| そのシステム、“止めないつもり”になっていませんか? ビジネスをジャマしないストレージ戦略を 安価に手に入れよ |
| さまざまな新技術を駆使したシステムを運用するITプロフェッショナルは、いま一度チェックしてみてほしい――そのシステム、本当に「止まらずに運用」できるだろうか。できるとしても、必要以上に多くのコストをかけていないだろうか。本記事では、もう一度「システムがビジネスをジャマしない」という意味を再確認し、来るべきシステムの移行タイミングの前に、必ずチェックしたいポイントを解説しよう。 |
ビジネスをジャマする「クラスタの切り替え」 |
||
稼働系サーバから待機系サーバへ切り替える――この仕組みには大きく分けて3つのステップがある。障害の検知、データアクセス確保、アプリケーションの起動だ。この中で最も気を付けたいポイントは、いかにしてデータのアクセスルートを確保する時間を短くするかだ。
稼働系サーバと待機系サーバで、それぞれストレージを持っていたとしよう。切り替えを円滑に進めるには、関連するデータをすばやく切り替える仕組みが不可欠となる。障害を検知したあと、すばやく切り替えられるようデータ部分を構成する必要がある。この部分の「設計」が信頼性確保のキーになる。腕利きのエンジニアであればその勘所をきっちり作り込めるが、経験の浅い作り手が担当すると、切り替えるために必要以上のダウンタイムがかかってしまう。
当初想定のデータ量/ストレージ量であれば、SLA(サービスレベル契約)通りの時間で切り替えができるだろう。しかし、システムは増設を繰り返すことが常で、いつの間にかSLAをクリアできなくなってしまう。スケールしない「切り替え」では意味がない。
 |
| 解決策は「切り替えない」 |
解決策は、「切り替えない」ことだ。はじめから稼働系サーバと待機系サーバでストレージを共有し、お互いのサーバで常にデータを認識していれば、データの切り替え作業は不要で、データアクセスの確保に要する時間はゼロである。しかし言葉は簡単であるが「お互いのサーバで常にデータを認識」を、データの整合性とパフォーマンスを保って実現するのは技術的には難しい。この仕組みを提供するのが、シマンテックの「Veritas Storage Foundation Cluster File System HA」だ。OSやアプリケーションからは通常のファイルシステムとして認識するため、この仕組みを実現するためにアプリケーションを作り替えたり、熟練のエンジニアを用意したりする必要はない。
ビジネスをジャマする「高価なDR対策」 |
||
止まらないシステムを考えたとき、ディザスタリカバリ(DR)にも注目すべきだ。稼働サーバサイトとDRサイトがさほど離れていない場合、これを簡単に、しかも安価に実現する方法がある。
通常、ストレージのディザスタリカバリを考えた場合、ハードウェアベンダを統一し、同程度のランクのストレージでそろえなくてはならないことが多い。これはつまり、障害発生時にしか使えないシステムのために、高価なストレージを用意しなくてはならないということだ。
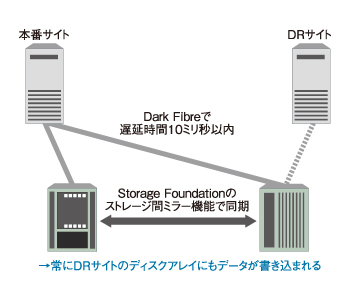
もし稼働サーバサイトとDRサイトが数十キロ程度しか離れておらず、遅延時間が10ミリ秒以内程度であるならば、シマンテックの「Veritas Storage Foundation」(以下Storage Foundation)で安価にDRを実現可能だ。
 |
| 「Storage Foundation」だけでDRが実現可能 |
仕組みは先に説明したStorage Foundationの機能そのものだ。ストレージ間でのミラー機能を利用することで、データがそれぞれのサイトに書き込まれる。このため、いつサイトが切り替わったとしても、データアクセスの確保は問題ない。日本でも渋谷区と港区の拠点を結んだ事例があり、実現のためのノウハウは問題ない。
そして特筆すべきは、そのミラーリングの作業などはすべてソフトウェア上で行われているため、ストレージベンダをそろえる必要はないだけでなく、DRサイトでは安価なクラスのストレージを選択できる。ビジネスを止めない仕組みに幅広い選択肢を提供できることは、Storage Foundationの大きな利点だ。
ビジネスをジャマする「ストレージ空き領域問題」 |
||
「利用者の立場」でいま利用しているファイルサーバを思い浮かべてほしい。そのファイルサーバの空き容量はどのくらいあると安心だろうか。もちろん、その答えは「あればあるだけよい」だ。次に、クライアントPCの「管理者の立場」でストレージの追加を考えてほしい。Cドライブの容量が足りなくなったとしても、ハードディスクは大変安価になったので、大容量のものを購入する自体はさほど問題はない。しかし増設/入れ替えの作業量は考えたくないだろう。
このように、ストレージには3つの課題がある。「将来を見越した必要量が見積もれないこと」「ストレージ単価の下落」「ストレージ追加が容易ではないこと」だ。ハードディスクの大容量化、低価格化のスピードを考えると、必要な容量を必要になったときに追加することが最も賢い選択だ。しかし、ストレージの追加作業は煩雑で、バックアップ作業時にはビジネスを止めなくてはならない。そのため、「なるべく余裕を持った容量を、あらかじめ使えるようにしておく」ことになる。これは使わないストレージ領域を大量に確保することになり、ムダが生じる。
 |
| 物理リソース以上の領域を認識、必要な分を、必要なときに追加できる |
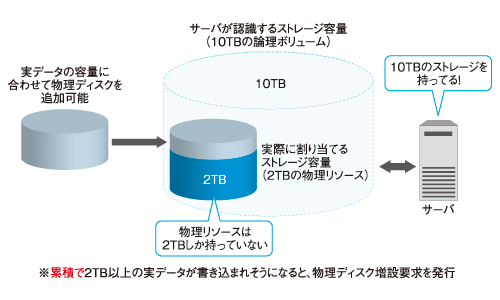
Storage Foundationは「将来を見越して大容量をキープしたい」「必要なときに必要なだけ、しかも簡単にストレージを増設したい」という、利用者と管理者双方の要望を実現するソリューションだ。例えば物理リソースとして、ストレージが2テラバイトあったとしよう。現場から要求された容量が10テラバイトだとしたら、Storage Foundationで論理ボリュームを10テラバイトと設定できる。実際に利用している実データ容量が物理リソースを越えそうになった時点で、管理者にアラートがあがる。そのタイミングでストレージを追加すればいいだけだ。もちろん、ストレージ追加時にシステムを止める必要はない。
Storage Foundationはストレージの利用効率をさらに向上させるため、「シンリクラメーション」という仕組みを用意している。通常、シンプロビジョニングと呼ばれる製品は上記のように「使っている領域」が「物理リソース」を超えないように動作をするが、ファイルを削除しても「使っている領域」として認識したままになっていることが多い。ビジネスで利用するファイルが大容量になっているいま、この仕組みだとせっかくシンプロビジョニングツールを入れているにもかかわらず、無駄が発生する。Storage Foundationのシンリクラメーションは、この削除領域もきっちり認識するものだ。ひと言でシンプロビジョニングといっても、このような点がきっちり行われているのかを選定のキーポイントとしておきたい。
ビジネスをジャマする「仮想サーバ運用問題」 |
||
仮想化の技術に興味のないシステム管理者、経営者はもういないだろう。運用コストを削減でき、サーバの台数を最適化できるソリューションだ。しかし、単に仮想化しただけでコスト削減ができるとは限らない。
一番ありがちな間違った仮想化の例を出そう。Windows、UNIX、Linuxで動く3つのシステムがあり、それぞれが2台1組のクラスタ構成をとっていたとする。VMwareを利用した「仮想化」で、物理サーバ2台のクラスタ構成にそれぞれのOSをゲストとして構成したとする。仮想化により、サーバの台数は確かに減っている。しかし、クラスタを実現するソフトを各ゲストOSのアプリケーションで行おうとすると、いままで通りそれぞれのOS管理者を用意しなくてはならない。統合することで仮想化のメリットがあるのに、運用管理部分が統合できないのでは意味がない。
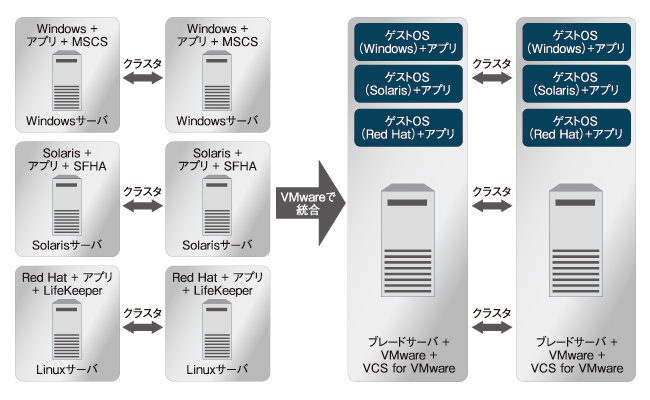 |
| クラスタリングも統合できなければ、VMの意味がない! |
これを解決するのが、シマンテックの「Veritas Cluster Server for VMware ESX Server」だ。VMwareが稼働するホストOS上にインストールすると、VM自体でクラスタリングを実現でき、ゲストOS内のアプリケーションの死活監視までを行うことができる。これは、VMwareに標準添付の監視ツールではカバーしていない機能である。
このツールを利用することで、運用監視はOSを問わず、一元的な管理が可能だ。各OSの知識を持つ運用管理のプロでなくてもいい。これが、本来あるべき「仮想化」の効果だ。
もうシステムは止めません―― |
||
ここまでに挙げたポイントは、シマンテックの「Storage Foundationファミリー」が提供する優位点のほんの一部だ。今回取り上げたような課題を、あなたのシステムも抱えていないだろうか。
そんな悩めるITプロフェッショナルにおすすめのコンテンツを用意した。現場で実際に困っている問題を基にしたWebセミナー「ケーススタディから学ぶ、効率的なストレージ管理とコスト削減の両立」を見れば、より具体的な解決方法が分かるはずだ。
ぜひ、このWebセミナーでストレージ管理の極意を身に付け、システムを止めることのない、安心して運用できるシステムを作り出してほしい。
◆ 「Webキャスト」でもっと詳しく!! ◆ |
|||||||||
|
提供:株式会社シマンテック
アイティメディア営業企画
制作:@IT 編集部
掲載内容有効期限:2010年06月05日
![]()
◆ 「Webキャスト」でもっと詳しく!! ◆ |
|||||||||
|