ディープラーニングの欠点をカバー、多変量データを短時間観測して将来動向を高精度予測――東京大学の研究グループが新理論を構築:短時間多変数の結果を長時間小変数に変換
ディープラーニングでは大量の教師データを集めることが前提となる。だが長期間にわたって時系列データを集めることは難しい。東京大学生産技術研究所の合原一幸教授らの研究グループは、多変数からなる過去の動向を短時間観測したデータを使って、この前提を崩す研究成果を発表した。遺伝子発現量や風速、心臓疾患患者数などの実際の時間データに対して予測を行い、有効性を確認したという。
東京大学生産技術研究所の教授である合原一幸氏らの研究グループは、多変数からなる過去の動向を短時間だけ観測したデータから、ターゲット変数の将来の動向を高精度に予測する新しい数学的基礎理論を構築した。
一般に、生体や経済、電力網のような複雑系では、多数の変数が複雑なネットワーク構造を介して相互に影響する。その結果、システムを構成する各変数の情報が、多数の変数に分散されて保持されることになる。
多変数の値を基に予測するアルゴリズムには、人工知能(AI)の主要技術で静止画像の認識などに高い性能を発揮するディープラーニングがある。
ただしディープラーニングは、学習のために大量の教師データと多大な計算時間を必要とする。さらに時系列データを扱う場合、2つの欠点がある。第一に時系列データのような動的情報の処理に限界があること。第二にそもそも時系列データを長時間計測することが容易ではないことだ。例えば、生物学の研究で遺伝子発現量の時系列データを計測することは極めて困難だ。
こうした複雑系の振る舞いは、数学的には「アトラクター」と呼ばれる状態空間内の安定状態によって記述される。従って、同時に計測した複数の変数の値からアトラクターを推定できれば、それを予測に用いることができる。これが今回の研究の鍵だ。
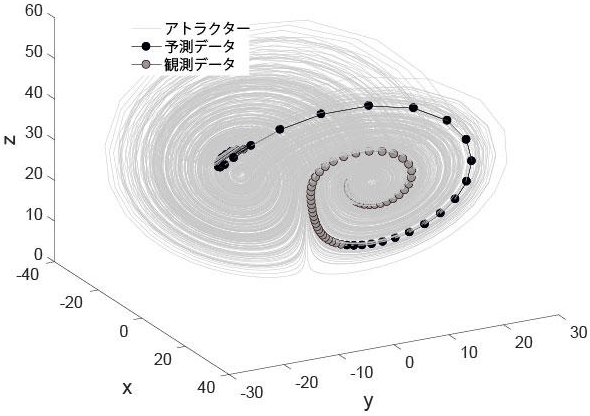
気象モデルのカオスアトラクター上の観測データと予測データの例 細い曲線の集合がアトラクター。その中で観測データに基づいた長期間に及ぶ予測データの振る舞いの例を示したもの(出典:東京大学生産技術研究所)
ランダム分布埋め込み手法で測定時間を「短縮」できる
現在は、時系列データを計測するよりも、一度に多種多数のデータを同時計測する方が容易な場合もある。例えば、IoT(Internet of Things)といった計測技術の進歩により比較的容易に、例えば2万以上の遺伝子からなる人のゲノムについて、得られたサンプルからそれぞれの遺伝子の発現量を計測可能だ。
合原氏らは、ある時刻の多数の観測変数についてその値からランダムに変数を選んでその時点でのアトラクターの状態を推定する「ランダム分布埋め込み(Randomly Distributed Embedding:RDE)」手法を考案した。
この手法に基づいて特定のターゲット変数の将来予測値を多数構成し、統計処理することで、精度が高く、より長時間の予測を可能とした。この手法では対象の数理モデルを必要としないため、研究グループでは、データの観測期間が短いときでも数理的処理によって予測システムを構築できる利点があるとしている。
研究グループでは、考案した手法を遺伝子発現量や風速、心臓疾患患者数などの予測に実際に応用してその有効性を確認したという。経済や医学、エネルギーなどさまざまな分野で、短時間の観測データから将来の動向を予測する高度な予測技術を用いたAIシステムの構築が可能になるとした。
今回の研究論文は米国科学アカデミー紀要(PNAS)のオンライン速報版で公開される予定(DOI:DOI10.1073/pnas.1802987115)。発表者には合原氏の他、蘇州大学数学科学学院の馬歡飛氏、東京大学生産技術研究所の冷思阳氏、復旦大学数学科学学院の林偉氏、中国科学院上海生命科学研究院の陳洛南氏が名を連ねる。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 米ライス大学の研究者、ディープラーニングを用いたコーディング支援システム「Bayou」を開発
米ライス大学の研究者、ディープラーニングを用いたコーディング支援システム「Bayou」を開発
米ライス大学の科学者が、ディープラーニングを利用したコーディング支援システム「Bayou」を開発した。BayouはプログラマーがAPIを使いこなす際に特に役立つ。 日本トップクラスのAI研究者が語る、人工知能の歴史と産業との関係
日本トップクラスのAI研究者が語る、人工知能の歴史と産業との関係
2016年6月14日に開催された金融庁の「フィンテック・ベンチャーに関する有識者会議」第2回では、人工知能(AI)研究の第一人者である松尾豊 東京大学大学院 准教授がプレゼンテーションを行った。 TensorFlowを使った機械学習を論文抽出に適用、ヒントは大学入試問題対策の裏ワザ
TensorFlowを使った機械学習を論文抽出に適用、ヒントは大学入試問題対策の裏ワザ
医師が、ディープラーニングフレームワークのTensorFlowを自ら用い、診療ガイドラインの作成における「心の折れる作業」である論文スクリーニング作業を自動化。効果を実証した。ヒントは共通一次試験の対策本にあった。