[Python入門]ファイル操作の基本:Python入門(2/3 ページ)
テキストファイルを例に、ファイルのオープン、ファイルに対する読み込みや書き込み、ファイルのクローズなど、ファイル操作の基本を取り上げる。
ファイルの内容を読み込むメソッド
テキストファイルの内容を読み込むメソッドには以下がある(引数を指定しなかった場合。これら3つのメソッドには、引数として読み込むデータ量をバイト単位で指定できるが、これについては本稿では解説を省略する)。
- readメソッド:ファイルの内容を全て読み込んで、それを1つの文字列として返送する
- readlineメソッド:ファイルから1行を読み込んで、それを1つの文字列として返送する
- readlinesメソッド:ファイルの内容を全て読み込んで、各行を要素とするリストを返送する(ただし、readlinesメソッドを使って反復処理を行うよりも、効率的な方法がある。後述)
重要なのは、Pythonでテキストファイルを扱うときには(読み込み時も書き込み時も)常に文字列がやりとりされる点だ。テキストファイルから読み込んだ値は全て文字列であり、逆にテキストファイルへ書き込むのは全て文字列である必要がある。
以下では、各メソッドの使い方について見ていこう。ここでは各行に行番号を付けて、表示する処理を3つのメソッドを使って実現してみる。これはテキストファイルを処理する際には、行ごとに何らかの処理を行うことがよくあるからだ。
readメソッド
上で述べた通り、readメソッドはファイルの内容を全て読み込んで、それを1つの文字列として返す(読み込むサイズを指定することも可能。この場合はファイル末尾に達するか、指定されたサイズに到達するまで読み込みを行う)。実際に試してみよう。
lines = myfile.read()
lines
これを実行すると、次のようになる。
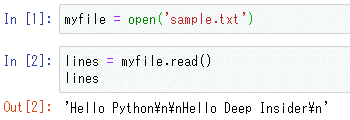
出力を見ると、改行コード(\n)を途中に挟む形で全ての行が1つの文字列にまとめられていることが分かる。各行に行番号を付けて出力するには、文字列のsplitメソッドを使い改行コードを区切りとして文字列を分割し、分割された文字列を要素とするリストを得て、それらを反復処理すればよい。これをコードにまとめたものが以下だ(enumerate関数は要素のインデックスと要素自身を反復するために使っている)。
for count, line in enumerate(lines.split('\n')):
print(f'{count}: {line}')
以下に実行結果を示す。行番号付きでファイルの内容が表示されたことを確認してほしい。
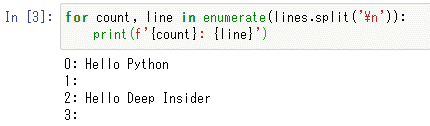
ここでもう一度readメソッドを呼び出すとどうなるだろう。
lines = myfile.read()
lines
すると、もう何も読み出されないことが分かる(空文字列が返されている)。これは既に述べた通り、readメソッドによりファイルの内容が全て読み込まれた結果、ファイル位置がファイル末尾となり、それ以上読み込むデータがないからだ。
ここまでで、readメソッドの動作は確認できた。つまり、ファイルの扱いが終了したと考えられる。ファイルを使い終わったら、closeメソッドでそれを閉じる必要がある(closeメソッドは引数がないメソッド)。そこで、readlineメソッドの説明に移る前に一度、ファイルを閉じておこう。
myfile.close()
readlineメソッド
次に、readlineメソッドについて見る。先ほども述べたが、これはファイルから1行(改行コードまで)を読み出して、それを戻り値とする(読み込みを行うサイズも指定できる。その場合には、改行コードに遭遇するか、指定されたサイズに達するまで読み込みを行う)。実際に呼び出してみよう(直前でファイルをクローズしているので、もう一度open関数で開く必要があることに注意)。
myfile = open('sample.txt')
line = myfile.readline()
line
これを実行すると、次のようになる。
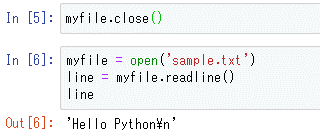
上の画像を見ると分かるが、戻された文字列の末尾に改行コードが付いていることには注意しておこう。
ここでもう一度、readlineメソッドを呼び出すと、今度は次の行が読み込まれる。先ほども述べたが、readlineメソッドは「1行を呼び出して、ファイル位置を次の行の先頭に移動する」という処理を行っていると考えられる。
line = myfile.readline()
line
先ほどと同じ行を実行すると、次の行が読み出されるのが分かる。ただし、2行目は空行なので、改行コードのみが表示される。
なお、ファイル位置がファイル末尾までくると、それ以降のreadlineメソッド呼び出しでは空文字列「''」が返送される。ここまででreadlineメソッドの動作は確認できたので、いったん、ファイルを閉じておこう。
myfile.close()
では、readlineメソッドを利用して、先ほどと同じように行番号付きで表示をしてみよう。今度はfor文ではなく、whileループを使う。
myfile = open('sample.txt')
count = 0
line = myfile.readline()
while line != '': # ファイル末尾でlineの内容が''になるまでループする
print(f'{count}: {line}', end='')
count += 1
line = myfile.readline()
myfile.close()
注意点としては、先ほども述べた通り、文字列末尾に改行コードが付いていることだ。そのため、print関数呼び出しでは名前付き引数endに空文字列''を指定して、最後に改行コードを出力しないようにしている。
以下に実行結果を示す。
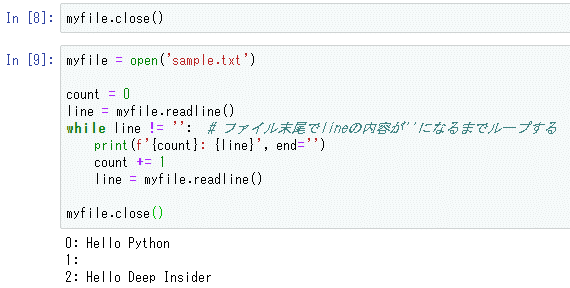
readメソッドの例とは異なり、4行目が出力されていないのは、ファイルの最後が空行であり、その場合には既に述べたようにreadlineメソッドは空文字列を返送し、ここではそのことを当てにしてwhileループを実行しているからだ。
上のコードを先ほどのreadメソッドと比べると行数が増えているが、これはreadlineメソッドが1行ごとにファイルの内容を読み込むからだ(enumerate関数が使えないこともある)。1行ごとに読み込みはするが、各行を反復処理するためには上のような書き方をする必要がある。readメソッドであれば、改行コードで行を分割することで、各行を要素とするリストが得られるので、それを使って反復処理できるのも上で見た通りだ。ただし、そうであれば次に紹介するreadlinesメソッドが同じことをしてくれる。さらにその後で紹介するファイルオブジェクトを使った反復処理の方がさらにシンプルだ。
readlinesメソッド
readlinesメソッドは、readメソッドと同じくファイルの内容を全て(あるいは指定されたサイズだけ)読み込むが、各行の内容を要素とするリストを作成して、それを戻り値とする。従って、反復処理を簡単に記述できる。以下に実際のコードを示す(実行結果は省略する)。
myfile = open('sample.txt')
for count, line in enumerate(myfile.readlines()):
print(f'{count}: {line}', end='')
myfile.close()
readlineメソッドと同様に、要素となる文字列の末尾には改行コードが含まれていることにも注意しよう(上では名前付き引数endに空文字列''を指定している)。
また、readメソッドと同様に、readlinesメソッドでは基本的には全ての内容が一度に読み込まれる点には注意しよう。現代のコンピュータであれば問題となることはそれほどないだろうが、メモリ消費という観点ではreadメソッドとreadlinesメソッドは、readlinesメソッドと比べて、多くのメモリを消費する可能性が高い。
これらのメソッドの使い分けの指針としては次のようなことが考えられる。まず、ファイルの内容が定形的で1行に決まったデータが含まれていて、それらを反復的に処理したいのであれば、readlineメソッドや次に紹介するファイルオブジェクトを使うのが適しているだろう。
対して、対象となるファイルがHTMLファイルのように定形的ではなく、どこに改行コードが含まれるかが一定ではない場合やデータファイルが自由フォーマットで1件のデータが複数行にわたって書かれている場合などは、readメソッドやreadlinesメソッドを使って、まとまった量のデータをあらかじめ読み込んでおき、その後、独自の手順でそれらを処理するのがよい。
あるいはファイルではなくネットワーク経由でデータを(ファイルのようなものとして)取り扱うのであれば、ネットワーク接続を長時間にわたって維持しながら、1行分のデータを反復的に取り出すよりは、readメソッドやreadlinesメソッドのような手段で一度にそれらを取得してしまった方が安全かもしれない。
ここまで、read/readline/readlinesメソッドを使って、テキストファイルの内容を読み込んで、各行を処理する手順を見てきたが、こうした各行に対する反復処理は実はファイルオブジェクトを使用することでもっと簡単に行える。
ファイルオブジェクトを使用した反復処理
実は、ファイルオブジェクトは反復可能オブジェクトとしても使えるので、テキストファイルをオープンして、その各行を処理するのであれば、これをfor文に与えてしまうのが一番簡単だ。以下にコードを示す(実行結果は省略する)。
myfile = open('sample.txt')
for count, line in enumerate(myfile):
print(f'{count}: {line}', end='')
myfile.close()
この書き方は、先ほどのreadlinesメソッドと同様に簡潔に反復処理を行える一方で、readlineメソッドと同様に1行ずつの読み込みを行うことから、メモリに掛ける負荷が低くなるという点で優れている。そのため、テキストファイルをオープンして、各行に対して一定の処理を行いたいというときにはお勧めだ。
次に、テキストファイルへの書き込みについて見ていこう。
Copyright© Digital Advantage Corp. All Rights Reserved.