企業のビッグデータ対応、個別最適に潜むワナを見抜いているか?:ビッグデータ対応、個別最適プロジェクトは「こんなに危険」
データ分析を実行しても成果が上がらない……。近い将来、間違ったデータ分析で苦悩する企業が続出する可能性がある。それを回避するために、いまIT部門が取り組むべき2つのポイントを解説する。
一般企業内でのデータ活用の機運
現在、ビッグデータ活用の機運が一般企業の中でも高まっている。大量データを活用した企業マーケティングの成功事例など、日本国内の先進的企業の取り組みも徐々に聞こえてきている。その背景には、大量のデータを処理・分析するための基盤としてのハードウェアリソースが十分にこなれてきたこともあるだろう。

「データ活用はまず先進的なマーケティングを推進する企業を中心に導入が進みました。現在はそれ以外にも、保有データの活用を検討する企業は日本国内でも増加傾向にあるのです」――日本アイ・ビー・エム ソフトウェア事業 インフォメーション・マネジメント事業部 データマネジメント製品営業部 部長 池田高也氏は、日本国内企業のデータ活用基盤整備の動きについて、このように分析する。
大量データを活用した予測・分析を考える場合、その用途はさまざまだ。例えば製造業では、生産品質の検証を、サンプル調査ではなく全量で実施できるかもしれない。稼働状況や需給計画の予測・分析も考えられる。同様に、需給の情報を基にした財務計画の予測・分析も可能だ。
小売の場合は、日次の売り上げ傾向と販売員の組み合わせに相関関係を見出せるかもしれない。勤務シフトの組み方次第で売り上げを高められる可能性がある。
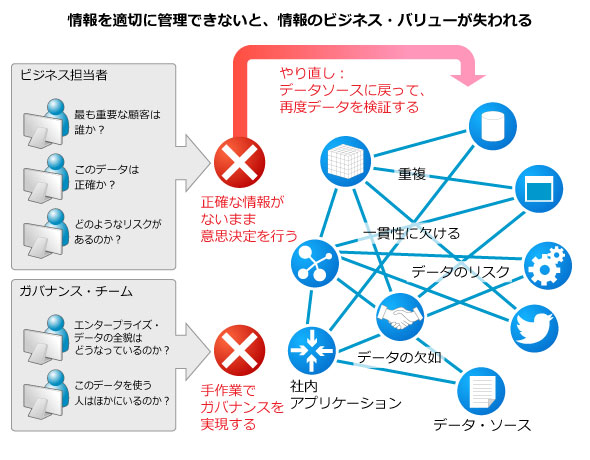
「とにかくやらなくては」日本企業のサイロ化したデータ活用のリスク
確かに、BtoCで展開するeコマース系システムでは個人情報保護の取り扱いには慣れていることだろう。ただし、それ以外の企業ではどうだろうか?
活用プロジェクトは進む、しかし企業内データ活用のナレッジが確立していない
あるデータ分析専門の企業で取材をした際にこんなエピソードを聞いた。取材に対応した担当者いわく「最近は、上司にビッグデータ対応を命じられたものの何をどうしていいのか分からないので教えてほしい、という問い合わせが多い。とにかく何かしらのデータ活用プロジェクトを立ち上げろ、という号令がかかっている」。
部門予算にひも付いたビッグデータ対応プロジェクトがはらむリスク
日本企業の中でも、BtoCでマーケティングに注力している企業では比較的データ活用の方向性が分かりやすい。しかし、そうでない企業の場合、「トライアル的にある一定の目的のため“だけ”に特化したデータ活用を試みるケースが少なくない」(池田氏)。
この場合、部門の予算範囲内で、特定の目的を達成するためだけのシステム構築となる。このため、小さな投資の範囲内で、独自にアプリケーション構築を行うなど、せっかく有益なデータを保有していても限定した目的のためだけにしか利用できないシステムが汲み上がるケースが多いのだという。
「実際にヒアリングをすると、個別の部門予算の範囲内で、特定の目的のためだけにデータ活用基盤構築を進めているケースも増えつつあります」(池田氏)
こうした単独の目的のためだけの基盤構築には、大きなリスクがある。プロジェクトには、その目的に関連したステークホルダしか参加しない、つまり、水平展開の可能性を考慮しないメンバーで構成されているからだ。
欧米先進企業における保有データへの視線
ビッグデータ対応で先行する欧米ではどんな状況なのだろうか。池田氏によると、「欧米では、企業情報システムが保有するデータそのものの価値を正しく企業全体のインフラとして整備・構築し、運用していこうという動きが強い」のだという。
企業内のデータ資産統合や活用については、初期段階から、全社的なデータ活用基盤として整備を進めているのだという。
全社的なデータ統合・活用基盤というと、腰が引ける巨大プロジェクトのように感じるかもしれない。しかし、初期段階で、企業内の「共有資産としてのデータ」をどのように扱い、どの部門でどのように使っていくか、誰が使うべきで、使い終わったデータはどう扱うべきか、といった議論が、将来にわたって関係する部門全体で共有されることから、活用プロセスの整備や、情報そのものに対する統制が格段にスムーズに実現するようになるという。
全部門で同種のデータを分析できるか?
海外販社の売り上げ情報を本社システムと統合するとして、マスターデータはどう管理すべきだろうか? 各々の拠点で各々の会計基準に則した独自システムを導入している場合はどうだろうか? 品目マスタは正しく同じモノを同じとして扱うように統合できているだろうか。
情報システム部門を悩ませるサイロ化したシステム特有の「方言」、地域ごとの会計ルールにひも付いた情報を統合する際には、なにがしかの情報を欠落させてしまってはいないだろうか。本社の顧客IDと支社の顧客ID、子会社Aの取引先マスタと別事業グループの子会社Bの取引先マスタは共通化できているだろうか?海外拠点の品目マスタと本社品目マスタはどうだろう?
システム上、別の企業と設定されているデータをそのまま分析したとして、特定の品目や取引先の真の姿を検証できるだろうか? グローバルで取引のある企業同士の関係を一意に把握できるだろうか?
システムが作り出すさまざまなデータを統合することそのものが、情報システム部門にとっては非常に困難なものに見えるかもしれない。しかし、これらはデータを活用する上での必要最低限の下準備といえる。データの準備ができていないならば、いくらデータを蓄積しても企業内で有機的にデータを活用した知見を得るのは難しい。
情報ガバナンスが確保できていないことが最大の問題である
情報の統合と併せて、情報に対するガバナンスポリシーの有無も今後の企業のデータ活用の成否を決定付ける要因だという。
「データを誰が、いつまでどのような形態で保管し、いつどのようなプロセスでアーカイブ/破棄を行うか、という問題も、データ活用基盤構築の段階で検討すべき問題です」(池田氏)
無限に生成される分析キューブはどうコントロールできるか。分析実行実効後のロジックはいつまで持つべきか。一度生成したレポートのデータは再利用するものか、破棄するものか。こうした問題1つをとっても、分析基盤のリソース設計が大きく変わるのは言うまでもない。
その分析、元データは正確か? 情報ガバナンス軽視のリスク
関心を向ける必要があるのは、企業内に散らばる既存データだけではない。外部データ、非定形データたちをどのように取り込み、生かしていけるかも、併せて十全な準備と検討を行うべき領域だ。
米IDCの調査*は、6年後の2020年にはデジタルデータの容量が現在の44倍になると予想している。一方、データの性質は2年後の2015年には、既に全体の80%を定型ではない「不明瞭なデータ」が占めるという予想が出ている**。ここでいう「不明瞭なデータ」とは、出所が不明、信頼のおけない発信元、正確性が保証されないデータなどを指す。
従来、企業の情報システムはITリソースの制約などにより、最小限の定型データのみを扱ってきた。しかし、これから本格的に幕を開けるビッグデータ活用において、より深い洞察を行うには、不明瞭なデータに対しても一定の情報の品質が維持される必要がある。また、個別最適化が進んでいる既存の企業内システムが保有する各種のデータも、何らかの方法によって横断的に分析プラットフォーム上に置くことが必須となってくる。
同じく米国の調査資料だが、信頼のおけないデータを基にした誤ったデータ分析によって生じる損失は年間6000億米ドルに上るとの調査もある*。分析の元データがそもそも信用できない情報では、たとえ「ビールと紙おむつ」のような相関が見つかったとしても、それは実態のない情報でしかない。その調査のためのデータ収集や分析コストがまるごとムダになってしまう。
* Data Quality and the bottom line report of the data warehousing institute
** The IDC iView, "The Digital Universe Decade ? Are You Ready?" May 2010.
*** http://researchweb.watson.ibm.com/cognitive-computing/index.shtml
データ活用が全社プロジェクトであるべき理由
「ビッグデータ活用基盤整備は全社プロジェクトとして、関係者のコミットが必要です。その理由は、前述した通りだ。個別予算にひも付いた個別最適システムの中「だけ」での情報ガバナンスは、真の全体最適な情報ガバナンス体制には至らない。
では、どのようにすればよいのだろうか?
「まずは全社プロジェクトとして情報の性質、情報のライフサイクルをどう定義するか、といった問題を整理し、全体に対してポリシーを適用していく必要があります。個別最適のデータ統合・活用システムではこの視点が欠落していることが多く、将来的な全社インフラとしてのデータ活用基盤を検討する際の障壁となるリスクが高いのです」(池田氏)
にもかかわらず、日本では、データ活用基盤の構築やそれに向けたプロセス策定についての議論がされないケースが少なくない。その結果、本稿冒頭で言及したような、サイロ化したシステムが乱立してガバナンスが効かない状況が進み始めている。
池田氏はこうした現状が、将来の企業の意思決定速度に与える影響を危惧する。
「保有データの価値を最大限に生かし、かつリスクのない運用を進めるためには、現段階で先を見通した全社プロジェクトを立てることが、最終的なコスト優位につながります。いったん、データ統合・活用の共通基盤やプロセスが構築できていれば、新たな意思決定のためのプロジェクトも迅速に推進できるようになる。」(池田氏)
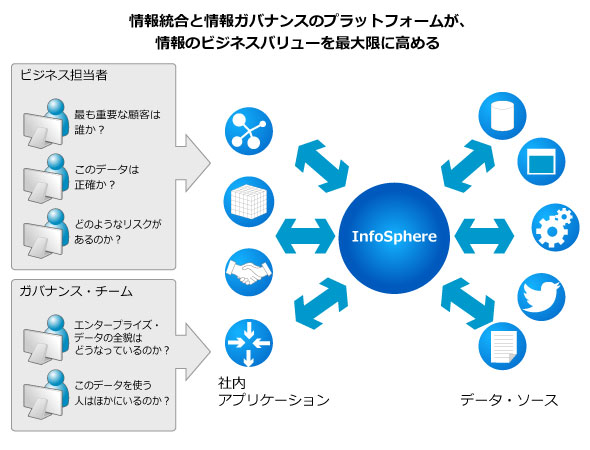
先進企業のケーススタディから組み上げたビッグデータ活用基盤構築プロジェクトのベストプラクティスを知る
日本IBMには、全世界のデータ活用の先進企業のベストプラクティスが既に集約されつつあるという。
「社内共通基盤としてのデータ活用基盤構築のためのプロジェクト推進の手法も、それぞれの情報をどのように定義し、どのようなライフサイクルで管理すべきか、といった方法論も、現段階で体系的なノウハウが整っています」(池田氏)
同社が初期の段階から蓄積したデータ活用基盤構築・運営のためのノウハウの一部は、本稿末にあるドキュメントで確認できる。企業内データ活用基盤整備についての考え方、具体的なプロセスのあるべき姿など、次のプロジェクトとして検討しているならばぜひとも通読してほしい。
この記事に関連するホワイトペーパー

ビッグデータ分析で効果が出ない理由、そして分析コストを回収する有効な方法とは
昨今、多くの企業がビッグデータ分析に取り組んでいる。だが、BIやDWHなどに多額の投資をしていながら、期待する成果が得られていないケースが多い。
この原因として、分析基盤の整備方法や分析スキルの問題も挙げられる。だがそれ以前に疑うべきは「データの信頼性」だ。例えば、各販売拠点の売り上げを分析するとして、品目マスターは同じモノを同じモノとして扱えるように管理できているだろうか?
各部門・拠点間で取引先などのマスターデータは共通化できているだろうか?
システムがサイロ化しているために、複数のソースデータを統合する際、何らかの欠落が起こったりしてはいないだろうか?
いくら分析基盤と人材を整備しても、質の低いデータからは質の低い分析結果しか出てこない。仮に「ビールと紙おむつ」のような相関が見つかっても、その分析結果を現場で適用することができずに、せっかくのデータ収集・分析コストがまるごと無駄になってしまう。では日々データが増え続ける中で確実にデータの信頼性を担保し、短期間で分析ROIを高めるためにはどうすればよいのだろうか?その秘策を紹介する。
※ダウンロードにはTechTargetジャパンへの会員登録が必要です
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
提供:日本アイ・ビー・エム株式会社
アイティメディア営業企画/制作:@IT 編集部/掲載内容有効期限:2013年10月19日
ホワイトペーパーダウンロード

ビッグデータの本格的活用へ向けて、BIやDWH、分析スキルを持つ人材などに多額の投資をしているにもかかわらず、成果を獲得できていない企業が多い。分析の典型的な失敗パターンと投資を確実に回収する方法とは何か?
関連リンク

関連記事(@IT)

近いうちに多くの企業がビッグデータ活用企業になる――その時あなたの会社はどうする? 今年の「Information On Demand Conference Japan 2013」はビッグデータ活用をより手軽に、身近にするための情報が多数見られたようだ。

今回はデータプラットフォームについて、直近で製品発表のあった2社のトレンドをウォッチ。いずれも“データ”の扱い方について、新しいメッセージを示すものとなりました。
近年、商用データベース業界は大規模システムにおける処理能力競争になっています。さらに、クラウドの流行がシステム大規模化のペースを上げているようです。今月はIBMが発表した大規模データ活用を支援するソフトウェアの発表と、Microsoft SQL Serverにおけるハードウェア選択のツボがテーマです。
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。