PyTorchでオートエンコーダーによる画像生成をしてみよう:作って試そう! ディープラーニング工作室(2/3 ページ)
画像生成の手始めとして「オートエンコーダー」と呼ばれるニューラルネットワークを作って、MNISTの手書き数字を入力して、復元してみましょう。
画像を生成してみた
ここではエンコーダーをEncoderクラスとして、デコーダーをDecoderクラスとして、それらを使用するオートエンコーダーをAutoencoderクラスとして定義しましょう。実際のコードは次のようになります。なお、今回の内容はこのノートブックで公開しています。
import torch
from torch.utils.data import DataLoader
import torchvision
from torchvision import transforms
from torchvision.datasets import MNIST, CIFAR10 # CIFAR10もインポートしておく
import numpy as np
import matplotlib.pyplot as plt
class Encoder(torch.nn.Module):
def __init__(self, input_size):
super().__init__()
self.fc1 = torch.nn.Linear(input_size, 512)
self.fc2 = torch.nn.Linear(512, 64)
self.fc3 = torch.nn.Linear(64, 16)
self.fc4 = torch.nn.Linear(16, 2)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.relu(self.fc3(x))
x = self.fc4(x)
return x
class Decoder(torch.nn.Module):
def __init__(self, output_size):
super().__init__()
self.fc1 = torch.nn.Linear(2, 16)
self.fc2 = torch.nn.Linear(16, 64)
self.fc3 = torch.nn.Linear(64, 512)
self.fc4 = torch.nn.Linear(512, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.relu(self.fc3(x))
x = torch.tanh(self.fc4(x)) # -1〜1に変換
return x
class AutoEncoder(torch.nn.Module):
def __init__(self, org_size):
super().__init__()
self.enc = Encoder(org_size)
self.dec = Decoder(org_size)
def forward(self, x):
x = self.enc(x) # エンコード
x = self.dec(x) # デコード
return x
EncoderクラスとDecoderクラスは全結合型のニューラルネットワークとなっていること、各層の出力が段階的に減っていく/増えていく点には注意してください。これが上で述べた段階亭に次元削減(次元増加)を行う部分に合致します。上のコードだと、エンコーダーでは「784(MNISTの手書き数字の次元数)→512→64→16→2」のように次元が削減され、デコーダーでは「2→16→64→512」のように次元が増加していきます。果たして、784次元のデータを2次元のデータに削減できるかどうかは、この後の学習結果で分かるでしょう。
なお、MNISTデータセットの手書き数字だけではなく、CIFAR-10の画像も扱えるようにすることを狙って、Encoderクラスへの入力数とDecoderクラスからの出力数を指定できるようにしてあります(Autoencoderクラスのインスタンス生成時に指定する値が、Encoderクラスへの入力/Decoderクラスからの出力の数となります)。冒頭のimport文でもそのためにCIFAR10モジュールをインポートしています。
各クラスでやっていることは一目瞭然なので、ここでは説明は省略します。
次にMNISTデータセットの読み込みと、データローダーを定義しましょう。これはPyTorchのいつものコードです。テスト用のデータセット/データローダーについてもここでは定義しておきます。バッチサイズは50として、ミニバッチで学習する際に読み込むデータ数が50個となるように設定しています。
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = MNIST('./data', train=True, transform=transform, download=True)
testset = MNIST('./data', train=False, transform=transform, download=True)
batch_size = 50
trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True)
testloader = DataLoader(testset, batch_size=batch_size, shuffle=False)
画像が復元できているかを確認するには、MNISTの手書き数字を表示できる必要もあります。ここでは手抜きをして、PyTorchの公式サイトで提供されている「TRAINING A CLASSIFIER」ページにあるimshow関数を拝借(して、少し改変)することにしました。以下にそのコードと、訓練データから50個を取り出して、それを表示するコードを示します。
def imshow(img):
img = torchvision.utils.make_grid(img)
img = img / 2 + 0.5
npimg = img.detach().numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
iterator = iter(trainloader)
x, _ = next(iterator)
imshow(x)
実行結果を以下に示します。
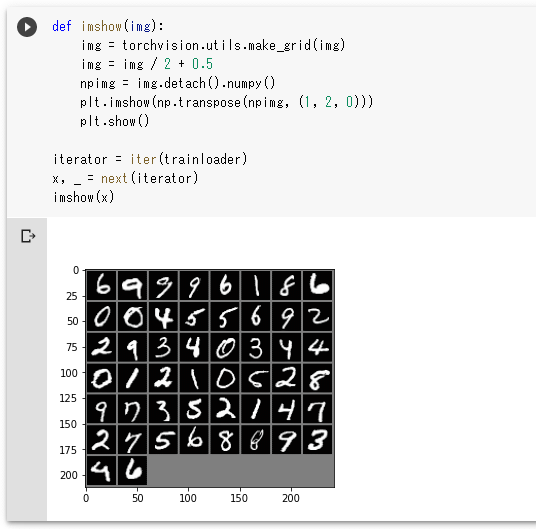
これでもともとのMNISTの手書き数字と、ニューラルネットワークモデルからの出力を画像として表示する準備ができました。次は、実際に学習を行うコードです。このコードも関数化して、この後、CIFAR-10データセットを使った学習でこの関数を呼び出すだけで済むようにしました。
def train(net, criterion, optimizer, epochs, trainloader):
losses = []
output_and_label = []
for epoch in range(1, epochs+1):
print(f'epoch: {epoch}, ', end='')
running_loss = 0.0
for counter, (img, _) in enumerate(trainloader, 1):
optimizer.zero_grad()
img = img.reshape(-1, input_size)
output = net(img)
loss = criterion(output, img)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / counter
losses.append(avg_loss)
print('loss:', avg_loss)
output_and_label.append((output, img))
print('finished')
return output_and_label, losses
input_size = 28 * 28
net = AutoEncoder(input_size)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)
EPOCHS = 100
output_and_label, losses = train(net, criterion, optimizer, EPOCHS, trainloader)
ここでは1エポック(6万個のデータを使った学習)が終わるたびに、その時点でニューラルネットワークへ入力された手書き数字(ミニバッチで読み込まれる50個)と、そこから得られた出力とをリストoutput_and_labelに保存するようにしました。こうしておけば、後からエポックが終わった時点でどんな手書き数字が出力されたかを確認できるからです。
これを実行すると、次のようにズラズラとエポックごとの平均損失(今回は、そのエポックで得られた損失の総和をミニバッチの回数で除算しています)が表示されます。なお、実際にこのコードを実行すると、学習が終わるまでには20〜30分ほどかかることには注意してください。

「finished」と表示されたら、学習完了です。いつものように損失を表示してみましょう。
plt.plot(losses)
実行結果を以下に示します。
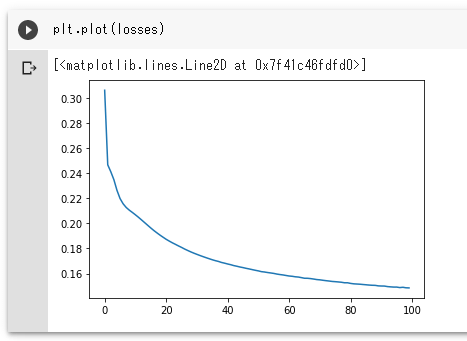
緩やかではありますが、学習は進んだようですね。とはいえ、実際にMNISTの手書き数字を復元できたかは、実際にモノを見てみないと分かりません。そこで、リストoutput_and_labelに保存しておいた出力と元画像のうち、最後のものを実際に画面に表示してみましょう。これには先ほど定義したimshow関数を使います。
output, org = output_and_label[-1]
imshow(org.reshape(-1, 1, 28, 28))
imshow(output.reshape(-1, 1, 28, 28))
実行結果を以下に示します。

ボヤッとしたり、他の文字に復元されたり、はたまた何かわからないものになっていたりするものもありますが、これが今回の学習の結果です。ここからはニューラルネットワーク内部の構成を変更したり、その他のハイパーパラメーターを調整したりすることで、精度が上がるかもしれませんが、ここではそこまではしないことにします。とはいえ、ボケていることを除けば、それなりに復元できていると自己満足したいところです。
筆者が原稿執筆時に、復元された文字と元の手書き数字とを比べていたときに、「4」と「9」は復元後の入れ違いが多いこと(上図だとはっきりしませんが「7」もそうした傾向があります)、同様なことが他の文字のグループにも見られるという印象を受けました。これらから考えられるのは、数字を手書きしたときには、ある文字と別の文字で似た特徴が見られる場合があるということです(例えば、「4」と「9」はコンピューターで使用されるフォントでは明らかに異なるように表示されますが、手書き数字だと「上部に線で囲まれた領域があり、右下には縦方向に延びた線がある」という共通の特徴が出てくることがあるということです。このような特徴をニューラルネットワークモデルが読み取った結果、両者を混同してしまうといったことになるのではないでしょうか)。
今度は、エポックが進むごとの復元の度合いを確認してみましょう。
for img, _ in output_and_label[0:10:2]:
imshow(img.reshape(-1, 1, 28, 28))
以下は、実行結果から画像を抜き出したものです。

最初のエポックが終わった時点(左上の画像)ではモヤモヤっとしたものが表示されているだけですが、下の2つの画像では何やら文字っぽいものが表示されるようになりました。学習が進むたびに、復元の精度が上がっていることが何となく感じられるのではないでしょうか。
上のコードのfor文でスライスを指定しているところを変更すれば、10個のエポックごとの復元の度合いなども確認できるので、興味のある方は試してください。
次にテストデータを、このニューラルネットワークモデルに入力してみましょう。果たして、学習には使っていない未知のデータについても、このニューラルネットワークモデルはうまいこと対応できるのでしょうか。
iterator = iter(testloader)
img, _ = next(iterator)
img = img.reshape(-1, 28 * 28)
output = net(img)
imshow(img.reshape(-1, 1, 28, 28))
imshow(output.reshape(-1, 1, 28, 28))
実行結果を以下に示します。

先ほど見た、学習後の出力と元画像と同様、ある程度の復元はできているといえるのではないでしょうか。
Copyright© Digital Advantage Corp. All Rights Reserved.