AWSでの法人向けサービス構築と運用準備の舞台裏:AWSでの法人サービス運用トラブル奮戦記(1)
大規模な法人向けサービスの運用担当者が、AWSにおける運用でさまざまなトラブルと格闘した過程を自ら語る本連載。第1回はプロローグとして、サービスの構築とこの段階での運用担当者の関わりにスポットライトを当てる。
こんにちは。セゾンテクノロジーの加瀬と申します。日本発の法人向けデータ統合・連携サービス「HULFT Square」の運用担当者として、維持運用や運用改善、障害対応に携わっています。
このサービスはAmazon Web Services(AWS)上でネイティブなアプリケーションとして稼働しています。当社にとって、大規模なサービスをAWS上で構築・運用するのは初めてだったこともあり、運用では数々のトラブルや想定外の事象に遭遇してきました。
本連載では、私たちが実際に経験したトラブル事象と、そこからの学びをご紹介します。読者の皆さまの運用現場で役立てていただけますと幸いです。
初回は、サービス構成がどのようにして決定され、現在に至っているかについてご紹介します。当初の目論見通りに運んだ部分もあれば、そうでない部分も当然あります。次回からのトラブル事象の紹介につながる前提として、お読みください。
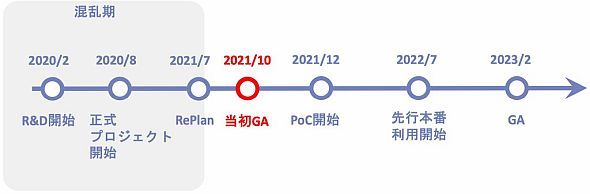
HULFT Squareの開発は、上の図のスケジュールで進みました。今回は、2020年8月のプロジェクト開始から2021年12月のPoC(Proof of Concept)開始までについてお話しします。
サービスはAWS Fargateで構築
HULFT Squareはマイクロサービスアーキテクチャを採用しており、「AWS Fargate(Amazon EKS on Fargate)」で動作しています。
マイクロサービスアーキテクチャを採用した理由は、弊社の別サービスである「DataSpider Cloud」との差別化です。DataSpider Cloudでは顧客ごとに個別のインスタンスを構築しています。このためバージョンアップの際は、顧客の規模にかかわらず、調整した上で全停止が必要です。顧客要望に沿いやすいというメリットはあるものの、サービス更新の速度はどうしても低下します。
HULFT Squareでは、顧客への業務影響を極小化しながら迅速なアップデートを実施することを目指しました。その答えの一つが、マイクロサービスアーキテクチャの採用でした。
社内での経験者が多いAWSを基盤としつつ、ベンダーロックインを極力避け、後のマルチクラウド展開を見据えてKubernetesのマネージドサービスである「Amazon EKS」を採用しました。サービスの検討に当たっては「AWS Well-Architected Review」を実施し、ネットワークの複雑さを回避するため「AWS Transit Gateway」、そしてKubernetes基盤の運用負荷軽減のためAWS Fargateを採用しています。
HULFT SquareではAWSのマルチアカウント管理を行っています。顧客にご契約いただいた際、その顧客専用の新しいAWSアカウントをプロビジョニングします。顧客はHULFT SquareのWebコンソールを通じて専用のAWSアカウント上にリソースを構築することができます。セルフサービスでリソースを作成していただくことで、スモールスタートが可能です。
ここにおいてもFargateを採用するメリットがありました。「Amazon EC2」を基盤とする場合、顧客ごとに複数台構築する必要があり、またそのサイジングは困難です。FargateはEC2と比較して割高ですが、スモールスタートを実現したいHULFT Squareの思想とマッチしていたといえます。
マイクロサービスアーキテクチャも最初からうまくいっていたわけではありません。当初は「full-service」という1つの大きなPodを動かしていました。これをプロジェクトのリプランを通じて1つずつ分けていきました。現在は20弱のサービスが相互に連携して動作しています。
開発段階から運用担当者が参画
HULFT Squareでは、運用担当者も開発プロジェクトのメンバーとして参画しました。本サービスの安定稼働のために必要なことは何か、これまでの運用経験をもとに要件を策定し、日々の運用内容についても設計するためです。そのために必要な機能は、開発担当者と交渉して実装の優先度を高めてもらいました。2022年の3月まではこうした取り組みを進め、4月から7月までの間で、実際に手を動かす運用担当者への引き継ぎを行い、7月からの先行本番利用開始に備えました。
とはいえ、最初はまだ何も運用する対象がありません。そこで、まずは教科書通りに「システム運用に必要なことは何か」を整理することから始めました。例えばお客さまが契約した際のプロビジョニングを手動で実施していては提供が遅れてしまい、また運用担当者の負荷も計り知れません。顧客数が増えていっても、「地獄の運用」を残さないことを念頭に置いて活動しました。
HULFT Squareは米国チームとの共同開発ということもあり、言語の壁や異なる価値観と向き合いながら議論を進める必要がありました。リリース後の定期的なアップデートや、お客さま数の増加によって運用に支障が出ないよう、必要な機能の開発・実装を申し入れるという役回りはとてもタフなものでした。詳しくは、当社CTO有馬の記事を参照ください。
システムのプロトタイプができてくると、運用監視に着手しました。ここでもまずは教科書通りにインフラ観点での監視を導入しました。このサービスを使うときは、どのメトリクスをアラートの対象とすることが多いか、という観点で導入を進めたため、ユーザー視点での監視は不十分なものでした。外形監視でユーザーの操作に関する監視は一部組み込んだものの、しばらくはインシデントが発生するたびに、次に同じ事象が発生したらどのように気付けるかを考えることを繰り返し、監視設定を拡充しました。
特に私たちが注力した「変更・リリース管理」や本項でも触れた運用監視については、また別の回でご紹介します。
おわりに
連載初回では、HULFT Squareが形作られるまでの経緯を簡単にご紹介しました。次回からは実際に運用現場で直面したトラブル事象についてご紹介していきます。
Copyright © ITmedia, Inc. All Rights Reserved.