XMLのリンクとジャンプ、API:技術者のためのXML再入門(3)
HTMLの最大の特徴は、インターネットの中を自在にサーフィンできる「ハイパーリンク」機能だといってもいいだろう。この特徴は、XMLにもしっかりと埋め込まれている。しかも、HTMLのハイパーリンクよりもさらに強力な表現が可能だ。今回はそのXMLのリンク機能のほかに、APIや電子署名など、引き続きXMLを「動かす」ために必要な機能についての解説を続ける。
前回に続き、XMLを実際に「動かす」ための関連技術を解説する。今回は、XMLデータを相互に結び付ける技術や、アプリケーションからXMLを操作する技術などを紹介する。
XMLデータ同士のリンク関係を記述する技術
HTMLでは、アンカー要素(A要素)を使って、Webページの特定の文字列や画像をクリックすると別の場所へ飛んで行く「ハイパーリンク」を記述する(リスト1)。XMLでも、このリンク機能を表現できるが、HTMLよりはるかに強力な機能を記述できる。W3CがXMLのリンク機能を記述する規格として策定を進めているのが、これから解説するXLink(XML Linking Language)とXPointer(XML Pointer Language)だ。
<a href="//www.atmarkit.co.jp/">@ITのトップへ</a>
XLink
XLinkでは、XMLデータが保存されたファイルや、XMLの要素・属性、文字列など、リンクを張る対象を総称してリソース(Resource)と呼ぶ。XLinkは、これらリソ−ス間に張られたリンク関係を記述するための言語だ。
XLinkが記述するリンクは、単純リンク(Simple link)と拡張リンク(Extended link)の2つに大別できる。
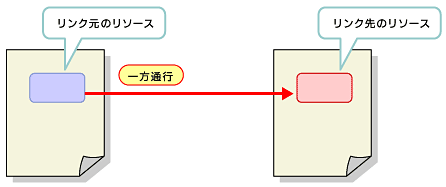
単純リンクとは、1つのリソースからもう1つのリソースへ一方通行で張られたリンクだ(図1)。これは、HTMLで普通に使っているハイパーリンクと似ている。
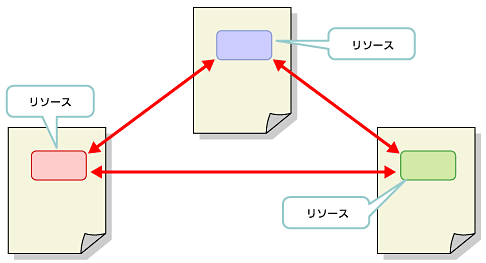
XLinkは、複数のリソースに向かって張られるリンクも記述できる。また、HTMLのハイパーリンクのように一方通行だけではなく、双方向に張られたリンクも記述できる。このリンクのことをXLinkでは拡張リンクと呼んでいる(図2)。
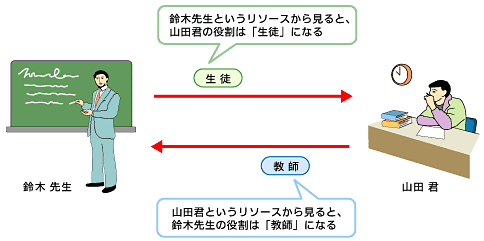
XLinkは、リンクに付加的な属性を付けて、リソースやリンクに意味付けができる。例えば、人が読んで理解できるように、リンクに名前や説明などのタイトルを付けられる。また、アプリケーションが理解できるように、リンクやリソースの種類、あるいはリンク元リソースからリンク先リソースを見たときのリンク先の役割(図3)などを記述できる。さらに、リンク先に飛ぶとき、新しいウィンドウが開かれるのか、それとも元のウィンドウに新しい内容が表示されるのか、などのリンクの振る舞いも指定できる。
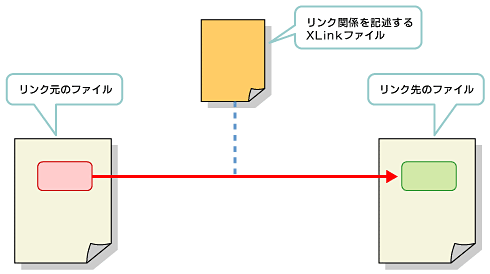
さらに、HTMLの場合、アンカー要素を埋め込んでリンク元を指定したが、XLinkはリンク関係を別のXMLファイルに記述しておける。従って、リンクが張られるリソースに手を加えることなく、リンクを張ることができる(図4)。
ここまでの説明で、XLinkは、HTMLのアンカー要素よりはるかに表現力に富むリンク記述言語だとご理解いただけたと思う。なお、XLinkは、2001年6月にW3Cの勧告になっている。
XPointer
XLinkがリンクの関係を表現する言語であるのに対し、XPointerは、リンクを張る対象を詳細に特定するための言語だ。
XPointerを使えば、リンク先として、XMLデータのファイル全体を指定したり、識別子(id属性など)が付いた要素を指定したりできるだけでなく、同じ要素が順番に並んでいるときのm番目(mは自然数)という指定や、要素内容であるテキストデータのn番目の文字(nは自然数)という指定まで行える(図5)。
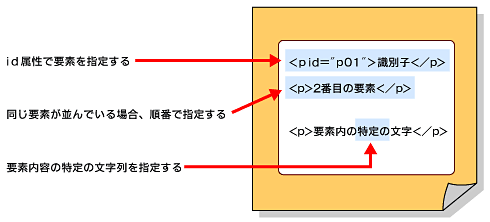
なお、XPointerは、本稿執筆段階(2001年10月)でドラフト段階なので、仕様の変更に注意する必要がある。
XML Base
XLinkは、リンクを張るリソースをURIで指定できるが、毎回、“http://www.atmarkit/fxml/rensai/rexml01/rexml01.html”のように長々と指定するのは煩雑だ。むしろ、基準となるURIを1つ指定しておき(例えば“http://www.atmarkit/fxml/rensai/rexml01/”)、それ以外は基準となるURIから見た相対的な指定(例えば“rexml01.html”)にすれば、簡潔に表記できる。
この表記方法は、XML Baseという規格で定められている。その規格では、先に述べた基準となるURIを基底URI(Base URI)、基底URIを基準にして相対的に表記するURIを相対URI(Relative URI)と呼んでいる。
基底URIと相対URIの例を以下に示す。
<?xml version="1.0"?> <doc xml:base="http://example.org/today/" xmlns:xlink="http://www.w3.org/1999/xlink"> <p>See <link xlink:type="simple" xlink:href="new.xml">what's new</link>!</p> </doc>
リスト2は、“What's new”という文字列から“new.xml”というXMLデータのファイルに単純リンクが張られていることを記述している。ここで“new.xml”という指定は、相対URIでの指定だ。一方、基底URIは、doc要素のxml:base属性で指定されている。この場合は、“http://example.org/today/”だ。従って、この単純リンクのリンク先のURIを厳密に指定すると、“http://example.org/today/new.xml”になるはずだ。
ここで述べたXML Baseは、2001年6月にW3Cの勧告となっている。
XMLデータのためのAPI技術
アプリケーションからXMLデータを操作するためのインターフェイス(API:Application Programming Interface)も、XMLを「動かす」うえで必須の技術だ。さらに、APIが標準化されていれば、同じ開発手法をさまざまな環境で使えるので、開発効率を向上できる。XMLのためのAPIとして標準化されているDOMとSAXを以下に説明する。
DOM
DOM(Document Object Model)とは、W3Cが制定したXMLのためのAPI規格だ。DOMの規格は、次の2つに大別できる。
- XMLのオブジェクトモデル
- オブジェクトモデルを使ってXMLデータにアクセスするためのインターフェイス
XMLプロセッサは、DOMの機能も実装しているのが普通だ(それ以外に、XMLデータの正しさをチェックする、などいくつかの機能を備えているのが一般的)。XMLプロセッサは、たいていファイルとして存在しているXMLデータを一気に読み込み、それをDOM規格が定めたオブジェクトモデルに従うオブジェクトにしてメモリ上に展開する。メモリ上のオブジェクトの集合は、木構造をしていることからDOMツリー(DOM Tree)と呼ばれる。
アプリケーションは、DOM規格が定めたインターフェイスを使って、メモリ上のDOMツリーにアクセスする(図6)。
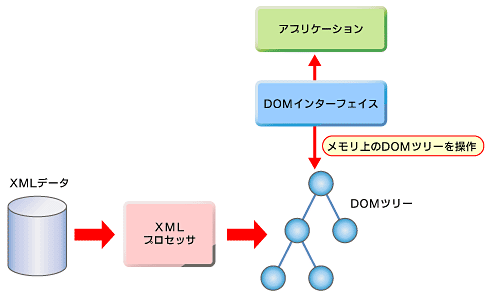
DOMでプログラムを書くと、どのプログラミング言語でも同じインターフェイスを使用できる。しかも、アクセスされるDOMツリーの各オブジェクトは、どんなOS上でも、どんなプログラミング言語を用いても同じ構造だ。従って、APIとしてDOMを採用すれば、特定のプログラミング言語にも特定のプラットフォームにも依存しないアプリケーション開発ができる。
SAX
DOMは、XMLデータ全体をメモリ上に展開してからツリーを操作するやり方だ。従って、XMLのデータ構造を大きく変更する処理なら、DOMの使用は有効だ。しかし、大きなデータを読み込む場合、メモリ上に展開する際のオーバーヘッドやメモリの消費量が大きな足かせになる。そこで、XMLの比較的簡単な処理のために、もっとシステムにかかる負担の少ないAPIが開発された。それがSAX(Simple API for XML)だ。DOMがW3Cで定められたAPIなのに対し、SAXはXML開発者たちがメーリングリストで議論を重ねて開発したAPIだ。
SAXは、一言でいうとイベント駆動型のAPIだ。SAXを実装したXMLプロセッサは、XMLデータを解析しながら、「要素の始まり」や「要素の終わり」などのイベントが発生するたびにアプリケーションに通知する。アプリケーションは、受け取ったイベントに応じて必要な処理を行う(図7)。
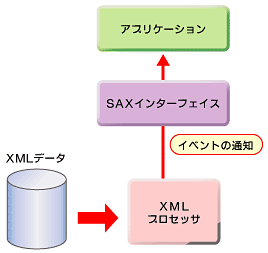
現在、SAXの最新バージョンは2.0だ。バージョン1.0とバージョン2.0とではSAXの仕様が大きく異なるので、バージョン2.0のSAXを特にSAX2と呼ぶ。
そのほかのXML関連技術
XML関連技術は、ここまでで述べたもの以外にも数多くあるが、主に電子商取引に不可欠な技術について、いくつか説明しておこう。
電子署名
インターネット上で電子商取引を行う場合、送られてきた商取引データが確かに取引先が作成したものかどうか、途中で改ざんされていないかどうか、を確認することが必要だ。そのため、紙ベースの書類の署名・押印に相当する電子署名を、やりとりするXMLデータに付与する。W3Cは、XMLデータに電子署名を付与するためのフォーマットの標準化を進めており、その規格をXML Signatureと呼ぶ。
「電子的に署名する」とは具体的にいうと、送信者しか知らないカギと定められたアルゴリズムによって、送信する電子文書のバイナリデータから値を計算し、その計算値を電子署名として電子文書に付与するということだ。XML Signatureという規格は、XMLデータに添付される電子署名の値や電子署名を計算するのに使ったアルゴリズムなどの情報を記述するフォーマットを定めている。
電子署名がXMLデータのビット列を基に計算されるということは、すなわち論理的な内容がまったく同一であっても、表現にささいな違いが生じるだけでXMLデータのビット列が変わり、電子署名のための計算結果が異なってくるということだ。例えば、次の2つの顧客データを比較していただきたい。
<?xml version="1.0"?> <customer id="c001" class="a"> <name>佐藤太郎<name> <e-mail></e-mail> </customer>
<?xml version="1.0"?> <customer class="a" id="c001" > <name>佐藤太郎<name> <e-mail/> </customer>
両者は、意味のうえではまったく同一だが、customer要素の属性の出現順や要素内容のないe-mail要素の表現の仕方が異なっている。すると当然、これに付与されるべき電子署名の値も異なる。
送信された顧客データは、いくつかのアプリケーションによる処理を経て送付先に届けられることになるだろうが、もしXMLデータの解析・再生成を繰り返している過程で上のような表現上の差異が1つでも生じてしまうと、付与された電子署名の値はまったく使えなくなってしまう。
論理的に同一のXMLデータなら必ず同じ結果になるような書き方のルールを定めておき、必ずそのルールに従って正規化してから電子署名を生成するようにすれば、また受信したXMLデータは同じルールで正規化してから電子署名の妥当性を評価すれば、この問題を解決できる。W3Cは、Canonical XMLという規格でこのルールを標準化している。
現在、XML Signatureの文法や処理に関する仕様は勧告候補の段階まで、またCanonical XMLは勧告の段階まで規格化が進んでいる。なお、暗号化/復号も電子商取引には不可欠な技術だが、現時点(2001年11月21日)でXMLの暗号化技術の規格XML Encryptionは、まだドラフト段階だ。
XMLのための照会言語
インターネットおよびXMLの普及によって、Web上に存在する膨大、かつさまざまなデータが、XMLというインターフェイスでアクセスできるようになってきた(図8)。そこで、Webを巨大なデータベースに見立て、あたかもデータベースを照会するかのようにXMLデータを取り出し、しかも望みのツリー構造に組み立てられる照会言語が求められている。その用途のため、W3Cが策定しているのがXMLのための照会言語XQuery(XML Query Language)だ。
これまで、XMLのための照会言語としてさまざまな提案がなされてきたが、XQueryに直接、影響を与えた言語は、ドン・チャンベリン(Don Chamberlin)、ジョナサン・ロビー(Jonathan Robie)、ダニエラ・フロレスク(Daniela Florescu)が提案したQuiltだ。Quiltは、これまでの照会言語の長所をパッチワークのように組み合わせることによって、マニュアルのような文書データや電子商取引データ、さらにデータベース上のデータなど、多様なXMLデータを扱うために設計された。XQueryは、この設計思想を受け継いでいる。
W3Cが定めたXML照会言語の要求仕様によると、XMLの照会言語には(1)人が容易に読み書きできる、(2)XML形式である、の2つが求められて、それぞれの要求を満たす複数の文法があってもよいことになっている。
現時点である程度、仕様が見えてきたXQueryは、(1)の要求仕様に基づくもので、いくらかSQL(Structured Query Language)に似た可読性の高い言語だ。一方、(2)の要求仕様に基づく言語はXQueryXと呼ばれ、XQueryをXML形式に書き直したものだ。
本稿執筆段階でXQueryは、まだドラフト段階の規格だが、今後、広く使われる可能性がある。プロトタイプレベルの実装なら、ソフトウェアAG社やマイクロソフト社などが公開している。一例だが、マイクロソフト社のXQueryのデモサイト「XML Query Language Demo」では、サンプルXMLデータの照会をGUI環境で行える。XQueryの仕様を学習するのに便利だ。
今回のまとめ:XMLを動かす技術
2回にわたってXMLを「動かす」ための主な関連技術を説明した。それぞれの技術がどういうものか、イメージを持っていただけただろうか。今回でXMLの全体像の説明は終了し、次回からXMLの文法の解説に入る。XMLの実際の書き方を学ぶことにしよう。
Copyright © ITmedia, Inc. All Rights Reserved.