[文章生成]スクレイピングで青空文庫からデータを取得してみよう:作って試そう! ディープラーニング工作室(2/2 ページ)
機械学習を使って文章の自動生成を行う準備として、青空文庫から小説のデータを取得して、本文のテキストを1文ずつリストに格納してみましょう。
関数にまとめる
『桜の樹の下には』についてはだいたいこんな感じでスクレイピングができました。ここで行っていた処理を関数にまとめてしまいましょう。
def get_data(url):
response = request.urlopen(url)
soup = BeautifulSoup(response)
response.close()
main_text = soup.find('div', class_='main_text')
tags_to_delete = main_text.find_all(['rp', 'rt'])
for tag in tags_to_delete:
tag.decompose()
main_text = main_text.get_text()
main_text = main_text.replace('\r', '').replace('\n', '').replace('\u3000', '')
main_text = re.sub('([!。])', r'\1\n', main_text)
text_list = main_text.splitlines()
return text_list
では、実際にこの関数を使ってみます。
url = 'https://www.aozora.gr.jp/cards/000074/files/427_19793.html'
text_list = get_data(url)
print(text_list)
実行結果を以下に示します。
どうやらうまくいっているようです。そこで、今度は少し長めの作品のデータを取ってくることにしましょう。梶井基次郎といえば誰も知っている(かもしれない)『檸檬』でもいいなと思ったのですが、『桜の樹の下には』とは少し表示が異なる(上では使っていなかったHTML要素を含んだ)作品の例として、ここでは『城のある町にて』のデータを得てみます。
url = 'https://www.aozora.gr.jp/cards/000074/files/429_19794.html'
text_list = get_data(url)
print(text_list)
実行結果を以下に示します。
一見よさそうですが、実はリストの先頭要素がおかしいことに注意してください。「ある午後「高いとこの眺めは……」となっています。この「ある午後」というのは、実は見出しです。

ソースを確認したところ、これは<h4>タグで表現されていたので、これもdecomposeメソッドでの削除の対象としてしまうことにします。また、会話を表すカギかっこも不要と判断しました。ここでは、開きカギかっこは削除して、閉じカギかっこは改行文字に変換することにしましょう。これらの修正を反映したget_data関数の定義は次のようになります。
def get_data(url):
response = request.urlopen(url)
soup = BeautifulSoup(response)
response.close()
main_text = soup.find('div', class_='main_text')
tags_to_delete = main_text.find_all(['rp', 'rt', 'h4'])
for tag in tags_to_delete:
tag.decompose()
main_text = main_text.get_text()
main_text = main_text.replace('\r', '').replace('\n', '').replace('\u3000', '')
main_text = main_text.replace('「', '').replace('」', '\n')
main_text = re.sub('([!。])', r'\1\n', main_text)
main_text.replace('\n\n', '\n')
text_list = main_text.splitlines()
return text_list
text_list = get_data(url)
print(text_list)
実行結果を以下に示します。
リストの各要素を筆者がざっくりと確認したところでは、それほどおかしいところもなさそうだったので、取りあえず、青空文庫からデータを取得する関数はこれで完成としておきます。
複数の作品データを取得する
get_data関数はURLを指定すると、そのページが提供している単一の作品のデータを取得するものです。しかし、実際には青空文庫からデータを取得する際には、幾つかの作品のデータを得たいのではないでしょうか。もちろん、上の関数を使ってこれは可能です。以下はその例です。
url_list = ['https://www.aozora.gr.jp/cards/000074/files/427_19793.html',
'https://www.aozora.gr.jp/cards/000074/files/429_19794.html']
text_list = []
for url in url_list:
text_list.extend(get_data(url))
しかし、このurl_listに格納しているURLを手作業でコピー&ペーストするのはバカらしいですよね(特に多数の作品のデータを取得したいとすれば)。ある作者の著作を全て取得できるような方法があるとうれしいのではないでしょうか。例えば、以下は梶井基次郎の著作一覧です。

このような一覧があれば自動化も可能な気がします。そこで以下のコードで著作一覧のHTMLソースがどうなっているかを確認してみましょう。
base_url = 'https://www.aozora.gr.jp/index_pages/'
author = 'person74.html' # 梶井基次郎
response = request.urlopen(base_url + author)
soup = BeautifulSoup(response)
print(soup)
ここで注意してほしいのは、梶井基次郎の著作一覧ページのURLをbase_urlとauthorの2つに変数に分けている点です。base_urlはこの後にページ遷移をする際の基本となるURLです。
実行結果の中で、関係ありそうな部分を以下に示します。

<ol>タグ配下の<li>タグの中に作品ページへのリンク(<a>タグ)が含まれているのが分かります。この情報を使えば、作品ページへ遷移をして、 そこからHTMLファイルへのパスを取得できるはずです。
例えば、次のようにすれば作品ページへのURLを取得して、そのページの内容を得ることができるでしょう(ここでは、話を単純にするために先頭のURLだけを見ています)。
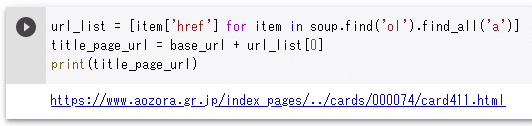
url_list = [item['href'] for item in soup.find('ol').find_all('a')]
title_page_url = base_url + url_list[0]
print(title_page_url)
ここでは、<ol>タグに含まれている<a>タグを見つけて、そのhref属性の値を、リスト内包表記を使ってリストにまとめています。次に、base_urlとurl_listの先頭要素の値とを連結することで、作品ページへのURLとします(このために、先ほどは梶井基次郎の著作一覧ページのURLをbase_urlとauthorの2つの変数に分割しました)。これを実行すると次のようになります。URLを格納しているtitle_page_urlはこの後でも使用します。
こうして取得したURLを使って、作品ページの内容を読み込むコードが以下です。
response = request.urlopen(title_page_url)
title_page = BeautifulSoup(response)
print(title_page)
実行結果は次のようになります。

この画像の中程にある「いますぐXHTML版で読む」という箇所に注目してください。ここにXHTMLファイルへのリンクが含まれています(上では[ファイルのダウンロード]セクションの[ファイル種別]が[XHTMLファイル]となっているリンクを見ていましたが、これらは同じものなので、ここではこちらからURLを取得することにしました)。
これを取得して、実際に作品データを取得するのが以下のコードです。
read_xhtml_div = title_page.find_all('div', align='right')[1]
html_path = read_xhtml_div.find_all('a')[1]['href']
title_page_url = re.sub('card\d+\.html', '', title_page_url)
print(title_page_url)
get_data(title_page_url + html_path)
ここからはHTMLソースに依存した汚いコードになっていますが、最初の行では「<div align="right">」タグをHTMLから検索しています。そのインデックス1の位置にあるのが「いますぐXHTML版を読む」というリンクを含んだ部分です。さらに、その<div>タグの中で<a>タグを検索して、やはりインデックス1となるタグのURL(href属性)を得るようにしました。3行目は、上で作品ページのURLを格納しているtitle_page_urlから末尾の'cardXXX.html'という部分を削除して、上で取得したURLと結合することで、作品データのURLを作成するコードです。このようにして、作成したURLをget_data関数に渡せば、その内容が得られます。
実行結果を以下に示します。

というわけで、ここで行った処理をやはり関数にまとめておきましょう。
import time
def get_all_title_data():
base_url = 'https://www.aozora.gr.jp/index_pages/'
author = 'person74.html'
response = request.urlopen(base_url + author)
author_page = BeautifulSoup(response)
text_list = []
url_list = [item['href'] for item in author_page.find('ol').find_all('a')]
for url in url_list:
title_page_url = base_url + url
response = request.urlopen(title_page_url)
title_page = BeautifulSoup(response)
read_xhtml_div = title_page.find_all('div', align='right')[1]
html_path = read_xhtml_div.find_all('a')[1]['href']
title_page_url = re.sub('card\d+\.html', '', title_page_url)
result = get_data(title_page_url + html_path)
text_list.extend(result)
time.sleep(5)
return text_list
この関数はここまでに見てきた処理を、著作一覧ページに含まれている各作品のURLのリストに対して行うようにしてあります。また、サーバーへの負荷を考慮して、timeモジュールのsleep関数を使い、作品データを読み込むごとに5秒間スリープするようにしました。
実際に使ってみた例を以下に示します。
text_list = get_all_title_data()
引数に別の著者の作品一覧ページ('personXXXX.html’)を渡すことも考えましたが、動作は未確認です。興味のある方は試してみてください。
というわけで、今回は青空文庫から著作権が切れた小説の本文データを取得するまでの処理を見ました。次回は、このデータを使って少し遊んでみることにしましょう。
Copyright© Digital Advantage Corp. All Rights Reserved.