ミッションクリティカルシステムをクラウドに移行できた3つの技術的背景:技術面から見た「みずほクラウド」の革新性
金融大手みずほフィナンシャルグループが、プライベートクラウド基盤を本格稼働。リスク計測システムを含むミッションクリティカルシステムでもクラウド運用を実現した背景にある技術を探った。
みずほフィナンシャルグループにおいて、ITシステムの運用を効率化し、競争力を高めることを目的として運用されているプライベートクラウド「みずほクラウド」。
みずほ情報総研では「安全性と性能向上を継続維持」「運用効率化によるコスト削減」「スピードと柔軟性」を掲げて、従来のオンプレミスシステムからプライベートクラウドへの移行を推進。現在では、これら全てを妥協することなく追求したプライベートクラウドの運用を実現している。高い性能が求められるリスク管理システムにおいてプライベートクラウドへの移行を実現している点は、特に注目できる。
本稿では、「みずほクラウド」がミッションクリティカルシステムのクラウド移行を実現した背景について、技術的な要因を探っていく。
ポイント1:クラウド化しても安全性と性能向上を継続維持
 みずほ銀行 IT・システム統括第一部 共通インフラ推進チーム 参事役 正木聡氏
みずほ銀行 IT・システム統括第一部 共通インフラ推進チーム 参事役 正木聡氏リスク管理システムでは、市場で取引されている膨大な量のデータを分析し、アセットアロケーション(分散投資)などに使用されている。「みずほクラウド」の中でも、大量のデータを分析し、高速かつ正確な処理が求められることから、富士通のUNIXサーバ「SPARC M10」が採用されている。
「このようなリスク計量分析は、I/Oの負荷が高く、並列度も高い。他のサーバではCPUが耐えられなくなったり、リソースの割り当てがうまくハンドリングできなくなったりしますが、SPARC M10はきちっと処理してくれています。シミュレーションには最適なサーバですね」と語るのは、みずほ銀行 IT・システム統括第一部 共通インフラ推進チーム 参事役 正木聡氏だ。みずほ銀行では、クラウド移行前から性能と品質が求められる領域ではSPARCサーバを利用してきた。
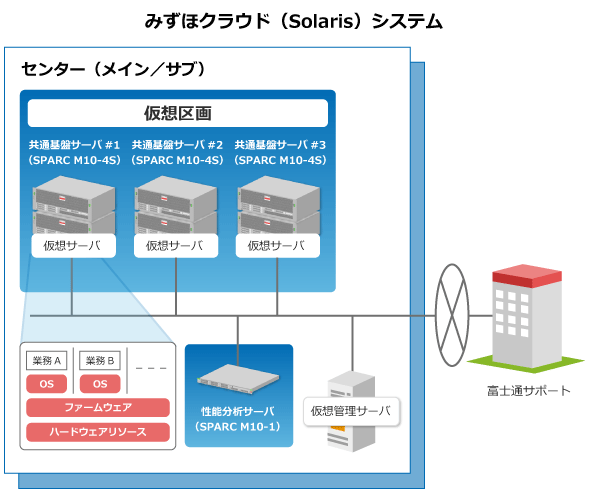 「みずほクラウド」におけるSPARC M10サーバのシステム構成概念図
「みずほクラウド」におけるSPARC M10サーバのシステム構成概念図 みずほ情報総研 銀行システムグループ 共通インフラ事業部第2部 課長 齋藤宏悦氏
みずほ情報総研 銀行システムグループ 共通インフラ事業部第2部 課長 齋藤宏悦氏予告なく立ち上がるバッチ系の処理にも、クラウド化したシステムが耐えられるのか、入念な検証が行われていた。技術面での検証などを担当したみずほ情報総研 銀行システムグループ 共通インフラ事業部第2部 課長 齋藤宏悦氏は当時を振り返る。
「予備検討の早い段階で富士通のラボにサーバを約2カ月間、用意してもらい、考えられる最大のストレスをかけて検証しました。本番環境と同じアプリケーションを動かして、仮想化集約によって問題が起きないかどうか、実際の運用監視がどのようになるかも調べました。結果的にリスク管理システムに必要な性能に見合う製品であったことから、SPARC M10の採用を決定しました」(齋藤氏)
Oracle VM Server for SPARCによるシステム独立性
クラウド環境ではシステムが集約されているため、一度システムトラブルが発生すると、集約したシステム全体が影響を受ける可能性もある。こうした中で、従来のオンプレミスシステムと同等のサービスレベルを維持するには、物理サーバの信頼性は一層重要度を増す。
「みずほクラウド」では、障害隔離性の高い「Oracle VM Server for SPARC(Oracle VM)」を採用している。従来のSPARCサーバで実装されていたOSの仮想化機構 Oracle Solaris ゾーンとは異なり、Oracle VMはハイパーバイザーを使用してファームウェアで分割することができる。複数のインスタンスでOSカーネルを共有することなく、名前空間なども別々に管理できるのである。SPARC M10では、Solaris ゾーンだけでなく、Oracle VMにも対応している。Oracle VMであれば、ファームウェアレベルで完全に分離した状態で集約することができ、かつ他の仮想化機能のように、仮想化による性能劣化もないことから、プライベートクラウドに移行した際にも安定して稼働させられるとの確信を強めたのだという。

ライブマイグレーションによる無停止ローリングメンテナンスの実現
Oracle VMを採用したことにはもう1つ利点がある。ライブマイグレーション機能を使った無停止でのローリングメンテナンスの実現だ。
従来、ミッションクリティカルな――止められないシステムであっても、セキュリティパッチ適用などのメンテナンスを行う際にはどうしてもシステム停止が必要だった。計画時間内にシステムを再開できなかった場合、そのリスクと影響範囲は甚大なものとなる。そのため、事前に各部門との調整が必要であり、手順のシミュレーションなど準備にも多くの時間が必要だ。システム運用者が最も神経を使う作業の1つだろう。
「みずほクラウド」で実現したSPARC/Solarisシステムのクラウド化では、このシステムメンテナンスを、Oracle VMの機能の1つであるライブマイグレーションを使って無停止で実現できるように設計されているという。
この利点は、従来、システム停止の前に必要であった「停止時間の制約」「各部門との停止時間の調整」そのものが不要になる点にある。つまり、システム運用者が必要と思った時に、ユーザー部門の業務に影響を与えることなく必要なタイミングで柔軟にパッチを適用、常に最新の安全な状態で運用できる。
「みずほクラウド」では、常に稼働中のシステムが冗長化できるように、システムを3重化しているという。「ライブマイグレーション機能を使って無停止で順次メンテナンスを行う“ローリングメンテナンス”が可能になったことで、パッチ適用やハードウェアメンテナンスに掛かる工数を削減でき、より安全な運用が可能になっています」(齋藤氏)

ポイント2:運用効率化によるコスト削減

一般に、「安全性と性能向上を維持する」ためには、一定の投資が必要と考えられるため、「コスト削減」の要求とは相反する。しかし、そこでも「みずほクラウド」は譲ることはない。「オンプレミスと比較してどれくらい効率化できるか」――プライベートクラウドを実現しようと考えた場合には、必ず問われる課題であろう。
なんと「みずほクラウド」では、基盤構築だけでも「約7割のコスト削減を実現している」(正木氏)という。その内訳はどのようになっているのだろうか?
プライベートクラウド化で運用コスト削減
1つは、プライベートクラウド化による運用コストの大幅な削減が挙げられる。
従来のオンプレミスシステムでは、システム増強時のOSを含むセットアップや各種パラメーターの設定などを、システムごとに個別に行う必要があったという。一方、プライベートクラウドであれば、構築作業を自動化し、OSのインストール設定情報をもとに自動インストールを実施している。
加えて、メンテナンスに関わる人員も大幅に削減できているという。従来は、個々のサーバで個別の設定が行われていたことから、メンテナンス要員として多くの人員を確保する必要があったという。今回のプライベートクラウド化では、このメンテナンス要員も適正化し、余剰になった人材を別のリソースとして使うこともできているという。
リソースを監視、自動的に可視化
もう1つは、サーバ運用そのものを効率化するソフトウェアの活用による運用効率向上とコスト削減が挙げられる。運用最適化のカギとなったのが、最新のキャパシティー管理ツール「FUJITSU Software Systemwalker Service Quality Coordinator(SQC)」だ。SQCを活用することで、一元的にクラウド全体のリソースの使用状況や性能を細かく把握できるようになった。
「これまでのキャパシティー管理は、各サーバでUNIXコマンドを叩いてデータを入手し、それをExcelに転記して分析をしていました。SQCを導入したことにより、それらの情報は全てデータベース化され、“CPUやメモリがどのくらい余っているのか”“どこの仮想サーバに影響がありそうなのか”という情報も、1つの画面上で瞬時に確認できるようになりました」(齋藤氏)
このSQCは、性能トラブルの解決に役立つだけでなく、リソース再配置やリソース調達計画のシミュレーションにも利用できるなど、運用効率化に大いに役立っているという。

月次のリソース調達計画策定が可能に
SQCを活用することで、常にリソース利用状況をチェックできるようになった「みずほクラウド」では、驚くべきことに月次でリソース調達計画を策定しているという。
従来のシステム調達の方法論では、3〜5年単位でリソース計画を立てるのが一般的だった。このため、調達時には数年先の状況を見越した規模で導入を行う必要があり、「今は使わない」リソースも確保しておかなければならなかった。
しかし、SPARC M10では、業務の増加に応じてシステムを停止せずに処理性能を段階的に強化できる「CPUコア アクティベーション」機能を備えている。つまり、必要な時に必要な量のコアをアクティベートすればよく、コスト効率の良い運用が可能ということだ。
ポイント3:スピードと柔軟性
みずほクラウドでは、「CPUコア アクティベーション」機能を活用し、実際に搭載されている最大コア数のうち、約半数をアクティベートして使用しているという。SPARC M10はビルディングブロック方式の筐体を採用しており、1ノード当たり最大1,024コア、最大2,048スレッドまで拡張できる。
「1つの筐体に入っているコアを一度に全て使っているわけではなく、必要最低限をアクティベートして使っています。アクティベートした後にリソースをプール化して、どのシステムでも使えるように効率化しています」(正木氏)
このような拡張性により、みずほ銀行では業務集約と併せてサーバ台数を随時増強しており、約1年で当初導入したサーバ台数の約1.5倍まで増強している。
サーバ構築期間を2〜3日まで短縮
金融業界では、銀行の資本に関する健全性の規制である「バーゼルIII(※)」という国際的な規制がある。計測結果の応答速度にも一定の決まりが設けられているが、計測方法の見直しも随時行われている。この規制に対応していくためには、システムの増強が必要となり「タイムリーなサーバ調達が可能であること」が1つの重要なテーマとなる。
「以前は、物理的な調達や設置などの準備期間を読んで調達計画を立てなければいけませんでした。“サーバ増強が必要”と判断してから稼働までにおよそ5カ月かかっていたのです。かといって、事前にサーバを多めに調達する計画では利用していないサーバや設置場所に多くのコストが掛かってしまいます。SPARC M10の場合、あらかじめ調達してあるサーバのコア数をアクティベートして準備できますので、サーバ構築作業時間を2〜3日までに短縮できました」(齋藤氏)

マルチベンダーで構成する「みずほクラウド」全体を考慮したサポート体制
このように、富士通が提供するサーバやソフトウェアによって、軌道に乗った「みずほクラウド」だが、みずほ銀行が最も高く評価しているのは、富士通のサポート体制だという。
「富士通はみずほ銀行のシステム環境を熟知しており、単に製品を提供するのではなく、みずほ銀行のシステム運用ルールを加味して総合的に支援する体制を整えています。『みずほクラウド』の開発に着手してから短期間のうちに稼働できたのは、富士通のサポート体制があったからこそ。『みずほクラウド』はマルチベンダー構成になっていますが、富士通はそうした他社製品とつなぐ部分を含めた全体をサポートしてくれたため、高い品質で安定稼働できていると考えています」(正木氏)
「みずほクラウド」は、今後も市場系システムを中心に業務システムの集約を進め、ハードウェアも必要に応じて逐次増強される予定だという。現在は、市場系データを集約して統合管理するデータベース基盤および営業店が利用する市場系システムの開発を進めているという。
*バーゼルIII バーゼル銀行監督委員会が2010年9月に公表した銀行の健全性を維持するための自己資本規制。
注:記事中の所属・職位は取材当時のものです。
関連記事
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
提供:富士通株式会社
アイティメディア営業企画/制作:@IT 編集部/掲載内容有効期限:2016年9月4日
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。