MNISTを使ってオートエンコーダーによる異常検知を試してみよう:作って試そう! ディープラーニング工作室(2/3 ページ)
オートエンコーダーの活用例の一つである異常検知を、MNISTの手書き数字を例に体験してみましょう。
全結合型のオートエンコーダーで試してみる
ここまでの数回ではオートエンコーダーを実装するAutoEncoder2クラスは、エンコーダーとデコーダーを__init__メソッドのパラメーターに受け取るようにしていました。そのため、ここでも全結合型のオートエンコーダーのエンコーダーとデコーダーを次のように定義して、それをAutoEncoder2クラスのインスタンス生成時にそれを渡すようにしましょう。
enc = torch.nn.Sequential(
torch.nn.Linear(1 * 28 * 28, 384),
torch.nn.ReLU(),
torch.nn.Linear(384, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 8),
torch.nn.Tanh(),
)
dec = torch.nn.Sequential(
torch.nn.Linear(8, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 384),
torch.nn.ReLU(),
torch.nn.Linear(384, 1 * 28 * 28),
torch.nn.Tanh()
)
エンコーダーとデコーダーはPyTorchのLinearクラスを使って、最終的には8次元のデータに次元を削減し、それを28×28(=784)次元に復元するものです。
これらを使って、学習を行うのが次のコードです。
net_linear = AutoEncoder2(enc, dec)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(net_linear.parameters(), lr=0.5)
EPOCHS = 100
output_and_label, losses = train(net_linear, criterion, optimizer, EPOCHS, trainloader, linear=True)
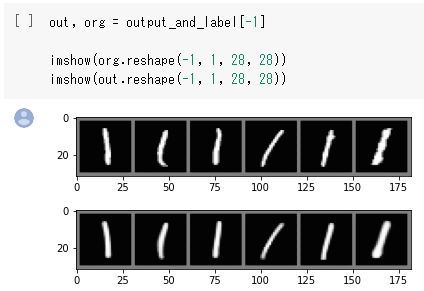
学習が終わったら、最後の学習結果から元画像と復元画像を確認しておきましょう。
out, org = output_and_label[-1]
imshow(org.reshape(-1, 1, 28, 28))
imshow(out.reshape(-1, 1, 28, 28))
もちろん、以下のように、復元できています。
いい感じで学習ができたのを確認したところで、関数を1つ、定義しておきます。この関数は、「1」と「8」を含んだテストデータの全てを(テストローダー経由で)今作成したニューラルネットワークモデルに入力して、その結果を得るものです。ここでは、元画像、出力画像、元画像と出力画像の差分の3つを要素とするタプルを戻り値とします。差分は単純に元画像のテンソルから出力画像のテンソルを減算して、絶対値を取るだけとしました。
def test(net, testloader, linear=False):
result = []
diff = []
org = []
for item, _ in testloader:
if linear:
out = net(item.reshape(-1, 1 * 28 * 28))
out = out.reshape(-1, 1, 28, 28)
else:
out = net(item)
org.extend(item)
result.extend(out)
diff.extend(abs(item - out))
return (org, result, diff)
PyTorchではテンソル同士を減算できるので、ここでは単に「item - out」のようにするだけで、各ピクセルの値の差分を得られていることに注意してください。
この後に畳み込みオートエンコーダーでもこの関数を使い回せるように、全結合型のオートエンコーダーと畳み込みエンコーダーでのニューラルネットワークモデルへの入力の違いを吸収するようにしています。
この関数を実行するには、先ほど作成したニューラルネットワークモデル(net_linear)とテストローダーを引数に指定するだけです。
(org, result, diff) = test(net_linear, testloader, linear=True)
imshow(org[0:20])
imshow(result[0:20])
imshow(diff[0:20])
関数から元画像、出力画像、差分を受け取ったら、imshow関数でそれらを表示しています。その結果は次のようになります。
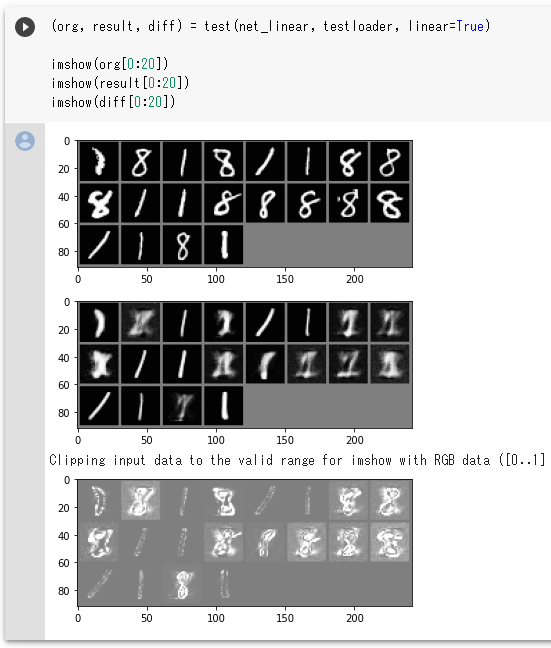
まず元画像と出力画像(復元画像)では、「1」についてはいい感じで復元されていますが、「8」についてはかなりダメな復元度合いであることが分かります。これが「正常なモノだけを学習させていれば、異常なモノもすぐに分かる」ということに相当します。正常なモノ(「1」)の復元の仕方は分かっても、そうでないもの復元の仕方が分からないということです。
その下は、各ピクセルの差分(test関数では「abs(item - out)」としていましたが、ここでは「abs(org - result)」に相当します)を画像として表示したものです(「Clipping input data to the valid range for imshow……」とありますが、ここでは無視します)。これを見ると、「1」についてはノッペリとグレーの画像が表示されています。これは差分がそれほど大きくないことを表していると考えられるでしょう。対して、「8」についてはガビガビの派手目な画像となっています。
画像ごとのピクセルの差分の総和を取り、さらに「1」と「8」の画像グループごとに、それらを合計してから、「1」の画像数または「8」の画像数で割れば、それぞれのグループについて「差分の平均値」が得られます。それら2つの値の間に、正常と異常を区切るしきい値があると思われます。そうしたしきい値を見つけ出せば、その値を基に差分データを正常と異常に分けることも可能でしょう。本稿では目視だけで、そこまではしませんが、こうすれば機械的にどれが正常でどれが異常かを判断できるようになります。
次に畳み込みオートエンコーダーでも、同様な処理を行ってみましょう。
Copyright© Digital Advantage Corp. All Rights Reserved.