大量データをスムーズに処理 失敗しないバッチ処理のアーキテクチャ設計、5つのポイント:徹底解説! ITアーキテクトとは何か?(3)(1/2 ページ)
ITアーキテクトの役割を、具体的かつ分かりやすく解説する本連載。今回は締め処理やデータ変換などで利用される、バッチ処理におけるアーキテクチャ設計のポイントを紹介する。
バッチ処理とは
前回はWebアプリのアーキテクチャ設計の基礎を解説しました。今回はバッチ処理を円滑に行うためのアーキテクチャ設計のポイントを紹介します。
バッチ処理とは、蓄積された複数件のデータを、まとめて一括処理する処理形態のことを指します。このような処理形態においては、大量データの処理を一定時間以内に完了させるためのアーキテクチャを、さまざまな角度から検討していく必要があります。
また、画面オンライン処理とは異なり、ユーザーとの対話なく処理が進められます。よって、バッチ処理の途中でエラーが発生した場合の対応を考慮して、アーキテクチャを設計しなければなりません。バッチ処理の基本についてより深く知りたい方は、下記参考記事をご参照ください。
参考リンク:鉄板焼のお店から学ぶ、バッチ処理"超"入門(@IT)
バッチ処理におけるアーキテクチャ設計時の検討ポイント
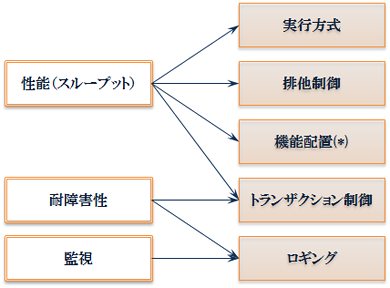
バッチ処理のアーキテクチャを考える上では以下の3点に留意する必要があります。
| 留意点 | 対応する非機能要件 | |
|---|---|---|
| 1 | 性能(スループット) | 性能・拡張性 |
| 2 | 耐障害性 | 可用性、運用性・保守性 |
| 3 | 監視 | 可用性、運用性・保守性 |
これら3つの留意点とバッチのアーキテクチャを設計する時の検討項目との関係を以下に示します。
ポイント1:実行方式
バッチ実行方式について、【実行場所】【起動方法】【並列処理】の観点で検討していきます。
実行場所(何を対象に行うか? 処理をどこで行うか?)
バッチ処理が対象とするデータの形態はいくつか考えられます。例えば、「データベースのレコードか? またはファイルか?」といった具合です。つまり「バッチ処理をどこで行うか?」は 扱うデータの形式に大きく関わってきます。実行場所の観点で、バッチ処理を分類すると以下のようになります。
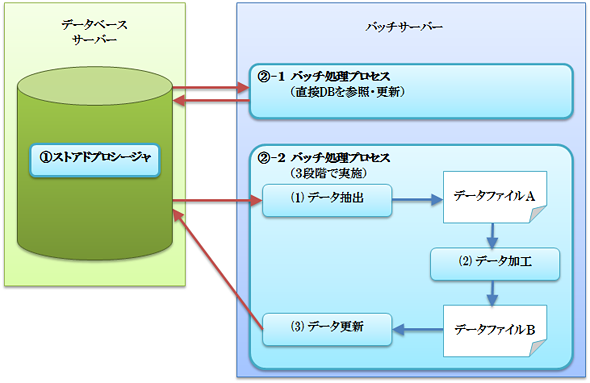
【1】ストアドプロシージャとして、データベースサーバーで実行
【2】バッチ処理を、一つのプロセスとして、バッチサーバーで実行
【2】-1.バッチ処理は、直接データベースを参照して更新などの処理を行う
【2】-2.バッチ処理は、ファイルを参照して処理を行う(実質的には以下の3段階で実施します。詳しくは「トランザクション」で説明します)
【1】はデータベース処理をストアドプロシージャとして実装する方式で、処理は高速ですが、その分データベースサーバーに負荷が掛かります。この形式を、Oracleデータベースを例に考えると、PL-SQLを利用することになります。この場合は、ロジックの実装が複数の言語にわたるため、メンテナンス性は下がる傾向にあります。この方式の利点は、データベースサーバーとバッチサーバー間で、データの転送が発生しないことです。
一方、【2】は独立したプロセスとしてバッチ処理を行うことで負荷分散を図ります。また【2】は、オンラインとバッチの実装言語を同じにすることが可能で、ビジネスロジックを共通化しやすいという利点もあります。
加えて、【2】-2の利点は、データの加工処理とデータの更新処理を分けることで、データベースに対するロック時間を短くできることです。ただし、一連の処理(3段階)の間、データに対する変更が加えられないことを前提としています。つまり、「処理対象のデータがどのような状態であるか?」が、とても重要なのです。
起動方法
バッチの起動方法には、以下の2つが考えられます。
【1】随時バッチ
必要な時に都度起動して処理を行う方式です。ジョブスケジューラーが月次集計処理を実行するといったケースがこれに当てはまります。起動のトリガーは、指定された日時・先行ジョブの完了・ファイル受信などさまざまです。リカバリ時などには、手動で起動する場合もあります。
【2】常駐バッチ
バッチ処理プロセスを常駐させておく方式です。これには、一定間隔ごとに未送信リストを確認して登録完了メールを一括送信するという例や、オンラインからのリクエストをトリガーに処理を開始する、などといったものがあります。常駐バッチは常時起動状態にあるためマシンリソースを消費し続けますが、随時バッチのように処理のたびに発生する起動処理がありません。常駐バッチにすることで、毎回バッチ起動時に必要なモジュール(クラスファイルなど)をロードするコストを抑えることができます。よって、頻繁に実行されるバッチ処理については、常駐方式を採用するのも一つの方法です。
並列処理
ハードウェアの進化と共にCPUも高速化、そしてマルチコア化が進んでいます。高スループットが要求される場合には、CPUのマルチコアを活用した処理の並列化を検討する場合があります。
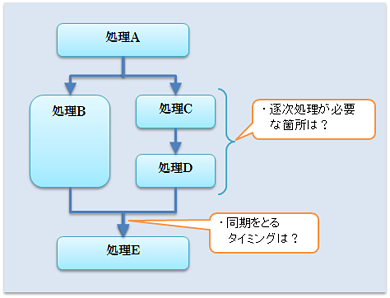
並列化には、[タスク並列]と[データ並列]があります。[タスク並列]は相互に依存しない処理を並列に実行する方式です。下図の例では、処理Bと処理C、Dは相互依存せず、並列しての実行が可能です。タスク並列では、並列処理と逐次処理の見極め、同期をとるタイミングといったことがポイントになります。
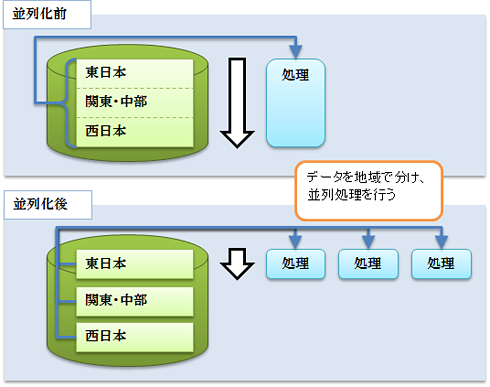
一方、[データ並列]は、データを分割してそれぞれに対して同じ処理を実行します。例えば対象データを地域で分け処理を並列化することで、全体の処理時間短縮を図ります。
またDBMSによっては、データのパーティショニング(区分化)をサポートするものもあります。パーティショニングは1つのテーブルデータを異なるパーティションに分割して配置することで、アプリケーションからは1つのテーブルと見えますが、各パーティションに対する問い合わせのレスポンスはパーティショニングしていない場合と比べて大幅に向上します。データ並列処理とパーティショニングを組み合わせることで、さらなるスループットの向上が見込めます。
- 参考リンク:並列処理プログラミングの基本用語 - 第5回 タスク並列とデータ並列の違い(@IT)
- 参考リンク:Oracleパーティショニング実践講座(1)- パーティショニングは大規模DBの性能向上に効く(@IT)
以上、バッチの実行方式として実行場所・起動方法・並列処理について見てきました。次は、データの特性の観点で検討を進めていきます。
Copyright © ITmedia, Inc. All Rights Reserved.