NumPyでニューラルネットワークをフルスクラッチ実装してみよう:ニューラルネットワーク入門(3/3 ページ)
「線形代数を使ったニューラルネットワークの基礎を押さえたい!」という方にピッタリ。ニューラルネットワークをPython+NumPy(線形代数)でフルスクラッチ実装する。線形代数なしで実装した場合との差分から効率的に理解できる。
ここからの内容に不明点がある場合は、「第3回:最適化」も併せてご参照ください。
ステップ3. パラメーター(重みとバイアス)更新の実装
1つのパラメーターの更新
最も基本的なSGD(確率的勾配降下法)の場合、1つの重み/バイアスのパラメーター更新は以下の計算方法で行えます。なお、ηは「イータ」と読みます。

数式で表現すると、以下のようになります。これらが冒頭の図3に掲載した数式です。
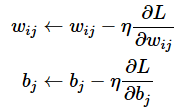
1つの層内にある全パラメーターの更新
NumPyの二次元配列や一次元配列を使う場合、多次元配列内の各要素をまとめて計算可能です(リスト23)。その場合の数式は次のように表現できるでしょう。
# 取りあえず仮で、変数を定義して、コードが実行できるようにしておく
W = np.array([[0.0]]) # 重み(行列)
b = np.array([0.0]) # バイアス(ベクトル)
grad_W = np.array([[0.2]]) # 重みの勾配(行列)
grad_b = np.array([0.2]) # バイアスの勾配(ベクトル)
LEARNING_RATE = 0.1 # 学習率(lr)
lr = LEARNING_RATE
# ---ここまでは仮の実装。ここからが必要な実装---
W = W - lr * grad_W # 重みパラメーターの更新
b = b - lr * grad_b # バイアスパラメーターの更新
パラメーター更新の処理全体の実装
ニューラルネットには、層があり、その中に複数のノードが存在するという構造ですので、
- 各層を1つずつ処理するforループと、
- 層の中の全ノードをまとめて処理する行列計算、の2段階構造が必要で、ここに行列計算を使った「パラメーター更新の処理」
を記述すればよいわけです(リスト24)。
def update_params(layers, weights, biases, grads_w, grads_b, lr=0.1):
"""
パラメーター(重みとバイアス)を更新する関数
- 引数:
(layers, weights, biases): モデルを指定する。
grads_w: 重みの勾配。
grads_b: バイアスの勾配。
lr: 学習率(learning rate)。最適化を進める量を調整する。
- 戻り値:
新しい重みとバイアスを返す。
"""
# ネットワーク全体で勾配を保持するためのリスト
new_weights = [] # 重み
new_biases = [] # バイアス
SKIP_INPUT_LAYER = 1
for layer_i, layer in enumerate(layers): # 各層を処理
if layer_i == 0:
continue # 入力層はスキップ
# 層ごとに全ノードまとめて処理を行う
b = biases[layer_i - SKIP_INPUT_LAYER]
grad_b = grads_b[layer_i - SKIP_INPUT_LAYER]
layer_b = b - lr * grad_b # バイアスパラメーターの更新
W = weights[layer_i - SKIP_INPUT_LAYER]
grad_W = grads_w[layer_i - SKIP_INPUT_LAYER]
layer_W = W - lr * grad_W # 重みパラメーターの更新
new_weights.append(layer_W)
new_biases.append(layer_b)
return (new_weights, new_biases)
パラメーター更新の実行例
以下のようなコードを書けば、順伝播から逆伝播、パラメーター更新までを続けて実行できます。
layers = [2, 2, 2]
weights = [
np.array([[0.15, 0.2], [0.25, 0.3]]),
np.array([[0.4, 0.45], [0.5,0.55]])
]
biases = [
np.array([0.35, 0.35]),
np.array([0.6, 0.6])
]
model = (layers, weights, biases)
# 元の重み
print(f'old-weights={weights}'.replace('\n ', ''))
print(f'old-biases={biases}')
# old-weights=[array([[0.15, 0.2 ], [0.25, 0.3 ]]), array([[0.4 , 0.45], [0.5 , 0.55]])]
# old-biases=[array([0.35, 0.35]), array([0.6, 0.6])]
# (1)順伝播の実行例
x = np.array([0.05, 0.1])
y_pred, cached_outs, cached_sums = forward_prop(*model, x, cache_mode=True)
# (2)逆伝播の実行例
y_true = np.array([0.01, 0.99])
grads_w, grads_b = back_prop(*model, y_true, cached_outs, cached_sums)
print(f'grads_w={grads_w}'.replace('\n ', ''))
print(f'grads_b={grads_b}')
# grads_w=[array([[0.00670603, 0.01341205], [0.00748746, 0.01497492]]), array([[0.65016812, 0.65412915], [0.13937182, 0.14022092]])]
# grads_b=[array([0.13412051, 0.14974924]), array([1.09590597, 0.2349214 ])]
# (3)パラメーター更新の実行例
LEARNING_RATE = 0.1 # 学習率(lr)
weights, biases = update_params(*model, grads_w, grads_b, lr=LEARNING_RATE)
# 更新後の新しい重み
print(f'new-weights={weights}'.replace('\n ', ''))
print(f'new-biases={biases}')
# new-weights=[array([[0.1493294 , 0.19865879], [0.24925125, 0.29850251]]), array([[0.33498319, 0.38458708], [0.48606282, 0.53597791]])]
# new-biases=[array([0.33658795, 0.33502508]), array([0.4904094 , 0.57650786])]
# モデルの最適化
model = (layers, weights, biases)
3つのステップを呼び出す最適化処理の実装
最適化の処理全体の実装
本稿における最適化処理全体の実装では、
- エポックを1回ずつ処理するforループと、
- その中にデータを1件ずつ処理するforループの2段階構造を用意し、
- その中に「ステップ1. 順伝播」「ステップ2. 逆伝播」と、
- イテレーションごとに「ステップ3. パラメーターの更新」
- その中にデータを1件ずつ処理するforループの2段階構造を用意し、
を記述するようにします(※あくまで筆者による実装方針の例です)。
階層が深くなる上にコードの行数が少し長いので、説明の都合上、上の箇条書きの前半2行をリスト26(train()親関数)、後半2行をリスト27(optimize()子関数)、という親子関係の2つの関数に分けて記述します。いずれも基礎編とほぼ同じコードです。
import random
# 取りあえず仮で、空の関数を定義して、コードが実行できるようにしておく
def optimize(model, x, y, data_i, last_i, batch_i, batch_size, acm_g, lr=0.1):
" モデルを最適化する関数(子関数)。"
loss = 0.1
return model, loss, batch_i, acm_g
# ---ここまでは仮の実装。ここからが必要な実装---
def train(model, x, y, batch_size=32, epochs=10, lr=0.1, verbose=10):
"""
モデルの訓練を行う関数(親関数)。
- 引数:
model: モデルをタプル「(layers, weights, biases)」で指定する。
x: 訓練データ(各データが行、各特徴量が列の、2次元リスト値)。
y: 訓練ラベル(各データが行、各正解値が列の、2次元リスト値)。
batch_size: バッチサイズ。何件のデータをまとめて処理するか。
epochs: エポック数。全データ分で何回、訓練するか。
lr: 学習率(learning rate)。最適化を進める量を調整する。
verbose: 訓練状況を何エポックおきに出力するか。
- 戻り値:
損失値の履歴を返す。これを使って損失値の推移グラフが描ける。
"""
loss_history = [] # 損失値の履歴
data_size = len(y) # 訓練データ数
data_indexes = range(data_size) # 訓練データのインデックス
# 各エポックを処理
for epoch_i in range(1, epochs + 1): # 経過表示用に1スタート
acm_loss = 0 # 損失値を蓄積(accumulate)していく
# 訓練データのインデックスをシャッフル(ランダムサンプリング)
random_indexes = random.sample(data_indexes, data_size)
last_i = random_indexes[-1] # 最後の訓練データのインデックス
# 親関数で管理すべき変数
acm_g = (None, None) # 重み/バイアスの勾配を蓄積していくため
batch_i = 0 # バッチ番号をインクリメントしていくため
# 訓練データを1件1件処理していく
for data_i in random_indexes:
# 親子に分割したうちの子関数を呼び出す
model, loss, batch_i, acm_g = optimize(
model, x, y, data_i, last_i, batch_i, batch_size, acm_g, lr)
acm_loss += loss # 損失値を蓄積
# エポックごとに損失値を計算。今回の実装では「平均」する
layers = model[0] # レイヤー構造
out_count = layers[-1] # 出力層のノード数
# 「訓練データ数(イテレーション数×バッチサイズ)×出力ノード数」で平均
epoch_loss = acm_loss / (data_size * out_count)
# 訓練状況を出力
if verbose != 0 and \
(epoch_i % verbose == 0 or epoch_i == 1 or epoch_i == EPOCHS):
print(f'[Epoch {epoch_i}/{EPOCHS}] train_loss: {epoch_loss}')
loss_history.append(epoch_loss) # 損失値の履歴として保存
return model, loss_history
# サンプル実行用の仮のモデルとデータ
layers = [2, 2, 2]
weights = [
np.array([[0.15, 0.2], [0.25, 0.3]]),
np.array([[0.4, 0.45], [0.5,0.55]])
]
biases = [
np.array([0.35, 0.35]),
np.array([0.6, 0.6])
]
model = (layers, weights, biases)
x = np.array([[0.05, 0.1]])
y = np.array([[0.01, 0.99]])
# モデルを訓練する
BATCH_SIZE = 2 # バッチサイズ
EPOCHS = 1 # エポック数
LEARNING_RATE = 0.02 # 学習率(lr)
model, loss_history = train(model, x, y, BATCH_SIZE, EPOCHS, LEARNING_RATE)
# 出力例:
# [Epoch 1/1] train_loss: 0.05
def accumulate(list1, list2):
"2つのリストの値を足し算する関数。"
new_list = []
for item1, item2 in zip(list1, list2):
# ※全体の重み勾配は行数と列数が同じではないので層ごとに処理する必要がある。
np_sum = np.array(item1) + np.array(item2)
new_list.append(np_sum)
return new_list
def mean_element(list1, data_count):
"1つのリストの値をデータ数で平均する関数。"
new_list = []
for item1 in list1:
# ※全体の重み勾配は行数と列数が同じではないので層ごとに処理する必要がある。
np_mean = np.array(item1) / data_count
new_list.append(np_mean)
return new_list
def optimize(model, x, y, data_i, last_i, batch_i, batch_size, acm_g, lr=0.1):
"train()親関数から呼ばれる、最適化のための子関数。"
layers = model[0] # レイヤー構造
each_x = np.array(x[data_i]) # 1件分の訓練データ
y_true = np.array(y[data_i]) # 1件分の正解値
# ステップ1. 順伝播
y_pred, outs, sums = forward_prop(*model, each_x, cache_mode=True)
# ステップ2. 逆伝播
gw, gb = back_prop(*model, y_true, outs, sums)
# 各勾配を蓄積(accumulate)していく
if batch_i == 0:
acm_gw = gw
acm_gb = gb
else:
acm_gw = accumulate(acm_g[0], gw)
acm_gb = accumulate(acm_g[1], gb)
batch_i += 1 # バッチ番号をカウントアップ=現在のバッチ数
# 訓練状況を評価するために、損失値を取得
loss = 0.0
for output, target in zip(y_pred, y_true):
loss += sseloss(output, target)
# バッチサイズごとで後続の処理に進む
if batch_i % BATCH_SIZE != 0 and data_i != last_i:
return model, loss, batch_i, (acm_gw, acm_gb) # バッチ内のデータごと
layers = model[0] # レイヤー構造
out_count = layers[-1] # 出力層のノード数
# 平均二乗誤差なら平均する(損失関数によって異なる)
grads_w = mean_element(acm_gw, batch_i * out_count) # 「バッチサイズ ×
grads_b = mean_element(acm_gb, batch_i * out_count) # 出力ノード数」で平均
batch_i = 0 # バッチ番号を初期化して次のイテレーションに備える
# ステップ3. パラメーター(重みとバイアス)の更新
weights, biases = update_params(*model, grads_w, grads_b, lr)
# モデルをアップデート(=最適化)
model = (layers, weights, biases)
return model, loss, batch_i, (acm_gw, acm_gb) # イテレーションごと
# サンプル実行
model, loss_history = train(model, x, y, BATCH_SIZE, EPOCHS, LEARNING_RATE)
# 出力例:
# [Epoch 1/1] train_loss: 0.31404948868496607
回帰問題を解くデモ
これも、何カ所かnp.array()関数を呼び出している以外は、基礎編と全く同じコードです。
# !pip install playground-data
import matplotlib.pyplot as plt
# 訓練データを取得
import plygdata as pg
PROBLEM_DATA_TYPE = pg.DatasetType.RegressPlane
TRAINING_DATA_RATIO = 0.5
DATA_NOISE = 0.0
data_list = pg.generate_data(PROBLEM_DATA_TYPE, DATA_NOISE)
X_train, y_train, _, _ = pg.split_data(data_list, training_size=TRAINING_DATA_RATIO)
# モデルを定義
layers = [2, 3, 1]
weights = [
np.array([[0.0, 0.0], [0.0, 0.0], [0.0, 0.0]]),
np.array([[0.0, 0.0, 0.0]])
]
biases = [
np.array([0.0, 0.0, 0.0]),
np.array([0.0])
]
model = (layers, weights, biases)
# 訓練用のハイパーパラメーター設定
BATCH_SIZE = 4 # バッチサイズ
EPOCHS = 100 # エポック数
LERNING_RATE = 0.02 # 学習係数
# 訓練処理の実行
model, loss_history = train(model, X_train, y_train, BATCH_SIZE, EPOCHS, LEARNING_RATE)
# 学習結果(損失)のグラフを描画
epochs = len(loss_history)
plt.plot(range(1, epochs + 1), loss_history, marker='.', label='loss (Training data)')
plt.legend(loc='best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
当然、結果は同じになります(図9、図10)。
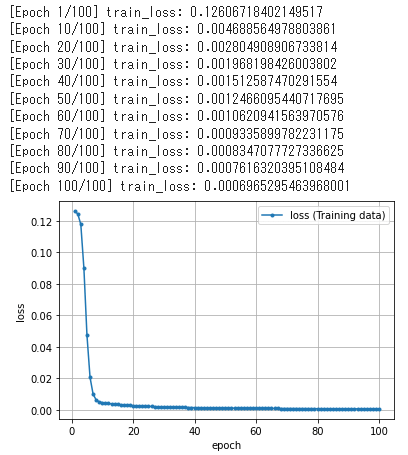
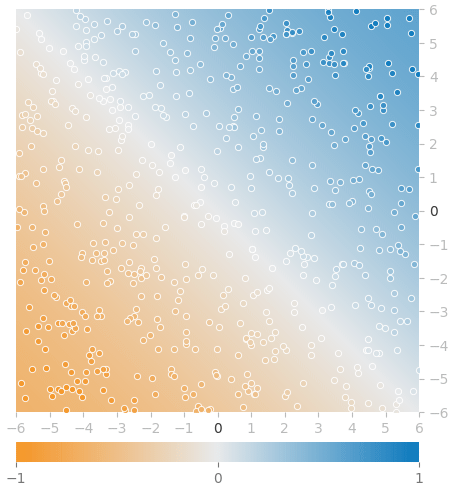
以上で、NumPy/線形代数を使ってニューラルネットワークをフルスクラッチ実装できました。これでかなり自信が持てるようになっていれば筆者としてうれしいです。
さまざまな活性化関数や重みの初期化関数の実装など、より詳細で発展的な内容(発展編)を執筆したいと考えています。しかし、現在の実装では各種関数がハードコーディングされており、一部だけを差し替えるのが面倒です。そこで今回の実装をPythonクラス化して、簡単に切り替えられる前準備をしたいと思います。
次回は本連載(応用編)の2本目として「クラス化」について説明します。「ニューラルネットワークのコーディングや仕組みの理解」というよりも、「Pythonプログラミングやオブジェクト指向の講座」のようになってしまうと思いますが、発展編に進むために必要な途中の過程なのでご了承ください。
Copyright© Digital Advantage Corp. All Rights Reserved.