Dataset Search:Googleによる「データセット検索」サイト:AI・機械学習のデータセット辞典
世界中のデータセットがググれる(=Google検索できる)「Dataset Search」を紹介。検索結果のフィルタリングや、日本語対応、対象ページを開く方法、内容記載などについて言及する。
データセット検索サイトとは?
Dataset Searchは、2018年9月からグーグル(Google)が提供しているサイトの一つで、世界中からデータセットを検索できる(=ググれる)。「機械学習で利用するデータセットを手軽に探したい」という場合に、最初に実行してみるツールとして非常に有用である。通常のGoogle検索では、例えば「PyTorch cats dogs images classification」などのようなキーワードを入れて検索することになるだろうが、その結果、必ずしもデータセットのみがヒットするわけではない。それと比べると、データセットのみを効率的に表示してくれるので便利である。
データセット検索
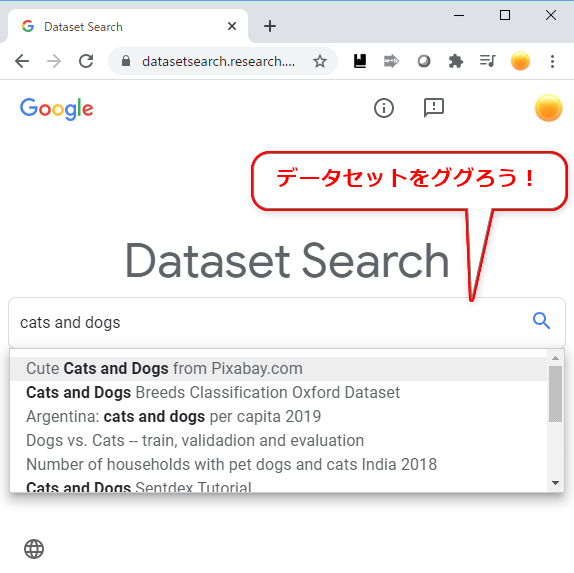
例えば図1は、Dataset Searchで実際にデータセットを検索しようとしているところである。
検索結果の表示
「cats and dogs」で検索してみたところ、図2のように表示された。

左側に検索結果のリストが表示される。リストから1つの項目を選択すると、その内容が右側に表示される。この場合は、import tensorflow_datasets as tfdsというコード例からも分かるように「www.tensorflow.org」(TensorFlow Datasets)内のデータセットが表示されている。
左側には、Kaggleのデータセットが大量に表示されているのが分かる。Dataset Searchでは、Kaggleのデータセットがよくヒットする。その理由は恐らく、Kaggle社自体が2017年にグーグルに買収された企業であり、データセット検索に対応するための「schema.org規格準拠のメタデータ」がページ内に標準実装されているためだろう。メタデータについて詳しくは「データセット ― Google検索デベロッパー ガイド」と「FAQ:データセットの構造化データマークアップ ― Search Console Community」を参照してほしい。なお、このメタデータに対応すれば、各個人が作成したデータセットであっても、Dataset Searchにヒットしやすくなると考えられる。
検索結果のフィルタリング
また、図2の上部には、図3に示すようなフィルターが配置されている。これにより、(Google検索と同様に)検索内容をカスタマイズして結果をフィルタリングできる。

日本語対応について
ちなみにDataset Searchは、もちろん日本語に対応している。図4は「くずし字」で検索して、左側の一覧から[KMNISTデータセット]を選択した例である(参考:「KMNIST/Kuzushiji-MNIST:日本古典籍くずし字(手書き文字)データセット」)。

対象ページを開くには
選択中の検索結果の対象ページを開くには、タイトルの下にある青いボタンをクリックすればよい。図4であれば[探す: codh.rois.ac.jp]ボタンを、前掲の図2なら[探す: TensorFlow Datasets]/[探す: Kaggle]ボタンをクリックする。
データセット内容の記載について
図4では、[一意の識別子](詳細後述)/[データセット更新日]/[データセットの提供元]/[ライセンス]/[説明]といった情報が表示されているが、これらの情報は、前述のメタデータがどのように記載されているかによって変わる。図4の例は豊富な情報が表示されているが、ここまで詳しい情報は表示されないことも多い。
この中で[一意の識別子]は分かりにくいが、これはDOI(Digital Object Identifier:デジタルオブジェクト識別子)、つまりインターネット上で恒久的に与えられる識別子となるURLである。リンク切れを防ぐために、論文引用時などでは、このDOIを示した方がよい。DOIについては(以下、敬称略)、
が分かりやすいので、より詳しくはそちらを参照してほしい。
Copyright© Digital Advantage Corp. All Rights Reserved.