物理データモデル作成のポイントは“森→木→森”:ゼロからのデータモデリング入門(7)(1/3 ページ)
前回まで、システム企画段階における「概念データモデル」、基本設計段階における「論理データモデル」についてお話をしてきました。この2つの共通点は、企業のビジネス活動をデータモデルで可視化することでした。今回は、詳細設計フェイズにおける「物理データモデル」を解説します。
物理データモデリングとは
第4回「データベース設計はいつ、何をポイントに行うか」でも触れましたが、物理データモデリングは、システムを動かすことを目的に作ります。概念モデル、論理モデルとビジネスの視点を中心に設計をしていましたが、物理モデルは「システムの視点」による設計となります。
ここでは、リレーショナルデータベースへの実装を前提として、論理データモデルとの乖離(かいり)を最小限に抑えながら、アクセス方式と格納方式を考慮した設計を行うことで、システム要件を満たした「動くシステム」の設計を行います。
2つの方式で“複眼的な視点”を
物理データモデリングのポイントになるのが、「アクセス方式」と「格納方式」の2つの方式です。まずはこれらについて解説します。
アクセス方式
アプリケーションからデータへの最適なアクセス方法について検討します。例えば、テーブル走査とインデックス走査のどちらを選択するかなど、性能効率の高い方式を決めます。
格納方式
データベースの保守運用面から最適なデータ格納形式(構造)について検討します。例えば、データベースオブジェクトの内部構造の特徴や、データの更新頻度などを踏まえて、保守効率の高い方式を決めます。
物理データモデリングの場合は、どうしてもレスポンスを考慮した対策に終始してしまい、データベースのメンテナンス性という観点が欠落しがちです。アクセス方式のみ考慮すると、インデックスを過分に作成してしまい、その結果データの更新バッチのレスポンス性能の低下や、検索処理性能にまで影響を及ぼします。その原因は、インデックスの格納方式を踏まえた設計を行っていないことにあります。
例えばB-Treeインデックスは、枝と葉の均衡が保たれていればキーへのアクセスは均一ですが、インデックスブロックの均衡は、データの追加、更新処理の都度、RDBMSにより見直されます(ただし、インデックスブロックは、データが削除されてもデータベース再構成までは削除されません)。
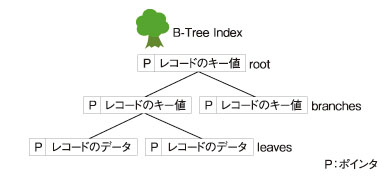
【参考】B-Treeとは
B-Treeは、Balanced Tree(バランス木)の略で、root(根)とbranches(枝)、leaves(葉)で構成される。最上位のrootから最下位のleavesまでが相互にリンクするポインタでつながっている。
関連記事:RDBMSで使われるB木を学ぼう(@IT Coding Edge)
http://www.atmarkit.co.jp/fcoding/articles/delphi/05/delphi05a.html
このように物理データモデリングでは、「森を見て(ボトルネックの発見)、木を見て(アクセス方式の検討)、森に帰る(格納方式の検討)」という視点が必要となります。
Copyright © ITmedia, Inc. All Rights Reserved.