[解決!Python]OpenPyXLを使ってExcelファイルを読み書きするには:解決!Python
openpyxlパッケージを使って、Excelのワークブックの作成/読み込み/保存やワークシートの作成、セルの値の読み取り/書き込みなどを行う方法を紹介する。
* 本稿は2022年2月8日に公開された記事をPython 3.12.1で動作確認したものです(確認日:2024年1月8日)。
from openpyxl import Workbook # 「pip install openpyxl」でインストールしておく
# ワークブックの新規作成と保存
wb = Workbook()
wb.save('myworkbook.xlsx')
# ワークブックの読み込み
from openpyxl import load_workbook
wb = load_workbook('myworkbook.xlsx')
# ワークシートの選択
ws = wb['Sheet'] # ワークシートを指定
ws = wb.active # アクティブなワークシートを選択
print(f'sheet name: {ws.title}') # sheet name: Sheet
# ワークシートの作成
wb.create_sheet('my sheet')
wb.create_sheet('my sheet')
wb.create_sheet('my sheet')
# ワークシートの列挙
for sheet in wb:
print(f'sheet name: {sheet.title}')
# 実行結果:
#Sheet
#my sheet
#my sheet1
#my sheet2
# セルに書き込み
ws['A1'] = 'Hello from Python'
wb.save('myworkbook.xlsx') # overwrite myworkbook.xlsx
# セルの値の表示
print(ws['a1'].value) # Hello from Python
# cellメソッドでセルに書き込み
ws.cell(row=1, column=1).value = 1
print(ws['a1'].value) # 1
ws.cell(row=1, column=1, value=2)
print(ws['a1'].value) # 2
for idx in range(1, 4):
ws.cell(row=1, column=idx, value=idx)
ws.cell(row=2, column=idx, value=-idx)
# ワークシートの全セルを反復(行ごと)
for row in ws.iter_rows():
for cell in row:
print(cell.value)
# 出力結果:
#1
#2
#3
#-1
#-2
#-3
for row in ws.rows:
for cell in row:
print(cell.value)
min_row = ws.min_row
max_row = ws.max_row
min_col = ws.min_column
max_col = ws.max_column
for row in ws.iter_rows(min_row=min_row, max_row=max_row,
min_col=min_col, max_col=max_col):
for cell in row:
print(cell.value)
# セルの値を取得する
for row in ws.iter_rows(values_only=True):
for value in row:
print(value)
# ワークシートの全セルを反復(列ごと)
for column in ws.iter_cols(values_only=True):
print(column)
for column in ws.columns:
for cell in column:
print(cell.value)
# セル範囲の取得
rng = ws['A1':'C2']
print(rng)
# 出力結果:
#((<Cell 'Sheet'.A1>, <Cell 'Sheet'.B1>, <Cell 'Sheet'.C1>),
# (<Cell 'Sheet'.A2>, <Cell 'Sheet'.B2>, <Cell 'Sheet'.C2>))
values = []
for row in rng:
tmp = []
for col in row:
tmp.append(col.value)
values.append(tmp)
#values = [[col.value for col in row] for row in rng]
print(values)
# セル範囲への代入
from openpyxl.cell.cell import Cell
def get_shape(rng):
return (len(rng), len(rng[0]))
def assign2range(dst, src):
dst_shape = get_shape(dst)
src_shape = get_shape(src)
if src_shape != dst_shape:
raise ValueError('shapes of arguments not match')
for d, s in zip(dst, src): # dst/src: Cellまたは値のタプルを格納するタプル
for t, v in zip(d, s): # d/s: Cellまたは値を格納するタプル
if isinstance(v, Cell):
v = v.value
t.value = v
values = [
[1, 2, 3], [4, 5, 6]
]
assign2range(ws['A1':'C2'], values)
assign2range(ws['A1:C1'], [[100, 200, 300]])
assign2range(ws['A3':'C4'], ws['A1':'C2'])
wb.save('myworkbook.xlsx')
OpenPyXLの基本的な使い方
OpenPyXLは、PythonでExcelファイルを読み書きするためのライブラリであり、PyPIで配布されている。本稿では、これを使用してExcelファイルを読み書きする方法の基本を紹介する。既に述べたように、これはPyPIで配布されているので事前に「pip install openpyxl」コマンドなどを実行してopenpyxlパッケージをインストールしておく必要がある。
openpyxlパッケージが提供するWorkbookクラスを使用すると、メモリ内に新規にExcelのワークブックを作成できる。作成したワークブックはsaveメソッドでExcelファイルとして保存可能だ。
from openpyxl import Workbook
wb = Workbook()
wb.save('myworkbook.xlsx')
注意する点としては、saveメソッドを呼び出すと、指定した名前のファイルが既に存在していた場合には、それが上書きされる点だ。
このパッケージが提供するload_workbook関数を使うと、既存のExcelファイルを読み込める。
from openpyxl import load_workbook
wb = load_workbook('myworkbook.xlsx')
ワークブックはワークシートなどを格納するコンテナとして機能する。
ワークシートの選択
新規に作成したWorkbookクラスのインスタンスには「Sheet」という名前のワークシートが格納されている。これをPythonで操作する対象として選択するには、大きく2つの方法がある。1つは「ワークブック[ワークシート名]」のようにワークシート名を指定する方法で、もう1つは「ワークブック.active」として現在アクティブなワークシートを選択する方法だ。
以下に例を示す。
ws = wb['Sheet'] # ワークシートを指定
ws = wb.active # アクティブなワークシートを選択
print(f'sheet name: {ws.title}') # sheet name: Sheet
既に述べた通り、新規に作成したワークブックにあるワークシートは「Sheet」だけである。よって、上のコードは同じワークシートを選択することになる。
ワークシートにはさまざまな属性やメソッドがあるが、title属性を介してワークシートの名前を取得したり、設定したりできる。上のコードではワークシート名を表示している。
ワークシートの作成と列挙
ワークブックはワークシートなどを格納するコンテナであり、表形式のデータを格納するのは上のコードで選択したワークシートである。ワークシートは、Workbookクラスのcreate_sheetメソッドを呼び出すことで、現在のワークブックに新規に作成できる。以下に例を示す。
wb.create_sheet('my sheet')
wb.create_sheet('my sheet')
wb.create_sheet('my sheet')
この例では、create_sheetメソッドに同じシート名を指定しているが、重複した名前を指定した場合には「1」「2」などのインデックスが自動的に付加される。
ワークブックに含まれるワークシートはワークブックオブジェクトを反復することで得られる。反復しながら、上で述べたインデックスが自動的に付加されているかを調べてみよう。あるいは、ワークブックにはworksheets属性があり、ここにはリストの要素としてワークシートが格納されているので、以下のコメントにあるように「for sheet in wb.worksheets:」としてもよい。
for sheet in wb: # for sheet in wb.worksheets:
print(f'sheet name: {sheet.title}')
# 実行結果:
#Sheet
#my sheet
#my sheet1
#my sheet2
実行結果を見ると、デフォルトでワークブックに含まれるワークシート「Sheet」に加えて、上の3行のcreate_sheetメソッドで追加したワークシートがあること、1つ目のワークシートは「my sheet」で、残る2つのワークシートには「1」「2」のインデックスが付加されていることが分かる。
セルに対する値の書き込みと読み込み
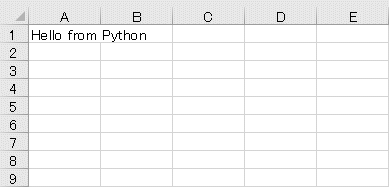
ワークシート内のセルにはExcelと同様に行と列を指定することでアクセスできる。以下はセルA1の値を「'Hello from Python'」として、そのセルの値を表示する例だ。
ws['A1'] = 'Hello from Python'
print(ws['a1'].value) # Hello from Python
wb.save('myworkbook.xlsx')
特定のセルの値を読み出すにはvalue属性を利用することには注意すること。逆に特定のセルの値を変更するのに「ws['A1'].value = 'Hello from Python'」のように書くこともできる。
最後のsaveメソッド呼び出しでこのワークブックを保存し、それをExcelでオープンしたものを以下に示す。
加えて、cellメソッドに行と列(と値)を指定して、そのセルを取得して、値を読み出したり、そのセルの値を設定したりできる。以下に例を示す。
ws.cell(row=1, column=1).value = 1
print(ws['a1'].value) # 1
ws.cell(row=1, column=1, value=2)
print(ws['a1'].value) # 2
最初の2行では、cellメソッドでセルを取得した後に、value属性に新しい値を代入し、その値をvalue属性経由で読み出している。次の行ではcellメソッドのvalue引数に新しい値を指定している。
cellメソッドをforループと組み合わせることで、連続する範囲のセルの値を便利に読み書きできる。以下に例を示す。
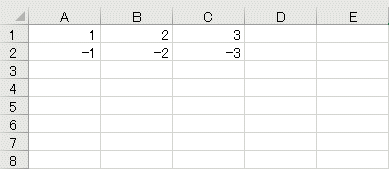
for idx in range(1, 4):
ws.cell(row=1, column=idx, value=idx)
ws.cell(row=2, column=idx, value=-idx)
wb.save('myworkbook.xlsx')
この例では、セルA1〜C1とセルA2〜C2に値を書き込んでいる。保存したワークブックをExcelで開いたものを以下に示す。
なお、行と列を指定したり、cellメソッドを呼び出したりした際にそれまで存在していなかったセルにアクセスすると、そのセルがメモリ中のワークブックに作成される。
ワークシートの全セルを反復
上のサンプルで現在のワークブックのセルA1〜C2の6個のセルに値が入力された。これらのセル全てを反復するには幾つかの方法がある。
1つはiter_rowsメソッドで行を反復するものだ。以下に例を示す。
for row in ws.iter_rows():
for cell in row:
print(cell.value)
# 出力結果:
#1
#2
#3
#-1
#-2
#-3
この例では、行を反復しているので1行目の値である「1」「2」「3」がまず表示され、次に2行目の値である「-1」「-2」「-3」が順次表示されている。
これと同じことがrows属性を使っても行える。以下に例を示す(出力結果は省略)。
for row in ws.rows:
for cell in row:
print(cell.value)
では、これらはどこが違うかというと、iter_rowsメソッドでは反復を開始/終了する行、反復時に取得する列の先頭と末尾を指定できる点だ(加えて、セルを取得するのか、セルの値を取得するのかも指定可能。後述)。
例えば、以下はこのワークシートでデータを含んでいるセルが含まれる範囲をmin_row/max_row/min_column/max_columnの4つの属性で取得し、それらをiter_rowsメソッドに指定して行の反復を行っている(出力結果は省略)。
min_row = ws.min_row
max_row = ws.max_row
min_col = ws.min_column
max_col = ws.max_column
for row in ws.iter_rows(min_row=min_row, max_row=max_row,
min_col=min_col, max_col=max_col):
for cell in row:
print(cell.value)
このように行や列を反復する際に、重要なのは行や列、またはそれらを構成するセルではなく、それらの値であることもよくある。そのため、反復の対象をセルの値とすることも可能だ。これにはiter_rowsメソッドでvalues_only引数にTrueを指定する。以下に例を示す(出力結果は省略)。例えばヘッダー行があるときには、その行は反復の対象から外すといった使い方が考えられる。
for row in ws.iter_rows(values_only=True):
for value in row:
print(value)
ここまでは行を反復したが、列を反復するiter_colsメソッドとcolumns属性もある。以下に例を示す。出力結果は省略するが、先ほどとは異なり「1と-1」「2と-2」「3と-3」が順次出力されることに注意しよう。
for column in ws.iter_cols(values_only=True):
print(column)
for column in ws.columns:
for cell in column:
print(cell.value)
セル範囲の取得と値の代入
セル範囲の指定もExcelと同様に行える。以下に例を示す。
rng = ws['A1':'C2']
print(rng)
# 出力結果:
#((<Cell 'Sheet'.A1>, <Cell 'Sheet'.B1>, <Cell 'Sheet'.C1>),
# (<Cell 'Sheet'.A2>, <Cell 'Sheet'.B2>, <Cell 'Sheet'.C2>))
セル範囲は「開始セル:終了セル」のように指定する。このとき、上のコードでは「'A1':'C2'」のようにセルを引用符で囲んでいるが、「'A1:C2'」のように指定してもよい。
気を付けたいのは、出力結果を見ると分かる通り、セル範囲はそこに含まれるセル(Cellクラスのインスタンス)を含んだタプル(のタプル)として返される点だ。例えば、以下のようなコードは例外となる。
ws['A1:B1'] = [1, 2]
これは恐らく2つのセルに1と2を代入しようとしているが、ws['A1:B1']の値は「((<Cell 'Sheet'.A1>, <Cell 'Sheet'.B1>),)」というタプルのタプルであり、タプルにはvalue属性はないので例外が発生する。同時に、扱いたいのはセルの内容であって、Cellオブジェクトではないことが問題となるかもしれない。
セル範囲の値を読み取るには例えば、以下のようなループ(またはコメントアウトしている内包表記)を記述することになるだろう。
values = []
for row in rng:
tmp = []
for col in row:
tmp.append(col.value)
values.append(tmp)
#values = [[col.value for col in row] for row in rng]
print(values) # [[1, 2, 3], [-1, -2, -3]]
出力結果を見ると分かるが、このコードにより、行ごとにセルの値がリストにまとめられ、それらが列ごとに外側のリストに含まれた結果が得られる。
また、セル範囲に代入をするのであれば、次のようなコードが考えられる。
from openpyxl.cell import Cell
def get_shape(rng):
return (len(rng), len(rng[0]))
def assign2range(dst, src):
dst_shape = get_shape(dst)
src_shape = get_shape(src)
if src_shape != dst_shape:
raise ValueError('shapes of arguments not match')
for d, s in zip(dst, src): # dst/src: Cellまたは値のタプルを格納するタプル
for t, v in zip(d, s): # d/s: Cellまたは値を格納するタプル
if isinstance(v, Cell):
v = v.value
t.value = v
values = [
[1, 2, 3], [4, 5, 6]
]
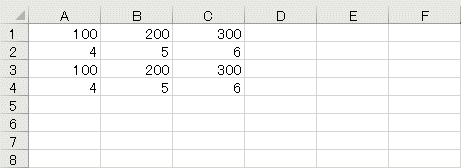
assign2range(ws['A1':'C2'], values)
assign2range(ws['A1:C1'], [[100, 200, 300]])
assign2range(ws['A3':'C4'], ws['A1':'C2'])
wb.save('myworkbook.xlsx')
assign2range関数は代入先(dst)と代入元(src)を受け取って、それらが同じ形状(同じ列数、同じ行数)かどうかをチェックして、そうであれば、代入元の値を代入先のセルへと順次コピーしていく。
3つのassign2range関数呼び出しではまず、セル範囲A1:C1に1、2、3を、セル範囲A2:C2に4、5、6をコピーしている。次に、セル範囲A1:C1に100、200、300をコピーしている。最後にセル範囲A1:C2の値をセル範囲C3:C4にコピーしている。
saveメソッドでワークブックを保存した後、Excelでこれをオープンしたものを以下に示す。上で述べた処理ができていることを確認しよう。
実際にはこれだけでは不十分かもしれない。例えば、代入先と代入元のセル範囲が重複している場合、これは想定と異なる動作をするだろう。これを回避するには事前に代入元のセル範囲の値をローカル変数に保存しておいて、それらを代入先のセル範囲にコピーするようなコードとすべきだ。
def assign2range(dst, src):
if isinstance(src[0][0], Cell):
src = [[col.value for col in row] for row in src]
dst_shape = get_shape(dst)
src_shape = get_shape(src)
if src_shape != dst_shape:
raise ValueError('shapes of arguments not match')
for d, s in zip(dst, src):
for t, v in zip(d, s):
t.value = v
Copyright© Digital Advantage Corp. All Rights Reserved.