初めてのデータ分析。手軽に体験してみよう:AI・データサイエンス超入門
データ分析とは具体的にどのようなことをするのか? 全くイメージが湧かない人、自分ではやってみたことがない人に向けて、気軽な疑似体験を通してデータ分析の雰囲気をお伝えします。具体的には、データを整理/変換し、グラフを作成して統計量も計算。さらにデータから次の数値を予測してみます。
最近は、質問に答えてくれるChatGPTなどの文章生成AIや、指示したテキストからイラストが作成できるStable Diffusionなどの画像生成AIが大きな話題ですよね。そういった一般社会で注目される話題の裏で、企業の中やビジネスパーソンの間ではリスキリングやDX(デジタル・トランスフォーメーション)が急激に進んできています。
ある調査の結果によると、この1年で驚くべき変化が起きていました。リスキリング対象者層において「リスキリングに既に取り組んでいる」人が、2022年時点ではわずか1.4%だったのに対し、2023年には42.8%と急増したそうです。この数字からも、リスキリング/DXが急速に進んでいることは明らかです。
リスキリング/DXの現場では、文章生成AIや画像生成AIといった話題の生成系AIよりも、「現在手元にある売り上げデータを分析したい」といったデータ分析のニーズの方が大きいのではないでしょうか(ちなみに本連載では、データ分析を自動化/効率化したソフトウェアを分析系AIと呼んでいます)。そこで今回は、データ分析(分析系AI)とは具体的にどのようなことをするのか? 全くイメージが湧かない人、自分ではやってみたことがない人に向けて、気軽な疑似体験を通してデータ分析の雰囲気をお伝えします。具体的には図1のような分析を体験します。

前回は、データやデジタル技術といった基本概念や、AI/データ分析/データサイエンスの違い、それらがなぜ有用で重要なのかを示し、AIを軸に「AI・データサイエンスの整理と全体像」をまとめました。そこで、AIについて本連載では大まかに、
- 分析系AI: 数値解析、数値予測、分類、グループ分けなど
- 識別系AI: 画像認識、文章の感情判定など
- 生成系AI: 画像生成、文章生成など
という3つに分類しました(※あくまで大まかに分けただけで、この分類では整理しづらいAIや、複数の分類に属するAIもあります)。本稿では、このうち「分析系AI」にフォーカスし、図2の流れに沿ってデータを分析していきます。

連載:
この連載では、人工知能(AI)やデータ分析/データサイエンスをこれまでに学んだことがない社会人(新卒の社会人1年生からベテラン社員まで大歓迎!)に向けて、「データ&AIを活用したいなら、最初に知っておくべき全体概要」、具体的にはAI・データサイエンスの概要と、データ分析(数値予測などの分析系AI)、画像認識などの識別系AI、文章生成などの生成系AIを紹介します。
難しい知識の習得よりもシンプルな経験を重視して、手を動かして体験しながら学べる内容ですので、肩の力を抜いてぜひとも気楽に読み進めてください。
1. データ分析の目標を設定する
今回は、架空のアイスクリーム屋さんの売り上げデータ(100件分)を使って、気温がアイスクリームの売り上げにどのくらい影響するのかを調べます。
さらに、次の日の気温と曜日から、アイスクリームの売り上げ(101件目)を予測します。これによって、「アイスクリームをどれだけ用意すべきか」が事前に把握できるようになりますね。なお、このような予測を自動化するソフトウェアが、いわゆる需要予測AI(前回説明済み)です。
このような目標を設定するには、まず「現在の自社ビジネスにどんな問題があるのか?」といった質問を社内の人に投げかけ、社内の問題を把握することから始めるのが基本です。今回の場合は、「気温が低いとアイスクリームが余ってしまい、気温が高いと売り切れが多くなって、ビジネスの機会を逃している」という現場の声があったと仮定しています。この問題を解決するために、上記の2つの目標を設定しました。
2. データを収集する
今回のデータは、こちらからダウンロードできるサンプルファイル(analytic_ai.xlsxファイル)に含めました。このデータは、生成系AIのChatGPT(GPT-3.5)で、下記のプロンプト(テキスト)を入力して自動生成した後、手動で数値を少しずつ変えるなどして調整したものです。
プロンプト内容: 架空の「アイスクリームの売り上げデータ」をCSV形式で作成してください。日付、曜日、気温、売上金額という列項目で、100件のデータを作成してください。土日は多く売れて、気温が高いと多く売れる結果になるようにしてください。
続きのプロンプト内容×2回: 続きのCSVを生成してください。
なお「<ファイル名>.xlsx」は、(ご存じと思いますが)Microsoft Excel(エクセル)という表計算ソフトのファイル形式です。もし手元のPCにExcelデスクトップ版がインストールされていない場合は、下記どちらかのオンラインツールを使ってください。
- Microsoftのアカウントがあれば使えるMicrosoft 365オンライン(無料版): .xlsxファイルをOneDriveにアップロード(図4)してから開いてください。以降の表計算ソフトの画面は、この環境での作業をスクリーンキャプチャーしたものです。
- Googleのアカウントがあれば使えるGoogleスプレッドシート(無料版): .xlsxファイルをGoogleドライブにアップロード(図5)してから開いてください。上部のメニューバーから[ファイル]−[Google スプレッドシートとして保存]を実行すると(図6)、Googleスプレッドシートとして編集できるようになります。


![図6 上部のメニューバーから[ファイル]−[Google スプレッドシートとして保存]をクリックしているところ](https://image.itmedia.co.jp/ait/articles/2307/13/di-06.png)
本稿では、Excelデスクトップ版ではなく、いずれかのオンラインツールを使用する前提で表計算ソフトの操作方法を説明しています。デスクトップ版の場合、メニューやGUIが説明と少し異なることがある点には注意してください。
データ分析ツールとしてのExcel/Googleスプレッドシート
ご存じの通り、ExcelやGoogleスプレッドシートなどの表計算ソフトには、データの「並べ替え」や「フィルタリング」などの基本的なデータ操作機能が備わっているだけでなく、「集計」や「平均」「相関係数」(=どのくらい影響するか)といった統計量を算出するための計算機能も備わっています。さらに、「売り上げの予測」といった基本的な統計解析もある程度は行えます。
データ分析を専門とするデータアナリストですら、数千〜数万件程度のデータについては表計算ソフトを用いることがあります。ですので、データ分析が本職でない方であれば、まずは表計算ソフトを使ってデータ分析の基礎を学び、基本的なデータ分析ができるようになるとよいでしょう。ちなみに、主に表計算ソフト(Excelなど)を使ったデータ分析については、連載『社会人1年生から学ぶ、やさしいデータ分析』で基礎からステップ・バイ・ステップで学べますので、本稿を読了後、「正式に学びたい」と思ったら、ぜひ続けて読んでみてください。
ただし、数十万件以上の大量のデータを扱う際には、SQLを使ったデータベースやデータウェアハウス、またはPython言語の使用など、より専門的な技術が求められます。Python言語を使ったデータ処理については、連載『Pythonデータ処理入門』で基礎からステップ・バイ・ステップで学べるのでお勧めです。
3. データを整理/変換する: 基本的なデータ操作
それでは、いよいよ本番です。表計算ソフトを使用してデータ処理とデータ分析を行っていきましょう。
まずはanalytic_ai.xlsxファイルを開き、表計算ソフトの下部にあるタブで[生データ]ワークシートを選択してください(※通常は、既にこのワークシートが選択されている状態だと思います)。そうすることで、前掲の図3に示したような表形式データが表示されます。
「このままデータ分析の作業に入ってもよい」と思うかもしれませんが、その考えは危険です。特に手入力されたデータの場合、一部の値が誤って入力されたり、欠損していたりすることがよくあるからです。必ず最初に「データに問題がないか」を調べる習慣を身に付けましょう。ほとんどのデータは、事前の処理が必要であり、そのまま使用することはできません。データサイエンスの世界では、データの前処理に大半の時間(一説には8割)を費やすと言われています。
では、どうやって誤入力や欠損値を見つければよいでしょうか。
誤入力された異常値とは、例えば[気温]が25℃と記録するべきところを間違えて250℃と入力してしまった場合のようなことを指します。欠損値とは、[売上金額]を入力するのを忘れるなどして空白になってしまった場合のことを指します。
表計算ソフトでこれらの問題を発見するためには、「並べ替え」や「フィルタリング」という機能が有効です。並べ替えを使うとデータをある順序に並べ替えられ、フィルタリングを使うと特定の条件を満たすデータだけを表示できます。
「えっ、そんな簡単なこと?」と思ったかもしれませんが、難しく考える必要はありません。さっそくやってみましょう。方法は幾つかありますが、最も手軽なのは、フィルターを作成して作業することです(図7)。

[生データ]ワークシートは元データとしてそのまま残し、下部のタブから[データの整理]ワークシート(=[生データ]ワークシートをコピーしたもの)を開いて作業してください。
まずは、並べ替えやフィルタリングをしたい全ての列を選択します。これには、表の上部にある列見出し(列ヘッダー)の[A]列をクリックしてから[Shift]キーを押しながら[D]列をクリックしてください。
次に、各列にフィルターを作成します。これには、[A]〜[D]列が選択された状態で、
- Excelの場合は、上部にある[ホーム]タブの[並べ替えとフィルター]−[フィルター]を
- Googleスプレッドシートの場合は、選択中のヘッダー部分(図7の例では[C]列あたり)を右クリックし、表示されるメニューから[フィルタを作成]を
クリックしてください。
以上でフィルターの作成が完了したので、並べ替えやフィルタリングをしてみます。
整理:並べ替え
試しに[気温]列を並び替えて、「誤入力された異常な値がないか」を確かめてみましょう。セルC1の右端に表示されている[▼]マークをクリックすると、図8のようにフィルター用のメニューが表示されますので、
- Excelの場合は、[大きい順に並べ替え](降順)を
- Googleスプレッドシートの場合は、[Z→Aで並べ替え]を
クリックしてください。
![図8 [気温]が高い順で並べ替えているところ(左:Excelオンライン、右:Googleスプレッドシート)](https://image.itmedia.co.jp/l/im/ait/articles/2307/13/l_di-08.png)
この並べ替えにより、図9のように[気温]が「250℃」となっている異常値(この場合は、誤入力された値)が発見されました。
![図9 [気温]が「250℃」となっている異常値を発見したところ(Excelオンラインの場合)](https://image.itmedia.co.jp/ait/articles/2307/13/di-09.png)
この例では「250℃」は「25℃」の間違いである可能性が高いので、0を消して「25℃」に手動で修正しましょう。
一方で、例えば「89℃」などであれば、間違いなくおかしいので、その行は削除してしまいましょう。行の削除は、表の左部にある行ヘッダーの該当箇所を右クリックし、表示されるメニューから、
- Excelの場合は、[削除]を
- Googleスプレッドシートの場合は、[行の削除]を
クリックするだけです。
整理:フィルタリング
試しに[売上金額]列をフィルタリングして、「空白のセルがないか」を確かめてみましょう。セルD1の[▼]マークをクリックすると図10のようにフィルター用のメニューが表示されるので、
- Excelの場合は、[すべて選択]をクリックして全てのチェックを外してから[(空白)]にチェックを入れて[適用]ボタンを
- Googleスプレッドシートの場合は、[クリア]をクリックして全てのチェックを外してから[(空白)]にチェックを入れて[OK]ボタンを
クリックしてください。
![図10 [売上金額]が空白のものだけを表示しているところ(左:Excelオンライン、右:Googleスプレッドシート)](https://image.itmedia.co.jp/l/im/ait/articles/2307/13/l_di-10.png)
このフィルタリングにより、図11のように[売上金額]が「(空白)」となっている欠損値が発見されました。
![図11 [売上金額]が空白となっている欠損値を発見したところ(左:Excelオンライン、右:Googleスプレッドシート)](https://image.itmedia.co.jp/ait/articles/2307/13/di-11.png)
欠損値を処理する方法には、
- 削除法: 欠損値を含む行または列を削除する方法
- 補完法: 列の平均値、中央値、最頻値、または特定の固定値を、欠損値のセルに代入する方法や、欠損値と同じデータパターンの行から値を予測して補完する方法など
がありますが、基本的には最もシンプルな「削除法」がお勧めです。
今回は、空白のある行は削除して使わないようにしましょう。行を削除する方法は先ほど説明したので、説明を割愛します。
なお、空白のセルが多すぎて、行の削除が多くなってしまう場合は、その列自体を削除するのがお勧めです。
整理:その他の方法
前掲の図8や図10のフィルター用メニューを見ると、さまざまな方法でデータを整理できることが分かると思います。例えばExcelの場合は[数値フィルター]、Googleスプレッドシートの場合は[条件でフィルター]を使うと、「指定の値より大きい/小さい/等しい」、または「指定の範囲内」といった条件でフィルタリングをかけることもできます。
今回の作業例では、[気温]列で並べ替えを1回、[売上金額]列で空白のフィルタリングを1回しか行っていませんが、本来は各列でさまざまな並べ替えやフィルタリングを行って、データに問題がないかを探しながらデータを整理していきます。
また、本稿では紹介しませんが、条件付き書式も異常値や欠損値を発見するのに有用です。前掲の図7に示したメニューの中に[条件付き書式]という項目があります。この項目から「この数値より小さい場合は、そのセルに背景色を付ける」といったことが可能です。条件に基づきセルに背景色を付けることで、問題のありそうな値を発見しやすくなります。
変換:カテゴリー値を数値に置き換える
データ整理の最後に、「データの変換」を行っておきましょう。
今回は、「(6)データから数値を予測する」ために回帰分析を行う予定ですが、回帰分析では数値しか受け付けません。今回の回帰分析では、「曜日も分析対象として含めたい」と考えています。そのため、「月曜日」〜「金曜日」といった文字列で表現されたカテゴリー(分類)値は0、「土曜日」〜「日曜日」は1といった番号の数値に変換(エンコーディング)しておくことにします。
[データの整理]ワークシートには、既に[曜日]列がありますが、この列の値は文字列(=テキスト)であるため使えません。そこで、[曜日]列の隣に、曜日を数値化した[休日]列を作成することにしましょう。これには、列ヘッダーの[C]列を右クリックし、表示されるメニューから、
- Excelの場合は、[列の挿入]を
- Googleスプレッドシートの場合は、[左に1列挿入]を
クリックしてください。セルC1に[休日]と入力すれば列の準備は完了です。あとは、ここに休日の数値を入力していきます。
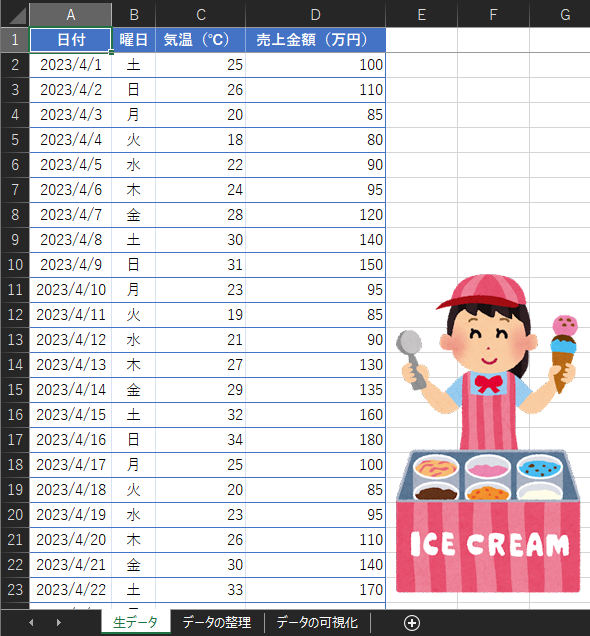
表計算ソフトには、指定した日付から曜日番号(週の開始日を月曜日とする場合は「月曜日=1」〜「日曜日=7」)を取得できるWEEKDAY関数があらかじめ用意されていますので、今回はこれを使って“楽”をします。WEEKDAY関数は、指定した日付が週の何日目であるかを示す数値、つまり「指定した日付の曜日番号」を返してくれます。例えばこの関数に2023/4/1という日付を指定すると、週の開始日を月曜日とする場合、この日は「土曜日」であるため、6という番号値が取得できます。この関数は、
WEEKDAY(<第1引数:日付が入力されたセル>,<第2引数:週の開始日>)
のように書きます。週の開始日を月曜日とする場合は、第2引数に2を指定します。1を指定した場合や何も指定しなかった場合は、週の開始日は日曜日になります。詳しくは、Microsoft公式のサポートページ「WEEKDAY 関数」をご参照ください。
月曜日〜金曜日を0とし、土曜日と日曜日を1とするには、IF関数が使えます。この関数は、
IF(<第1引数:条件>,<第2引数:条件に合致した場合の値>,<第3引数:条件に合致しない場合の値>)
のように書きます。詳しくは、Microsoft公式のサポートページ「IF 関数」をご参照ください。
以上のことから、例えば日付2023/4/1が入力されたセルA2に対する[休日]の値は、
=IF(WEEKDAY(A2,2)>=6,1,0)
と書けばよいですね*1。セルA2の曜日番号が6以上(つまり土日)なら1を、それ以外(つまり月〜金)なら0を返すという意味です。これをセルC2に記入しましょう。
*1 表計算ソフトでは、日付はシリアル値と呼ばれる特殊な数値で管理されています。シリアル値は1900年1月1日を基準にして日数を数えたもので、例えばセルA2の2023/4/1は45017という数値になります(セルの表示形式を「日付」から「標準」や「数値」に変えると確認できます)。
図12は、IFとWEEKDAYという2つのExcel関数を組み合わせた書き方と結果を示した図です。なお、ほとんどExcel関数はGoogleスプレッドシートでも使用でき、実際にWEEKDAY関数の書き方はExcelとGoogleスプレッドシートで同じです。
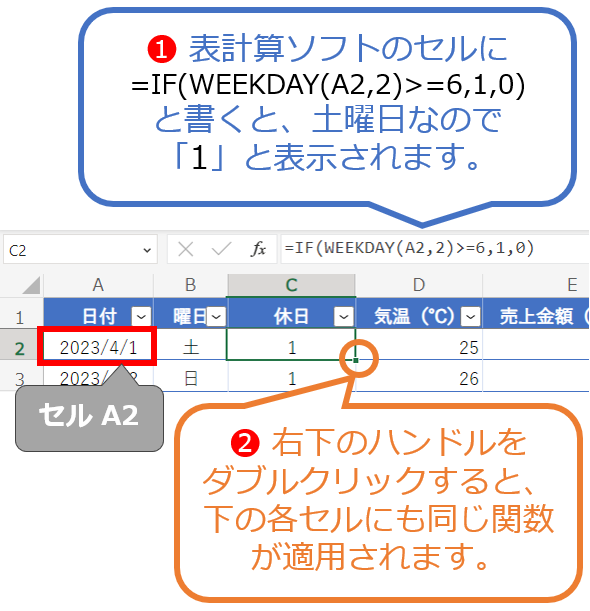
セルA2の日付「2023年4月1日」は土曜日なので、セルC2には、
1
と表示されます。以降のセルC3〜C101も同じように記入する必要がありますが、図12に示しているように、既に入力したセルC2の右下に表示されるハンドルをダブルクリックすることで、以降のセル全てにも同様の関数が適用されます。これによって[休日]の全てのセルに数値が入力されたはずです。
今回は「曜日」を平日(0)か休日(1)かに数値化する方法を紹介しましたが、他には例えば「大好き」「好き」「普通」「嫌い」「大嫌い」という5つのカテゴリー値を1〜5の番号に変換するといったことが考えられます。
以上のように適切にデータ整理とデータ変換を行うことで、データ分析の精度と効率を向上させることができます。
4. データを可視化する: グラフ作成
次に、グラフを作成してデータを可視化してみましょう。
可視化は、複雑なデータを分かりやすく表示することで、データのパターンや傾向(トレンド)、異常値などを、直感的に把握するのに役立つ重要な手段です。今回は、1つ目の目標である「気温がアイスクリームの売り上げにどのくらい影響するのか」という相関関係を、「散布図」というグラフで表現することで直感的に把握してみます。
対象とするデータ範囲の選択
[データの整理]ワークシートはそのまま残し、下部のタブから[データの可視化]ワークシート(=整理作業を終えた[データの整理]ワークシートをコピーしたもの)を開いて作業してください。
ここでは、[気温(℃)]をx軸、[売上金額(万円)]をy軸にしたグラフを作成したいので、まずは、対象範囲を選択しましょう。セルD1をクリックした状態のままセルE100までドラッグすることで選択できます(図13)。なお、先ほどデータを1件削除したので、データ件数は99件になっています。

図13 対象とするデータ範囲を選択しているところ(左:Excelオンライン、右:Googleスプレッドシート)
先頭行の[気温(℃)]や[売上金額(万円)]という項目名がスクロールしても見えるように、先頭行でウィンドウ枠を固定している。これには、Excelの場合は上部にある[表示]タブの[ウィンドウ枠の固定]−[先頭行の固定]を、Googleスプレッドシートの場合は上部にあるメニューバーから[表示]−[固定]−[1 行]をクリックして実行すればよい。
ちなみに筆者の場合、キーボード操作の方が好きなので、セルD1の[気温(℃)]を入力編集中のアクティブセルとした状態で、[Shift]キーを押しながら[→]キーで[売上金額(万円)]を選択し、さらに[Ctrl]+[Shift]キーを押しながら[↓]キーで一番下にあるセルE100までを選択しています。
もしくは、まずセルD1の[気温(℃)]をアクティブにした状態で、[Ctrl]+[Shift]+[↓]キーでD100までを選択。その後、[売上金額(万円)]のセルを[Ctrl]キー(Windowsの場合)/[Command]キー(macOSの場合)を押しながらクリックしてアクティブにし、さらに[Ctrl]+[Shift]+[↓]キーを押すことでD1〜D100を選択します。この操作方法は、例えば[売上金額(万円)]が[気温(℃)]の右隣のセルではない場合にも有効です。
散布図の作成
次に、散布図のグラフを作成します。これには、対象範囲が選択された状態で、
- Excelの場合は、図14のように上部にある[挿入]タブの[グラフ]−[散布図]をクリックしてグラフを挿入し、グラフをダブルクリックすると右ペインに[グラフ]エディタが表示されるので、その上部にある[書式設定]タブ(グラフのオプション)で[横 軸](軸のオプション)−[境界値]−[最小値]に「15」、[最大値]に「40」と入力
- Googleスプレッドシートの場合は、図15のように上部にあるメニューバーの[挿入]−[グラフ]をクリックしてグラフを挿入し、グラフをダブルクリックすると右ペインに[グラフ エディタ]が表示されるので、その上部にある[設定]タブの[グラフの種類]で「散布図」を選択
してください。


図15 散布図のグラフを作成しているところ(Googleスプレッドシートの場合)
※[データからの数値予測]ワークシートと[データ分析の結果]ワークシートに作成例が含まれているが、Googleスプレッドシートには一部の設定が引き継がれないようで正常に表示できないことをご了承いただきたい。表示を修正するには、[グラフ エディタ]の[設定]タブで[ラベルをテキストとして使用する]のチェックを外せばよい。
このグラフ作成により、図16のように右肩上がりのグラフが描画されました。なお、図16はExcelオンラインで作成したグラフの表示例ですが、グラフタイトルや軸ラベルなどの表示も修正しています(その方法の説明は、本稿では割愛します)。
![図16 [気温]と[売上金額]の相関関係が分かる散布図のグラフ表示例(Excelオンラインの場合)](https://image.itmedia.co.jp/l/im/ait/articles/2307/13/l_di-16.png)
散布図の見方の説明は割愛しますが、このように点々がきれいに右肩上がりに並ぶ場合は、「正の相関がある」と捉えられます。詳しくは、「相関係数とは?:AI・機械学習の用語辞典」を参照してください。
5. データの特徴を把握する: 統計量の確認
グラフを確認することで、既に「[気温]と[売上金額]には正の相関関係がありそうだ」と分かりました。それを統計量の数値でも裏付けるために、より具体的な「相関係数」の値も計算してみましょう。
統計量「相関係数」の算出
[データの可視化]ワークシートはそのまま残し、下部のタブから[データの特徴把握]ワークシート(=可視化作業を終えた[データの可視化]ワークシートをコピーしたもの)を開いて作業してください。
図17は、相関係数を算出するための、CORRELというExcel関数の書き方と結果を示した図です。
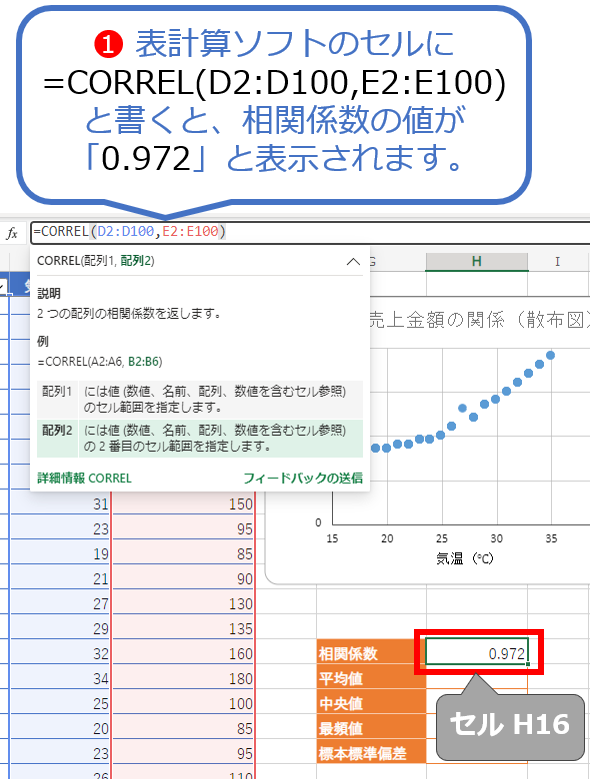
図17に示したように、この関数は、
CORREL(<第1引数:1つ目のデータ範囲>,<第2引数:2つ目のデータ範囲>)
のように書きます。よって例えば、第1引数に<[気温]列のデータ範囲(セルD2〜D100)>を、第2引数に<[売上金額]列のデータ範囲(セルE2〜E100)>を指定するには、
=CORREL(D2:D100,E2:E100)
と書けばよいですね。これを[データの特徴把握]ワークシートのセルH16に記入すると、
0.972
と表示されます。1.0に近いほど「強い正の相関」を意味するので、かなり強い正の相関関係があるということです。CORREL関数について詳しくは、Microsoft公式のサポートページ「CORREL 関数」をご参照ください。
図17にも表示されているように、[データの特徴把握]ワークシートには、平均値/中央値/最頻値/標本標準偏差といった基本統計量を計算する枠も用意しておきました。今回はこれらの計算方法は説明しませんが、[データからの数値予測]ワークシートに関数の入力例を記載しています。これらの計算方法を学びたい方は、連載『社会人1年生から学ぶ、やさしいデータ分析』の第3回と第4回をご一読ください。
6. データから数値(例えば売上金額)を予測する: 回帰分析
ようやく今回の一番面白い部分です。[気温]データから[売上金額]を予測します。AI/機械学習のモデルで予測する方法は幾つもありますが、最もシンプルで基本的な方法が回帰分析です。回帰分析は統計学の手法ですが、機械学習の手法に含められることもあります。
回帰分析はExcel関数として用意されており、関数を1つ呼び出すだけなので非常に簡単です。回帰分析は、「どうしてこのような数値が予測されたか」という理由が明確に分かる(いわゆるホワイトボックス)というメリットがあり、実際のデータ分析でも多用されています。ぜひこの機会に知って、使えるようになってくださいね。
回帰分析による数値予測(機械学習モデルの作成)
[データの特徴把握]ワークシートはそのまま残し、下部のタブから[データからの数値予測]ワークシート(=統計量の算出作業を終えた[データの特徴把握]ワークシートをコピーしたもの)を開いて作業してください。
図18は、回帰分析により予測値を算出するための、TRENDというExcel関数の書き方と結果を示した図です。
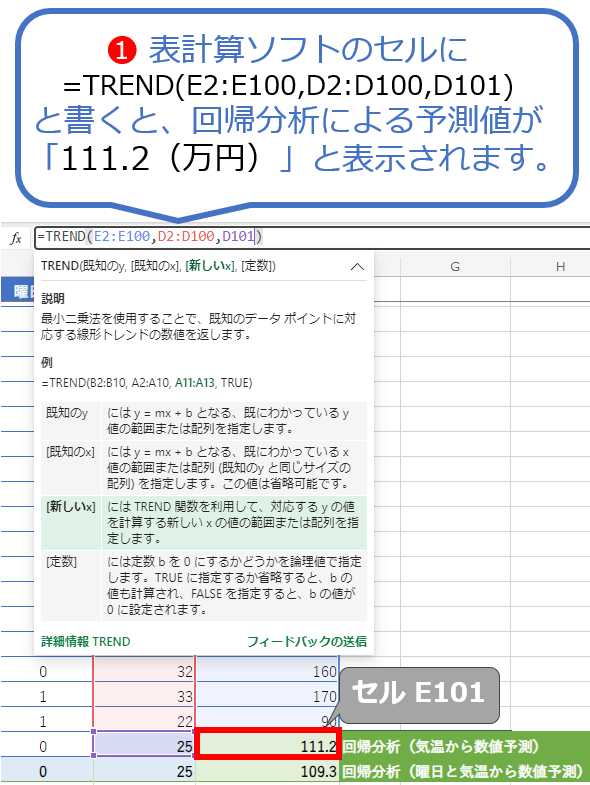
図18に示したように、この関数は、
TREND(<第1引数:予測対象となる既存データ範囲>,<第2引数:予測のために使う既存データ範囲>,<第3引数:新しく予測するために使うデータ範囲>)
のように書きます。よって例えば、第1引数に<予測対象となる[売上金額]列の既存データ範囲(セルE2〜E100)>を、第2引数に<予測のために使う[気温]列の既存データ範囲(セルD2〜D100)>を、第3引数に<新しく予測するために使う「2023/7/10」行の[気温]列のデータ(セルD101=25℃)>を指定するには、
=TREND(E2:E100,D2:D100,D101)
と書けばよいですね。これを[データからの数値予測]ワークシートのセルE101に記入すると、
111.2(万円)
と表示されます。2023年7月10日の予想気温は25℃で、この回帰分析(の機械学習モデル)で売上金額を予想すると111.2万円という意味です。
ここまでの例では、<予測のために使う既存データ>として[気温]だけを使っていますが、[休日]と[気温]など複数の項目を使うこともできます。実際に使うには、第2引数に[休日]列の先頭(セルC2)〜[気温]列の末尾(セルD100)を指定すればよいです。具体的には、
=TREND(E2:E100,C2:D100,C101:D101)
と書くだけです。第3引数も、第2引数と同じデータ項目が必要となるため、新しい[休日]列のデータ(セルC101)〜新しい[気温]列のデータ(セルD101)を指定している点に注意してください。これをセルE102に記入すると、
109.3(万円)
と表示されます。
なおTREND関数では、第4引数として回帰直線の切片(y=ax+bという数学の直線関数のbのこと)となる定数も指定できますが、省略すると自動的に計算してくれます。大半のケースで省略します。TREND関数について詳しくは、Microsoft公式のサポートページ「TREND 関数」をご参照ください。
回帰直線の引き方
回帰分析は、先ほどの散布図に最も近似する直線を引くことと同じです。図16に示した散布図に回帰直線を引くには、
- Excelの場合は、図19のように散布図のグラフをダブルクリックすると右ペインに[グラフ]エディタが表示されるので、その上部にある[書式設定]タブで[系列 "売上金額(万円)"]−[近似曲線 1]をオンにした上で(デスクトップ版の場合は散布図の点々を右クリックすると表示されるメニューから[近似曲線の追加]を選択した上で)、[グラフに数式を表示する][グラフに R-2 乗値を表示する]にチェックを入れ、[外枠]で線の色(赤色など)を選択
- Googleスプレッドシートの場合は、図20のように散布図のグラフをダブルクリックすると右ペインに[グラフ エディタ]が表示されるので、その上部にある[カスタマイズ]タブの[系列]−[トレンドライン]にチェックを入れた上で、[ラベル]で「方程式を使用」を選択し、[決定係数を表示する]にチェックを入れ、[線の色]で赤色などを選択して[線の透明度]で「40%」を選択
してください。


図20 散布図上に回帰直線を引いているところ(Googleスプレッドシート)
※[データ分析の結果]ワークシートに作成例が含まれているが、Googleスプレッドシートには一部の設定が引き継がれないようで正常に表示できないことをご了承いただきたい。表示を修正するには、[グラフ エディタ]の[カスタマイズ]タブ[線の色]で赤色などを選択して[線の透明度]で「40%」を選択すればよい。
ちなみに、図19や図20に表示されているR2(アール2乗)は決定係数と呼ばれる回帰分析の精度(性能)を評価するための指標です。1.0に近いほど良いので、0.945はかなり高精度ということです。回帰分析をより厳密に行うために必要な知識となりますが、今回は取りあえず試すことが目的なので、説明を割愛します。詳しくは「決定係数R2とは?:AI・機械学習の用語辞典」を参照してください。
7. 得られた知見をビジネスに生かす: 意思決定
以上が基本的なデータ分析の流れです。ただし、よくあるケースなのですが、「データを分析してそれで終わり」では意味がありませんよね。せっかくの分析結果を何らかのアクションにつなげるところまでやり遂げましょう。
そのためには、データ分析の結果をまとめたプレゼンテーション資料を作り、例えば上司やチームとの会議で発表し、何らかの意思決定を促す必要があります。今回のデータ分析例では、例えば以下のようなストーリー展開で上司やチームを説得することになるでしょう。
- ビジネス上の課題を提起: 暑い日はアイスクリームの在庫が足りず、寒い日は在庫が過剰になり、ビジネス上の機会損失があるので改善したいと課題を提起
- データ分析: 気温と売上金額に高い相関があることが分かった。また、気温と曜日のデータから、売上金額を高精度に予測できる機械学習モデル(回帰分析の方程式)を作成できた
- AI化: 機械学習モデルによる予測結果を基に適切な翌日の在庫量を自動計算するAIシステムの案を示す
- 投資対効果: AI化による収益改善の効果と、システム化にかかる投資コストを計算し、今回の提案の有用性をアピールする
「どのようなプレゼン資料が効果的か」は、個人や企業、国などの文化によって違う可能性があるので、一概に言えないと思います。プレゼン資料作りの参考としては、デジタル推進人材育成プログラム「マナビDX Quest」という体験型でデータ分析やAIが学べる場(無料)があり、そこでは「他の人がどのようなプレゼン資料を作成するか」を知ることができるのでお勧めです。
今回は、データ分析のエッセンスを一通り体験してみました。「Google データアナリティクス プロフェッショナル認定証」や、上記の「マナビDX Quest」で筆者自身が体験したデータ分析のエッセンスをまとめるイメージで書いてみました。「今回の記事ぐらいの内容なら自分にもできそう」と思ってもらえれば筆者としてうれしいです。
次回は「知識ゼロからのビジネスAI活用。議事録AIを作ってみよう」というタイトルで、音声認識などの識別系AIを体験してみます。お楽しみに。
Copyright© Digital Advantage Corp. All Rights Reserved.