[Python入門]Pythonってどんな言語なの?:Python入門(1/2 ページ)
機械学習に取り組んでみたいという人に(そうでない人にも)向けて、Pythonプログラミングを基礎からやさしく解説する連載をPython 3.10に合わせて改訂します。
* 本稿は2019年4月2日、2021年7月2日、2022年4月15日に公開/改訂されました。その後、2023年9月11日にPython 3.11.5でのサンプルコードの動作を確認しました。
本連載は、これからPythonを使って機械学習に取り組んでみようとするプログラミング初心者と一緒に、Python言語とプログラミングの基礎の基礎を学んでいこうというものだ。
幸いなことに、現在では、時間をかけて環境を準備しなくても、Web上で簡単にPythonのコードを書いたり、実行したり、その結果を表示したりできる環境が幾つもある。そうした手軽な環境を使って、Pythonと機械学習の世界へ「エイヤッ」と飛び込める程度の知識を身に付けるのが本連載の目的だ。
PythonはAI開発で広く使われているというが、なぜなのだろうか。今回はまず、Pythonがどんな言語なのか、その特徴をかいつまんで紹介していこう。
「Python入門」について
本連載は、Pythonに興味のある方を対象として、四則演算、変数、整数や文字列などの基本となるデータ型、for文/while文/if文などの制御構造、関数の呼び出し方や定義の方法、リスト/タプル/辞書/集合などのコンテナオブジェクトのようなPythonを使ってプログラムを書く上で必須となる基本知識から、モジュールやパッケージ、クラス、例外、ファイル/ディレクトリ操作、スクレイピングの基礎、ジェネレーターやデコレーターなど少し応用的な話題までを幅広く取り上げています。
詳しくは以下の連載インデックスを参照してください。
Pythonとは
Pythonは、もともと「Amoeba」という分散オペレーティングシステムのシステム管理を行う目的で、Guido van Rossum氏が開発したプログラミング言語だ。バージョンが上がるに連れさまざまな機能が追加され、本稿執筆時点(2022年4月13日)での最新バージョンは3.10.4となっている。現在ではPythonは、初心者から職業プログラマーまでに広く使われており、(本フォーラムの主なテーマである)機械学習だけではなく、Webアプリ開発などでも使われている。その特徴としては次のようなことが挙げられる。
- シンプルで覚えることが少ない構文
- 1行で多くの処理を記述可能
- 標準ライブラリとして、言語に多くの機能があらかじめ用意されている
- さらに幅広い用途に使えるPython向け外部ライブラリが豊富に存在している
以下ではこれらについて少し詳しく見てみよう。なお、現在、Pythonにはバージョン2とバージョン3の2系統が存在しているが、バージョン2については2020年にサポートが終了している。そのため、本連載ではバージョン3を対象とする。Python 3.9や3.10など、比較的新しいバージョンで追加された機能については、そのことを明記した上で取り上げることにする。
シンプルで覚えることが少ない構文
突然だが、Pythonには哲学がある*1。その幾つかは次のようなものだ。
- 複雑であるよりもシンプルな方がよい
- 何かをする方法は(できることなら)誰もが分かるものが1つだけ
このようにPythonは、「シンプル」であることを重要視している。そしてこの哲学により、Pythonでは、プログラマーが覚えなければならない構文規則が他の言語と比べて少ない。そのため、初心者であっても、最初に覚えなければならないPythonの文法はそれほど多くない。入門者でもハードルが低くとっつきやすい言語、それがPythonだ。
*1 これらは「The Zen of Python」としてまとめられている(Pythonの対話環境で「import this」を入力しても表示される)。日本語訳は「Python プログラミングの基本ルール (The Zen of Python)」「プログラマが持つべき心構え (The Zen of Python)」などを参考にされたい。
1行で多くの処理を記述可能
「1行で多くの処理を記述可能」というのは、「何かの処理を行うために書かなければならないコードが少なくて済む」ということだ。これを「記述性が高い」などと表現することもある。例を挙げよう。Pythonには「リスト」というたくさんのデータをまとめて管理するためのデータ構造がある。これを利用して掛け算の九九の表を作ってみよう。以下は「素直」なコードの例だ(コードの内容を理解する必要は全くない)。
result = []
for num1 in range(1, 10):
tmp = []
for num2 in range(1, 10):
tmp.append(f'{num1 * num2:2}')
result.append(tmp)
for row in result:
print(', '.join(row))
詳しくは説明しないが、これは「for文」を二重に使って、「1」と「1」〜「9」の掛け算の結果をリストに保存し、次に「2」と「1」〜「9」の掛け算の結果をリストに保存して、……という処理を行うものだ。「9×9」の計算まで終わったら、掛け算の結果をカンマで区切って表示している。実行結果を以下に示す(興味のある方は、次ページの「Pythonを学ぶための環境」を見ながら、Python環境を作成し、実際にコードをコピー&ペーストして実行してみるといいだろう)。
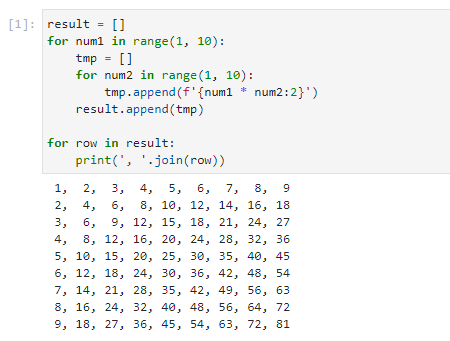
実はPythonでは、これと同じことを以下のコードでも行える。
result = [[f'{num1 * num2:2}' for num2 in range(1, 10)] for num1 in range(1, 10)]
for row in result:
print(', '.join(row))
1つ目のコードでは6行あった部分が今度は1行だけになっている。これは、Pythonが標準で持っている「リスト内包表記」と呼ばれる機能を使ったものだ(難解なコードだが、興味のある方は第16回「リストの基本」の「リスト内包表記」を参照されたい)。このように「素直に考えるとそれなりの量が必要になるコード」でも「便利な機能を使うことで、わずかな行数で済ませられる」のがPythonのよいところの一つだ。これについては後でまた別の例を見てみよう。
C言語とPythonで書いた「Hello World」
余談にはなるが、C言語のmain関数に相当するものが不要であることも、Pythonのプログラムがシンプルになる一つの要因といえる。例えば、C言語で「Hello World」と呼ばれるプログラムを書くと次のようになる(「Hello World」プログラムについては次回に見ていく)。
#include <stdio.h>
int main(void) {
printf("Hello World\n");
return 0;
}
これに対して、Pythonで書いた最もシンプルな「Hello World」プログラムは次のようになる。
print('Hello World')
プログラミング言語にはそれぞれ特徴があるので、「Pythonの方がシンプルでよい」とは一概にはいえないことには注意する必要があるが、それでもプログラミング初心者にとってはPythonの方が親しみやすいということはできるだろう。
豊富な標準ライブラリと外部ライブラリ
「1行で多くの処理を記述可能」「記述性が高い」というPythonの特徴を支えるのは、今見たようなPythonが標準で持つ機能だけではない。Pythonの言語仕様には含まれていないが、Pythonに標準で付属している「標準ライブラリ」というものがある。これはPythonをインストールするだけで使えるようになるもので、Python公式サイトの「Python 標準ライブラリ」ページを見るとどれほど多くのものが「標準ライブラリ」としてPythonに添付されているかが分かる。そのうちの幾つかのカテゴリーを挙げるだけでも以下のようなものがある(これらのカテゴリーの下に、幾つものライブラリが含まれている)。
- 数学関連
- ファイル操作およびさまざまなフォーマットのファイルの操作
- データの永続化
- データ圧縮/アーカイブ
- 並列処理
- ネットワーク処理
- インターネット関連
- GUI(グラフィカルユーザーインタフェース)
つまり、Pythonをインストールするだけでも、標準ライブラリの機能を使って「自分では複雑なコードを書く必要なし」に「高度な処理を短いコード」で書けるというわけだ。
また、Pythonに標準で付属はしていないものの、別途インストールすれば使えるようになる「外部ライブラリ」も重要だ。
特に、機械学習と聞いてよく出てくるであろう「TensorFlow」「PyTorch」「NumPy」など、Python向けに提供されている「外部ライブラリ」は非常に多く、これが最近のPython人気を盛り上げている一つの要因となっている。それ以外にもWebアプリケーションを開発するための「Django」「Flask」といったライブラリもある。「自分がやりたいこと」に合わせて、外部ライブラリを活用することで、すぐにでも本格的なプログラミングの世界に足を一歩踏み出せるのが、Pythonを使うことの大きなメリットといえる。
外部ライブラリを使うと、機械学習プログラミングがどう簡単になるのか。詳しいコード解説などは後にゆずるとして、ここではその雰囲気を掴んでもらうために、具体的な例を紹介しよう。
Pythonの外部ライブラリを使えば、単回帰分析を行うコードも数行に
ここでは以下に示すサンプルの座標群を通る最も適切な一次関数(「y = ax + b」という数式の係数「a」と切片「b」)を推測するコードを紹介する。機械学習の典型的な目的の一つは、大量のデータから、それに適用可能な数式モデルを見出すことだ。これはその最もシンプルな単回帰分析の例である。
最初は外部ライブラリを使わない方法(手間がかかる方法)でプログラムを書き、次に外部ライブラリを使うと、それがどう変わるのかを見てみよう。先ほどと同じく、興味のある方は、次ページの「Pythonを学ぶための環境」を見ながら、Python環境を作成し、コードをコピー&ペーストして実行してみるといいだろう。
| X座標 | Y座標 |
|---|---|
| -0.03 | 0.88 |
| 0.78 | 2.45 |
| 2.07 | 2.43 |
| 2.77 | 4.07 |
| 4.10 | 5.49 |
| 5.38 | 6.46 |
| 5.99 | 7.02 |
| 6.84 | 8.27 |
| 8.12 | 8.70 |
| 8.89 | 10.23 |
| 9.43 | 10.65 |
| サンプルの座標群 | |
これらの座標を図にプロットしたのが以下だ。
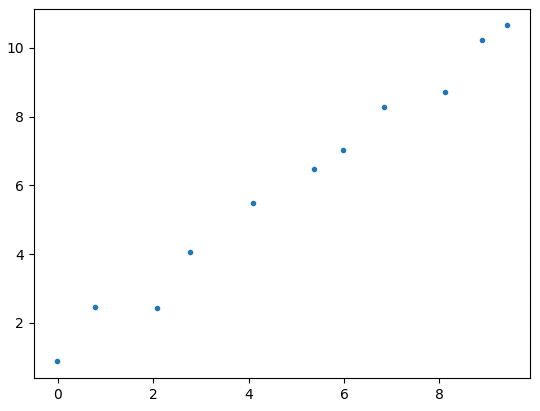
以下は、「最小二乗法」と呼ばれるアルゴリズムを使って、座標群を与えると、それらを表す最適な一次関数を推測するプログラムを、外部ライブラリを使わずに、Python言語で素直に書いたものだ。ただし、コードの内容を理解する必要はない。見てほしいのはコードの量だ。かなりの量のコードに見えるかもしれない。
def fit(x, y):
x_mean = sum(x) / len(x)
y_mean = sum(y) / len(y)
x_centered = [item - x_mean for item in x]
y_centered = [item - y_mean for item in y]
xy = [item_x * item_y for item_x, item_y in zip(x_centered, y_centered)]
xx = [item * item for item in x_centered]
sum_xy = sum(xy)
sum_xx = sum(xx)
a = sum_xy / sum_xx
b = y_mean - a * x_mean
return (a, b)
# サンプルデータ
x = [-0.03, 0.78, 2.07, 2.77, 4.10, 5.38, 5.99, 6.84, 8.12, 8.89, 9.43]
y = [0.88, 2.45, 2.43, 4.07, 5.49, 6.46, 7.02, 8.27, 8.70, 10.23, 10.65]
# 一次関数の推測を行う
print(fit(x, y)) # 出力:(1.0037317148789446, 1.1006562375889226)
実際にこのプログラムを実行してみると、係数「a」の値は「1.0037317148789446」で、Y軸の切片である「b」の値は「1.1006562375889226」だと答えが返ってくる。

そして、得られた値から先ほどの図に一次直線を追加したのが以下だ。座標群を貫く直線がうまい具合に引かれていることがわかる。
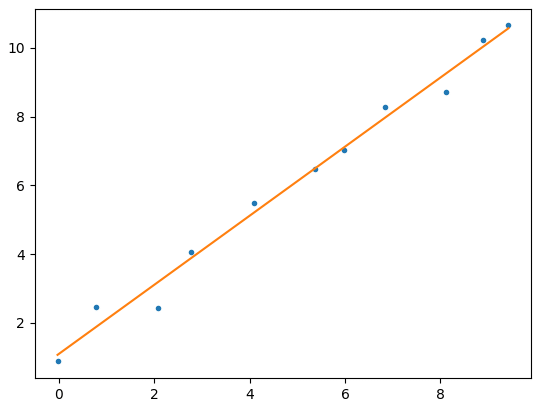
このコードは、「最小二乗法のアルゴリズムは?」「Python のzip関数の使い方は?」などをWebで再確認しながら筆者が書いたものだ。今どきのコーディング作業といってよいだろう。Web検索で簡単にいろいろと調べられるようになったのは便利とはいえ、調べ物をしながらのコーディングには手間と時間がかかる。
しかし同じ処理を、前出の外部ライブラリであるNumPyを使って書き直すと次のようにシンプルになる。
import numpy as np
x = [-0.03, 0.78, 2.07, 2.77, 4.10, 5.38, 5.99, 6.84, 8.12, 8.89, 9.43]
y = [0.88, 2.45, 2.43, 4.07, 5.49, 6.46, 7.02, 8.27, 8.70, 10.23, 10.65]
print(np.polyfit(x, y, 1)) # 出力:[1.00373171 1.10065624]
いかがだろう。20行ほどあったプログラムコードが10行以下になった。コードを書いたり調べ物をしたりする手間が省けるのはもちろん、実績のある外部ライブラリを使えば、ソースコードの見通しもよく、バグが入るスキもグンと小さくなる。これが外部ライブラリを使うことの大きなメリットだ。
NumPyには、「座標群を与えると、それらを表す適切な一次関数を推測する」ための既成のコードが含まれている。それが一番下の行の中に書かれている「np.polyfit関数」だ。当然ながら、両方のコードの最下行にある「出力:」という部分を見ると、結果が(ほぼ)同一であることも確認できる。外部ライブラリを使うことで、品質の高いコードを少ない手間で記述し、目的を達成できるわけだ。
今紹介したnp.polyfit関数には、最初に見たコードで行っている処理(にプラスして、さらに多くの処理)が詰め込まれていて、1行で「座標群を与えて、それらを表す適切な一次関数を推測する」という概念を表現できている。このように、わずかなコードで「複雑な処理を書き表せる」ことが、先ほども述べた「1行で多くの処理を記述可能」「記述性が高い」ということであり、Pythonの大きな特徴の一つといえる。そして、「記述性の高さ」を支えるのが、Pythonに標準で付属する「標準ライブラリ」と、Python向けに提供されている豊富な外部ライブラリということだ。
ここではNumPyを例に挙げたが、他のライブラリも同様だ。機械学習を行うプログラムを「より少ないコード」で、「よりシンプル」に、「より効率的に」表現できるようにするライブラリがPythonをターゲットとして多数提供されている。「機械学習ならPython」といわれる理由がこれだ。
多くの人が機械学習プログラムを開発しようとPythonの世界に集まることで、「Python+機械学習」の世界はどんどん進化して、新たな技術やツールもどんどん生まれて、ユーザーはさらに快適に機械学習に取り組めるようにもなる。Pythonが唯一無二ということではないにしても、機械学習プログラムの開発を目指す人には、Pythonは最有力の言語だといえるだろう。
なお、Pythonには他にも「可読性が高い」「スクリプト言語」「オブジェクト指向をサポート」などの特徴があるが、これらについては連載の中で必要に応じて触れていくことにしよう。
Copyright© Digital Advantage Corp. All Rights Reserved.