ドラッグストアチェーンの開店場所の推測でやっていること:AI・データサイエンスで遊ぼう(1/2 ページ)
ニューラルネットワークモデルで開店場所の候補地を推測する際に、どんなデータを使ったか、どんなコードをJupyterノートブックに書いたかを説明します。
開店場所はどうやって推測している?
前回は、ロケスマでチェーン店情報を提供する目的でクローリングしたデータを基に、3つのドラッグストアチェーンの開店予測をしたらこんな結果になったよというお話をしました。

ドラッグストアチェーンの開店地予想(前回の画像の再掲)
出典:地理院地図Vector(仮称)
上記ページで公開されているコードを基に、ピンを使ってニューラルネットワークモデルが推測した開店候補地を描画しています。
今回は、これを行うためにどんなコードを書いたかを紹介します(ただし、コードの詳細にまで踏み込むことはしません)。
実際のところ、開店場所を予測するのに特に難しいことはしていません。前回も述べましたが、以下にまとめましょう。
- ドラッグストアチェーンの店舗が過去5年に開店/閉店した日の周辺店舗情報を収集する
- 周辺店舗情報は各行が開店/閉店した店舗の情報を表し、その各列には2000超のチェーンについて開店/閉店した店舗の周辺500メートル以内に存在しているかどうかが、存在していれば店舗との距離がその値として、存在していなければ0がその値として含まれている
- この情報をpandasのデータフレームに読み込んで、データフレームの各行/各列の値を「1/距離の二乗」に置き換える(距離が近いほど、開店/閉店の判断に対する影響力が強いだろうという仮説によるもの)
- 開店した店舗の周辺店舗情報には教師ラベル(open列)として「1」を、閉店した店舗については教師ラベルとして「0」を付加する
- このデータを使って、PyTorchで作成したニューラルネットワークモデルに学習させる
- 緯度経度を約100メートルずつずらしながら、横浜市を取り囲む地域の各地点について上と同様な周辺店舗情報を収集する
- 上と同様な処理を行い、データフレームを作成する
- 学習後のニューラルネットワークモデルにこのデータフレームを入力して、算出された値が0.9以上の地点を開店場所の候補地とする
- 候補地を地図上にプロットする
- 以上の処理をドラッグストアチェーンR、G、Bに関して行う
実際には周辺店舗情報を訓練データ(含む検証データ)とテストデータに分離したり、正規化したりといった処理も行っていますが、概要は上の通りです。
いざ原稿を書こうと思ったら、たいしたことはしていないような気がしてきて、何を書けばよいのか分からなくなりました。というわけで、「ここは個人的に重要だったなぁ」と思ったところを重点的に紹介していきます(かわさき)。
今回のAIのタスク(問題)は普通と違って特殊に見えるけど、データの前処理やニューラルネットワークのモデルの作成作業については、いつも通りと大差がなかったということですね(一色)。
ファイルとフォルダの構成
上で述べた処理は、最終的には幾つかのPythonスクリプト(.pyファイル)とJupyterノートブックに分割して記述することになりました。

[エクスプローラー]ビューに表示されているファイル/フォルダについてここで簡単にまとめておきましょう。
開店場所を推測するコードはdrug_[RGB].ipynbファイル(Jupyterノートブックを)に記述しています。また2つあるPythonスクリプト(dnn.pyファイルとkfoldds.pyファイル)には、ノートブック内で使用しているニューラルネットワーククラスの定義と、そのニューラルネットワーククラスで使用しているK分割交差検証を行うためにデータセットを分割するコードが含まれています。
chain_json.txtファイルは今回の開店場所の推測で使用しているデータに含まれているチェーン情報を記したファイルで、dataフォルダに含まれている周辺店舗情報の各列がこれに対応するようになっています。
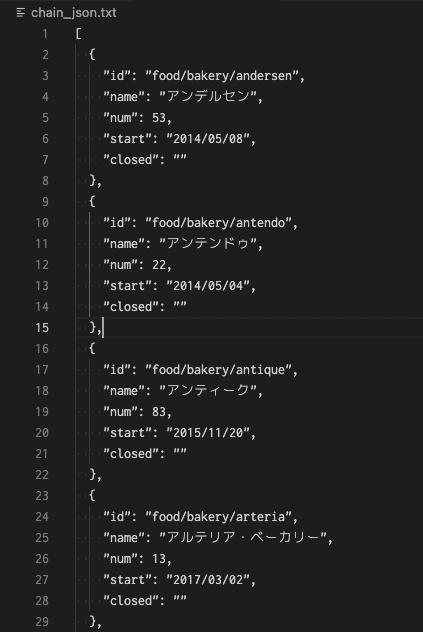
上の画像に示した通り、個々のチェーンに割り当てられたIDとチェーン名、いつからクローリングを開始したかなどの情報を含んだJSON形式のデータが記述されています。以下に示すように、これはdataファイルに含まれている周辺店舗情報をデータフレームとして読み込む際に列名として使用しています。

yokohama_grid.txtファイルには横浜市を取り囲む範囲の各地点の周辺店舗情報を含んでいます。

第0列が「緯度_経度」になっている(つまり、各行が第0列で示す緯度経度の周辺情報を示す)ことを除けば、このフォーマットは次に説明するdataフォルダのファイルと同様です。「緯度_経度」はoutputフォルダに出力するcandidate_[RGB].csvファイルと、HTMLへコピー&ペーストする目的でそれらを加工したloc_[RGB].txtファイルに出力する際に使用します。
dataフォルダには、ドラッグストアチェーンR、G、Bについて過去5年の間に開店/閉店した周辺店舗情報を含むファイルが格納されています(上のyokohama_grid.txtファイルと表示方法が異なっているのは、yokohama_grid.txtファイルのサイズが巨大なために、1行の途中で改行などをしないようになっているからです)。

これらは開店時の周辺店舗情報(kaiten_shopping_drug_[RGB].txtファイル)と閉店時の周辺店舗情報(heiten_shopping_drug_[RGB].txtファイル)に分けられているので、チェーンごとに開店場所の推測を行うdrug_[RGB].ipynbファイルでは2つのCSVファイルを読み込んで開店時の周辺店舗情報を含むデータフレームには教師ラベル「1」を、閉店時の周辺店舗情報を含むデータフレームには教師ラベル「0」を割り当て、その後に1つのデータフレームに結合しています。

上に示したコードセルでは、その後、データフレームのインデックスをリセットし、applymapメソッドを使ってデータフレームの全要素について、値が0でなければ(=500メートル内に対応する列のチェーンの店舗があれば)その値を「1/距離の二乗」に書き換える処理をして、最後に正規化を行っていることも分かります。
「1/距離の二乗」を計算する際には「lambda x: 1 / x ** 2」のように書かずに、reciprocal_func関数を呼び出していますが、これは各要素の値を「1/距離」とするか「1/距離の二乗」とするかを最初は迷っていたからです。ノートブックの先頭では、この関数をどちらにするかを設定しています(最初のノートブックの画像を参照)。
なお、上の画像を見ると、同じことをするコードセルが2つあることが分かります。これはdataフォルダにある開店時/閉店時の周辺店舗情報をデータフレームとして読み込んだ後に、訓練データとテストデータに分割しているからです。もしかしたら、この処理には何か適当な名前を付けて関数化してもよかったかもしれません(あるいは、訓練データとテストデータに分割する前に、上記の処理を行ってもよかったでしょう)。
結合後のデータフレームのインデックスもリセットする必要はなかったなぁと今となっては考えています。リセットしてからドロップするとか、無駄なことこの上ありません。なんでこんなことしているのだろう(恥)。
最後にoutputフォルダには、訓練後のニューラルネットワークモデルに上で見たyokohama_grid.txtファイルから作成したデータフレームを入力して得られた候補地点をCSVファイルとテキストファイルとして出力しています。例えばテキストファイルは次のようになっています。
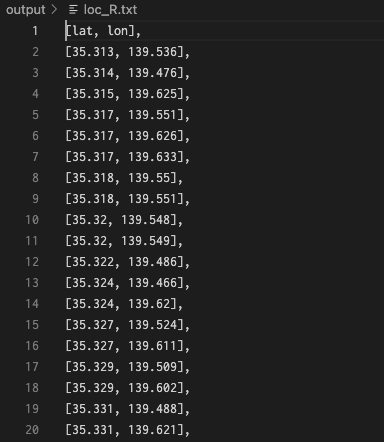
地図とピンを表示するHTMLファイルに書かれているJavaScriptコードにコピー&ペーストできるように出力を整えています。Webサービスのようなものを作るのであれば、もっと別のやり方があるのでしょうが、ここでは手抜きをしました。
次に、実際に推測を行う処理を記述したJupyterノートブックについてザックリと見てみましょう。
Copyright© Digital Advantage Corp. All Rights Reserved.