XML文書内の位置を正確に指し示すXPath:技術者のためのXML再入門(8)
XMLデータはその構造をツリー形式で表すことができる。XPathは、その性質を利用して、XMLデータのどの部分であっても位置を指し示すことができる記述言語だ。XMLを活用するには、XPathの知識は欠かせない。今回はそのXPathを解説していく。
特定のノードに至る経路を記述する
XSLTはXMLデータ(注)をツリーとしてモデル化したソースツリーのノード(node:節点)ごとに、変換ルールを用意することによって、構造変換を記述する。そのためにはまず、構造変換の対象にするソースツリー内のノードを正確に特定する技術が不可欠だ。W3Cが、XMLツリー上の位置を特定するために制定した記述言語がXPath(XML Path Language)だ。
まず、XPathの記述の原理を説明する。下図のような深い階層構造を持つツリーがあったとしよう。ツリーを構成するノードには、「R」や「A」「B」「C」などの名前が付けられているとする。
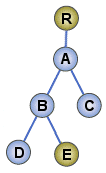
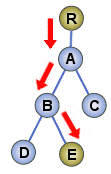
このツリー内の「E」というノードを正確に指し示すためには、どんな表現をすればよいだろうか。「Rを起点にして、まずAに行きます。次にAからBに行きます。さらにBからEに行きます」と表現すれば、あいまいさが残らない。起点となるノードから出発して目的のノードに至る経路(path)を表現すれば、そのままツリー内のノードを特定できたことになる(図2)。XPathは、このアイデアを使ってXMLのツリー上の位置の特定を行う。
ノードで構成されるXPathのデータモデル
XPathのデータモデルでは、XMLデータを以下のノードから構成されるツリーと考える。
●ルートノード 最上位ノード
●要素ノード XMLの要素を表すノード
●属性ノード 要素内で指定された属性を表すノード
●テキストノード 開始タグと終了タグで挟まれた文字列データ
●処理命令ノード 処理命令を表すノード
●コメントノード コメントを表すノード
●名前空間ノード 名前空間を表すノード
例を使って説明しよう。以下のXMLデータを、ツリーで表現してみる。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
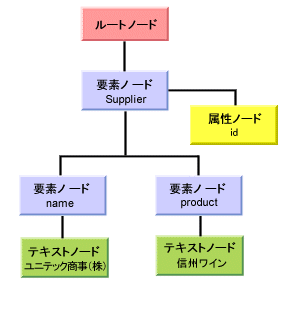
図3を見ると、XMLデータ中の最上位要素(ルート要素とも呼ばれる。ここではsupplier要素のこと)の上に、もう1つ親ノードがあることが分かる。これが前回「XML文書の構造を変えるXSLT」で述べた「ルートノード」だ。ルートノードは、ノード位置を特定するための起点となる大切なノードである。ルートノードとルート要素は別物なので、混同しないようにご注意いただきたい。
図3から、属性もツリーを構成するノード(属性ノードid)と見なされることが分かる。ただし、属性ノードは特別扱いのノードだ。属性ノードは要素に従属しているが、その要素の子ではない。従って、図3のsupplier要素の子ノードを列挙する場合、idという名前の属性ノードは含まれない。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
要素の内容データである文字列もテキストノードという種類のノードだ。テキストノードがさらに子ノードを持つことはない。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
ところで、XMLデータの1行目にあるXML宣言はどうなるのか、と疑問に思われる方もおられるかもしれない。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
XML宣言は処理命令の形をしているが、XML 1.0の構文上、処理命令ではない。従って、処理命令ノードとしてはツリーに現れない。
XPathを使ってノードを指定する
XPathは、XMLツリー上のノードの位置情報を式の形で記述する言語だ。XPath式による評価結果は、値やノードやノードの集合で返される。XPath式の書き方には、厳密かつ詳細に記述する書き方と、簡略に記述する書き方の2つがある。後者は、ファイルのディレクトリ構造の記法に似ていて直感的に分かりやすい。そこで、本記事では後者を用いることにする。
要素の指定
図3の例を使って、XPath式の書き方を具体的に示す。以下のXPath式をご覧いただきたい。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
「/」という文字は、XPath式の一番左に現れるとき、ルートノードのことを意味する。このXPath式は、「ルートノードを起点として、ルートノードの子であるsupplier要素の、さらに子であるname要素を返しなさい」という意味になる。
ルートノードから一足飛びにノードを指定する方法もある。次のXPath式は、「ルートノードを起点として、ルートノードの子孫となる(つまり孫でもひ孫でも構わない)name要素を返しなさい」という意味になる。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
要素の内容データの指定
name要素の「要素の内容」を指定したい場合はどう表現したらよいだろうか。これは、name要素の子であるテキストノードを指定すればよい。XPath式は以下のとおりだ。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
XPath式の最後に出てくる「text()」は、テキストノードを指定するための特別な書き方だ。上のXPath式の意味は、「ルートノードを起点として、ルートノードの子であるsupplier要素の、さらに子であるname要素の、さらに子であるテキストノードを返しなさい」という意味になる。
ところでXSLTを利用して、name要素の「要素の内容」(すなわち「ユニテック商事(株)」)を結果ツリーに出力したい場合、どのように記述したらよいだろうか。第7回「XML文書の構造を変えるXSLT」に述べた文字列出力のためのXSLT命令、xsl:value-of要素のselect属性に、このテキストノードを指定すればよい。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
name要素の「要素の内容」を出力するための厳密な記述は上のとおりだが、実際は以下のように記述しても同じ結果になる。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
同じ結果になる理由を説明しておこう。xsl:value-of命令の機能を正確にいうと、select属性で指定されたノードの「文字列値」を出力することだ。XPathのデータモデルによれば、要素ノードの文字列値とは、その要素の子孫として存在するすべてのテキストノードの文字データを連結した値だ。ある要素ノードが子としてテキストノードだけを持つならば、その要素ノードの文字列値とはテキストノードの文字データと同じだ。
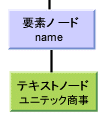
図3のname要素は、子孫のテキストノードを1つだけ持っている。従って、name要素の文字列値とは、子テキストノードの文字データである「ユニテック商事(株)」となる(図4)。
上記の理由から、「/supplier/name/text()」と指定した場合と「/supplier/name」と指定した場合のxsl:value-of命令の出力結果が同じになったのだ。
属性の指定
属性ノードを指定するためには特別な記号「@」を用いる。以下のXPath式は、「ルートノードを起点として、ルートノードの子であるsupplier要素のidという属性ノードを返しなさい」という意味になる。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
XPathのデータモデルによると属性ノードの文字列値とは、属性値のことだ。従って、XSLTでの属性値の出力は以下のように記述する。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
要素の集合の指定
次に、同じ要素名を持つ要素が複数、存在するケースを考える。リスト2の仕入先情報(その2)を例に使う。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
この場合、以下のXPath式は、どんな結果を返すだろうか。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
XPath式の意味は、「ルートノードを起点として、ルートノードの子であるsupplier要素の、さらに子であるproduct要素を返しなさい」という意味になる。リスト2を見て分かるとおり、この記述に当てはまるproduct要素は3つある。従ってこのXPath式は、すべてのproduct要素を集めたもの、すなわち要素の集合(node list)を返す。
2番目のproduct要素だけを指定したい場合は、以下のようにすればよい。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
XPathには、ここで紹介した方法以外にも多様な記述方法がある。詳しくはW3CによるXPathの仕様書か、ほかの参考書をご覧いただきたい。
絶対ロケーションパスと相対ロケーションパス
ここまでは、XPathの指定としてルートノードを起点としてノード指定を行う方法を紹介してきた。この指定方法は、絶対ロケーションパス(absolute location path)指定と呼ぶ。
一方、カレントノードを起点としてノード指定を行う方法もある。これを相対ロケーションパス(relative location path)指定と呼ぶ(図5)。
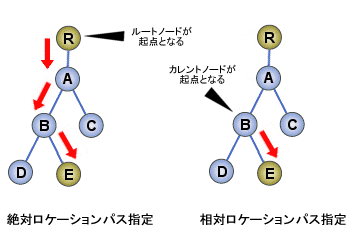
相対ロケーションパス指定を上手に使えば、シンプルで柔軟な構造変換の記述ができる。そのため、スタイルシートの記述では相対ロケーションパス指定がしばしば用いられる。
XSLT初学者が犯す間違いの多くは、ノード指定の際に生じる。特に相対ロケーションパスを使ってノードを指定する場合、カレントノードの把握が十分でないと予想外の結果になってしまう。思うように構造変換ができないときは、一度、XPathをじっくり見直してみるとよいだろう。
XSLT - テンプレート規則がないノードの処理
XPathの説明が終わったところで、前回の「XML文書の構造を変えるXSLT」の続きに戻ろう。XSLTの構造変換の記述とは、ソースツリーのノードに対してテンプレート規則を用意することだ。では、XSLTプロセッサが処理しようとしたノードにテンプレート規則が用意されていない場合、XSLTプロセッサは何をするのだろうか。
実は、これはエラーにはならない。テンプレート規則が記述されていないノードは、XSLT仕様が用意している「デフォルト」のテンプレート規則を適用する。このデフォルトのテンプレート規則のことをビルトインテンプレート規則(built-in template rule)と呼ぶ。
ルートノードやある要素ノードのためのビルトインテンプレート規則の変換ルールは簡単だ。ルートノードやある要素ノードにマッチするテンプレート規則がない場合、XSLTプロセッサは結果ツリーに何も追加せず、すぐにその子ノードの処理に移る。
一方、テキストノードのためのビルトインテンプレート規則は注意を要する。あるテキストノードにマッチするテンプレート規則がない場合、XSLTプロセッサは結果ツリーにそのテキストノードの文字列値を追加する。つまり、マッチするテンプレート規則がないと、XSLTプロセッサは、テキストノードの文字列値を「黙って」結果ツリーに出力してしまう。
このことを、リスト1の仕入先情報を使って例証しよう。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
これにリスト3に示すスタイルシートを適用したとする。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
リスト4の結果ツリーを得るつもりでこのスタイルシートを書いたとするなら、結果は大違いだ。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
リスト3では、name要素およびその子テキストノードのテンプレート規則が明示されていない。name要素を処理する段階になると、XSLTプロセッサは要素ノードのためのビルトインテンプレート規則を適用して、結果ツリーに何も追加せずに、すぐにその子ノードであるテキストノードに処理を移す。name要素の子テキストノードのテンプレート規則もないので、XSLTプロセッサは、テキストノードのためのビルトインテンプレート規則を適用する。結果として、name要素の子テキストノードの「ユニテック商事(株)」という文字列が、結果ツリーに「ひょっこり」出現することになる(リスト5)。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
XSLT初学者の中には予期しない文字列が出力されて困惑する方がいる。それはビルトインテンプレート規則の仕業であることが多い。
リスト4の期待された結果ツリーを生成する方法は幾通りかある。簡単な方法は、supplier要素から子ノードへ処理を移す際、product要素のテンプレート規則だけを選択するよう記述すればよい。テンプレート規則を指定していないname要素以下に処理が移って、ビルトインテンプレート規則が適用されてしまう事態を回避するのだ。xsl:apply-templates要素にselect属性を付加すれば、ジャンプ先のテンプレート規則を選択できる(リスト6)。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
次回で扱う内容
XPathを使ったノード指定の方法について基本的な事柄を解説した。次回はXSLTの解説を続ける。XSLTのプログラム的な側面や複雑な処理に注目し、優れたデータ操作性を解説しよう。
Copyright © ITmedia, Inc. All Rights Reserved.