッシュ値を求め、ハッシュテーブルを順に検索して一致するキーのデータを返します。
キー「fukushima」を検索するには、キーのハッシュ値5を求め、ハッシュテーブルの5に当たる要素を順に検索します。最初のitemのキーは「aomori」、その次は「yamagata」なのでスキップします。その次のitemのキーは「fukushima」で一致するのでデータ「福島」を返します。
保存しているitemの総数がハッシュテーブル長の1.5倍を超えると、ハッシュテーブルを2倍に拡張し、itemの衝突が頻発することを防ぎます。初期状態のハッシュテーブル長は65536(2の16乗)、次は131072(2の17乗)、その次は262144(2の18乗)と倍々に伸びていきます。
これが、膨大な数のデータを保存しても検索性能が劣化しない大きな理由です。
(3)削除の場合
検索と同様にキーのハッシュ値からitemを検索し、求めたデータを削除します。
3:メモリ管理
先にitemの保存時には領域を確保すると説明しましたが、保存する度にOSからメモリ領域を確保するのでは時間がかかりすぎます。
そこでmemcachedはスラブ(slab)という1Mbyteの領域を事前に準備し、スラブ内部を多数の小さな領域で分割しておきます。この小領域をchunkと呼び、データの保存時はスラブ内のまだ使っていないchunkに保存していきます。
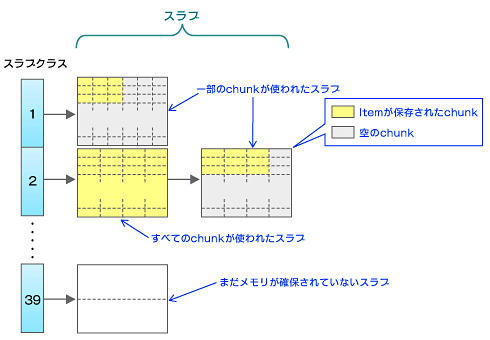
スラブはスラブクラス(slabclass)という配列で管理されています。初期状態ではslabclass[1]からslabclass[39]まであり、必要に応じてスラブがリンクされます。スラブは1ページ、2ページと数えます。
slabclass[1]に属するスラブのchunkサイズは88bytesで11,915個のchunkを含んでいます。slabclass[2]ではchunkサイズが112bytesで9,362個、slabclass[3]ではchunkサイズが144bytesで7,281個と、順にchunkサイズが大きくなり、slabclass[39]に属するページのchunkサイズは489,032bytesで2個のchunkから成ります。
itemを保存する場合、キーとデータ、およびいくつかの付属情報の合計サイズによって、どのスラブクラスのスラブに保存するかが決まります。
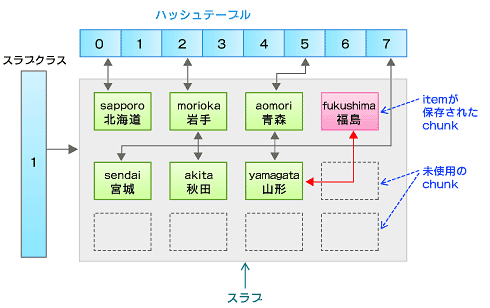
例えばキーが「fukushima」データが「福島」なら88bytesのchunkに収まるので、slabclass[1]に属するスラブ内のまだ使われていないchunkに保存されます。
スラブにある程度の数のitemが保存されると、新しいスラブがメモリ上に確保されてスラブクラスに追加されます。
以上を踏まえて、ハッシュテーブルとスラブクラス、およびスラブとchunkの関係をもう一度描き直すと次のようになります。
新機能とベンチマーク結果
memcachedは2003年5月30日にバージョン1.0.0がリリースされてから順調にバージョンアップが続き、最新バージョンは2008年3月4日リリースのバージョン1.2.5です。
これまでで一番大きな変更のあったバージョンは2007年12月6日リリースのバージョン1.2.4で、保存と検索のコマンドが4つ追加され、サーバプロセスのマルチスレッド化によって処理性能が大幅に向上しました。
| コマンド | バージョン1.2.3まで | バージョン1.2.4から |
|---|---|---|
| 保存 | set、add、replace | set、add、replace、append、prepped、cas |
| 検索 | get | get、gets |
| 削除 | delete、flush_all | delete、flush_all |
| 統計情報 | stats | stats(出力項目の追加) |
| 表3 バージョンアップに伴い追加されたコマンド | ||
昨今はデュアルコア、クアッドコアのCPUを搭載したハードウェアも珍しくありません。こうしたハードウェアでmemcachedをマルチスレッドで稼働させれば並行・並列処理が可能なので、1.2.4以降のバージョンではより高速なレスポンスが期待できます。
以下に、手元のサーバ(Intel Core2Quad 9660 2.4GHz)上で行ったバージョン1.2.5のベンチマーク結果を示します。
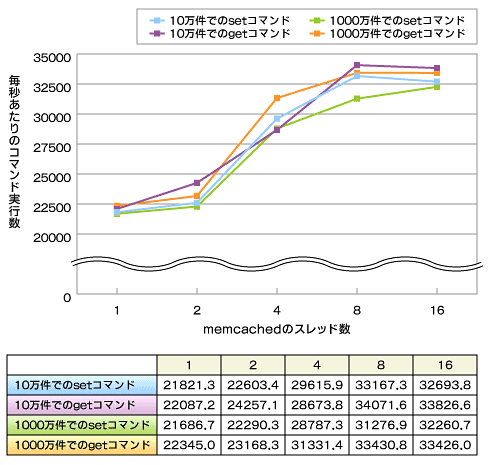
縦軸は毎秒のコマンド実行数です。memcachedに対して160のクライアントが同時並行にsetコマンド、もしくはgetコマンドを送信し、1秒間に何コマンド実行できるかを計測した結果です。横軸はmemcachedのスレッド数です。それぞれ1、2、4、8、16の5パターンで起動しました。また、起動直後に10万件および1,000万件のデータを保存してから計測することで、保存しているデータ数による影響も調べました。なお、setコマンドで送信するデータは100bytes、キーは1から100,000の間の数です。
一見してマルチスレッド化による性能向上が読み取れます。マルチスレッド化していない場合(スレッド数=1)と比較して、最大で50%程度処理性能が向上しています。また、setコマンドとgetコマンドでほとんど処理性能に違いがないこと、保存されているデータ数による影響もあまりないことが読み取れます。
コラム2:データ保存に関するTips
◆保存できるデータの最大サイズ
キーの最大長が250bytesであることはよく知られています。では保存できるデータの最大サイズはいくらでしょうか?
結論からいえば、保存できるデータの最大サイズはキーの長さに依存し、キーとデータの合計が1,048,521bytesまで保存できます。
memcachedのデータ保存の単位はchunkで、最大のchunkサイズは約1Mbyteです。つまり1ページがまるごと1つのchunkになります。
chunkにはキーやデータやexpire時間などクライアントから送られた情報以外に、最後にアクセスされた時刻などの情報が保存されます。さらにスラブ自体の情報も保存されます。これらの情報を差し引くと、キーとデータに与えうる最大サイズは1,048,521bytesとなります。
◆最大メモリ量を超えた場合のデータ保存
起動オプション「-m」で、メモリ上に保存できるデータの総量を設定できます。デフォルトは64Mbytesですが、もしも保存しているデータが64Mbytesを超えたらどうなるでしょうか?
memcachedはLRU(Least Recently Used)というアルゴリズムでchunkを管理しています。簡単にいえば「古い順に消えていく」というもので、データがいっぱいになったら古いものを消して新しいデータを保存し続けます。メモリがいっぱいでもエラーは返らないので注意が必要です。
よって、memcachedを長期間運用する場合はexpire時間を必ず設定し、ゴミとして残らないようにしなければなりません。
また、永続的に利用したいデータをmemcached上に置く場合は、大本のデータをデータベースに保管し、定期的にデータの再登録を行うなどの工夫が必要です。
Copyright © ITmedia, Inc. All Rights Reserved.