
Loading
|
||
|
Loading
|
| @IT > システム障害を事前に検知した事例に学ぶ「Systemwalker」のキャパシティ管理 |
|
|
|
富士通の「Systemwalker」は、IT全般統制の評価項目のうち「システムの安全性の確保」「システムの運用・管理」「システムの開発、変更・保守」を支援する統合運用管理ソリューションだ。常にPDCAを回して、システムの安定性・安全性を高めていくマネジメントサイクルをシステム運用の現場に定着させる環境を提供する。 今日のITシステムは「動いていて当たり前」と考えられているので、適切にシステムのキャパシティ(リソースやパフォーマンス)を監視・確認し、サービスレベルを維持する「キャパシティ管理」が大切になっている。「Systemwalker」のキャパシティ管理ツール「Service Quality Coordinator(SQC)」は、「しきい値」によるモニタリングと「基準値」による分析で、トラブルの兆候を事前に予見する。概要については、前回記事「性能トラブルを未然に防止する『Systemwalker』のキャパシティ管理」を参考にしてほしい。 情報システム部門が、小さな異変をいち早くとらえることができれば、エンドユーザーから苦情が出る前に先手を打ち、対処することが可能になる。それこそが本当に求められているビジネスコンティニュティ(事業継続)や高品質なサービスレベルを提供するIT基盤サービスだといえよう。以下、実際にSQCを活用し、事前にトラブルの芽を摘んだ対応事例を紹介しよう。
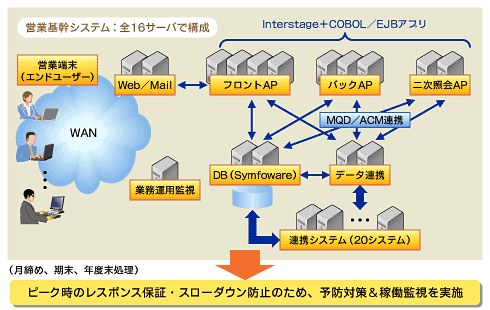
■システムの概要 メーカーの営業部門が利用する、商談支援・販売管理基幹システムで、利用者数は8000人、トランザクションは3000件/時間。財務・経理、手配先、工場系など20のシステムと連携する。システム構成は、図1のように、フロントにWebサーバ、中間にアプリケーションサーバが2段重なり、バックエンドにデータベースサーバが置かれているという一般的な3階層の構造である。
■サーバ機種見直しでCPU使用率が高くなった 同社はデータセンターの移転に伴い、データベースサーバの見直しを行った。その際に、物理マシンを高性能CPUを搭載する機種へとリプレイスした。しかし、変更・稼働後にSQCで性能情報を見てみると、CPU性能は向上しているはずであるにもかかわらず、CPU使用率が大幅に上昇していたのだ。 ■「基準値比較による分析」による分析 サーバを切り替える前と後とを「基準値比較」で分析すると、バッチプロセスが動くときに、特にCPU負荷がかかっていることが分かった。そこでさらにSQCが収集しているCPUの詳細情報へドリルダウンにより確認してみると、以前の状態に比べてCPUの待ち行列が非常に長くなっていることが明確になった。そこでサーバの物理構成を確認してみたところ、CPU性能が大幅に増強されたことで、机上の性能見積もりにより、CPU数を4から2へ見直しを行っていたが、CPU数の見積もりに誤りがあり、極端にCPU負荷が大きくなっていた。 ■対策 同社では、年度末の負荷増加の対策としてCPU数を元に戻すなどの対処をして、問題解決を図った。 もしも、ここで適切な対処ができずにいたらどうだったろうか。トラブルが生じたときに、サーバやCPUなどハードウエアの増強で解決を図るという手段をとったかもしれない。そうなると、新システムへの追加予算計上だけでなく、新システムやそのシステムを導入した情報システム部門への信頼がゆらぐ結果になったことだろう。また、今回はシステムそのものが問題なく稼働を続けていた。とはいえ、「Systemwalker」によりこの先の処理量の増加などによるシステムダウンといったトラブルを予測し、ことが起こる前にこの問題を見つけられた点は大きい。これが「Systemwalker」が目指す、未然防止の在り方だ。
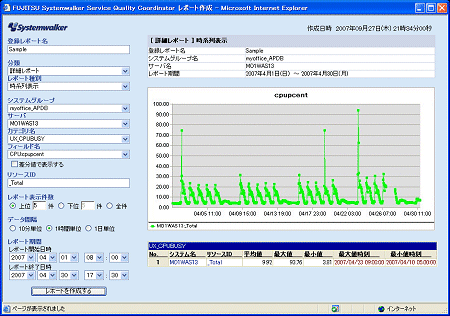
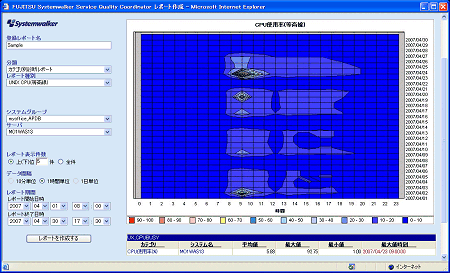
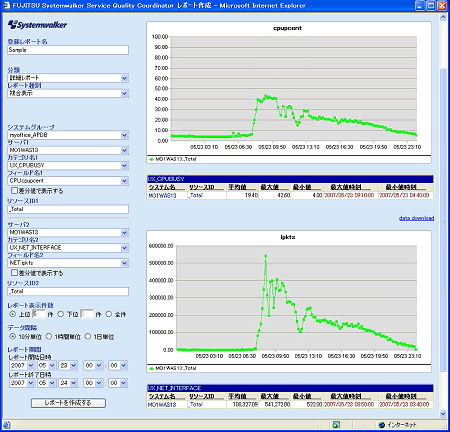
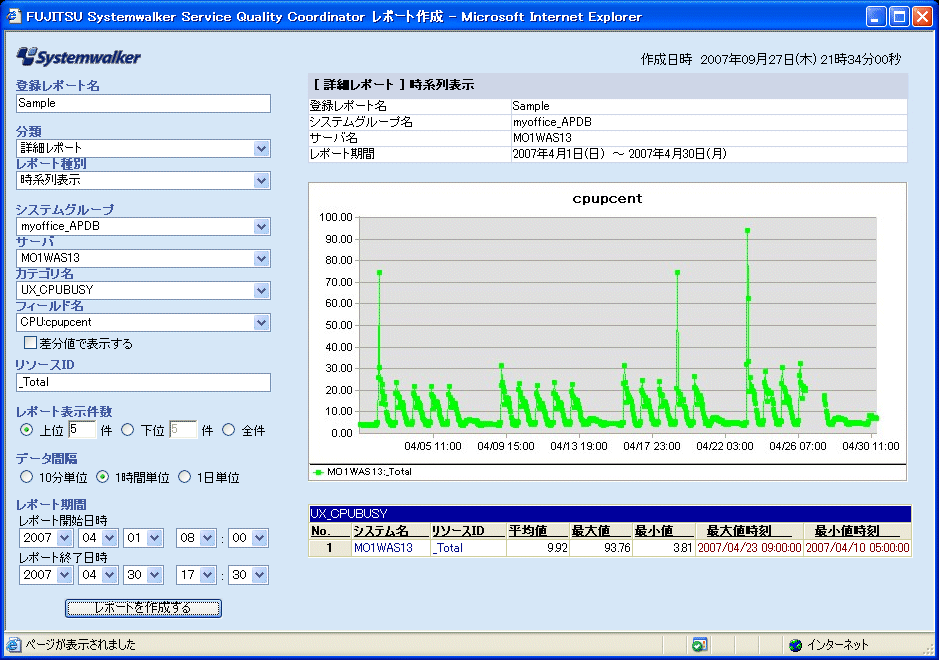
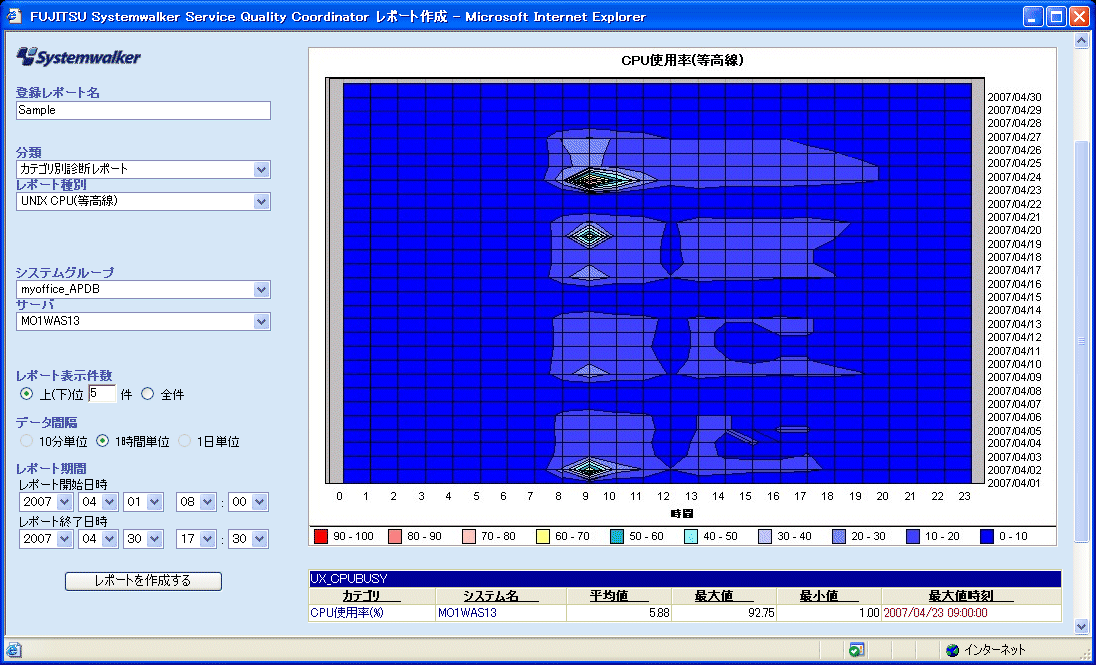
■システムの概要 5000人を超える利用者がある社内のWeb/アプリケーションサーバ。 ■月に数回、CPU負荷の急増により性能劣化が発生 Web/アプリケーションサーバでは月に数回、特定の日にCPU使用率が急増しており、それに伴う性能劣化でWebシステムのスローダウンを招いていた。とはいえシステムは止まっておらず、月に数回のことなのでエンドユーザーからのクレームまでには至っていなかった。しかし、日々の運用でシステムの傾向をつかんでいたことと、「しきい値」監視によるアラートがあがったことで、この特定日のスローダウンを問題視することになった。 ■原因のドリルダウンに効果を発揮したSQCによる分析 情報システム部門はアラートを受けて調査を開始した。そのとき、原因のドリルダウンに効果を発揮したのがSQCだ。 まず、月全体でのCPU使用率の推移(画面1)から、70%を超える高負荷率の日があることが判明。そして、1ヶ月間のCPU使用率の推移を時系列で等高線表示するレポート(画面2)から、始業間もない朝の9時ごろがピークだと確認できた。SQCではプロセス単位でリソース(CPU、メモリ)の使用量を見ることができるため、その日をピンポイントでCPU使用量を調べてみると、そのシステムが動いているJavaプロセスでのCPU使用率が増えていることが判明したのだ。
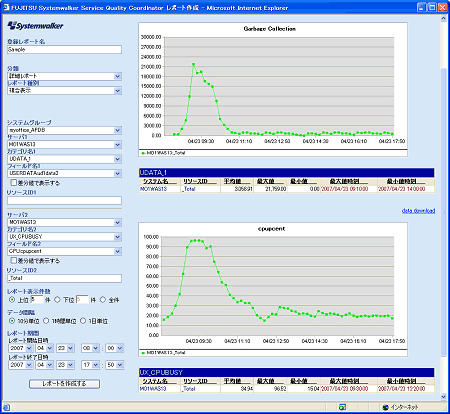
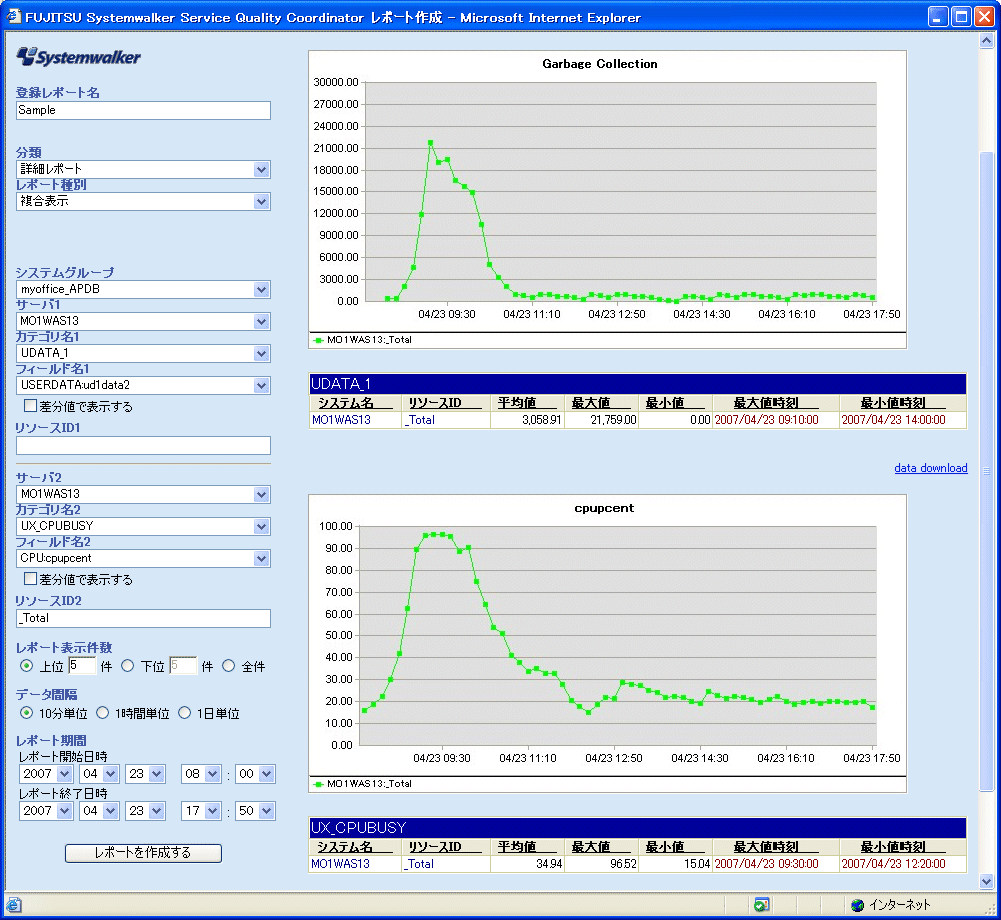
このWeb/アプリケーションサーバは、CPU使用率とネットワークトラフィック(パケット数)が比例することもあり、担当者はCPU使用率の増加は、トラフィック量の増加が原因ではないかと考え、トラフィック量とCPU使用率の相関分析による、乖離度測定を行った。その結果、問題発生日と同様にトラフィック量と乖離してCPU使用率が大きくなっている事象が他の日にも確認することができた。 JavaプロセスでCPUの使用率が高いことから、「Javaの基盤となるガベージコレクション(GC)のメモリ処理が影響している」「利用者数増加により、関連するオブジェクトでの検索処理が多くなっているのではないか」「排他待ちのような負荷があったのではないか」という3つの仮説に絞り込んだ。 ■SQCで収集している情報をもとに調査 SQCではアプリケーションサーバ(Interstage)の詳細を確認することができるため、Javaの詳細レポートでCPU負荷が増加した原因の1つとして想定した、その日のGCの状況を確認したところ、事象が発生していた朝の9時ごろにGC回数が多いことが確認できた。さらに、異なる2つのリソースの使用状況を並べて比較するレポートで、CPU負荷とGC回数との関係も確認したところ(画面3)、両者には相関関係があり、GCの増加がCPU負荷を招いたことが判明した。
■対策 GCが増えたことにどう対処するか――。情報システム部門では、Javaのメモリサイズを増やす対処では、GCの処理コストが増加するため、プロセスを増やして処理可能ユーザー数を多くする対処を行った。8つだったJavaプロセスを16個に変更した。以前は、大量のアクセスにより、70%を超えるCPU使用率となっていたが、今回の対処を行うことでCPU使用率を50%以下に抑えることに成功した(画面4)。
情報システム部門には将来に渡って、継続的なシステムの安定稼働が求められる。SQCは現在までの様々なリソースの使用状況から、将来のリソースの増加を回帰分析により予測することで、今後の投資の最適化を強力にサポートする。 ◇
コンピュータシステムが人の作ったものである限り、どうしてもトラブルは起こるものだ。しかし、トラブルが顕在化してから対応するのと、未然に予兆を検知して対応するのでは雲泥の差だ。これらの2つの事例から分かるように、ノンストップで社内外にサービスを提供し続けるためには、システムは「動いてさえいればいい」というわけではなく、日ごろから「正常に動いている」ことを確認し続けることがIT統制として不可欠なのだ。それを効率よく、正確に行うためには富士通の「Systemwalker」のキャパシティ管理が有効だ。性能情報を監視・分析し、評価する「Systemwalker Service Quality Coordinator」を活用することで、トラブルの兆候を発見し、その問題の切り分けや原因究明、対処方法の妥当性を探ることが容易になる。それは企業の土台となっているITシステムの品質を高めることであり、ひいては情報システム部門の評価へとつながることだろう。 ITシステムが健全に動いていることを保証し、それを通じてビジネスを止めない安心・安全なIT基盤を構築する──それこそがIT統制の真の意味だといえるだろう。
提供:富士通株式会社 企画:アイティメディア 営業局 制作:@IT 編集部 掲載内容有効期限:2007年12月31日 |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
{kind=link}
{kind=link}
{kind=link}
{kind=link}