第5章 C#のデータ型:連載 改訂版 C#入門(4/4 ページ)
C#のデータ型は実によくできている。基本的なデータ型は構造体の別名であり、値型と参照型やボックス化により、軽量ですっきりしたコードが書ける。
5-7 ボックス化
複数のデータを一括して扱う処理を記述する場合に、どのようなデータでも収納できる便利な機能を記述できるとプログラムがすっきりする。だが、実用言語で、これを達成したものは多くない。例えば、Javaでは、数値型がクラスではないため、任意のクラスのインスタンスを扱う入れ物となるクラスを設計しても、そのままでは数値を格納できない。そのため、数値を格納するラッパ・クラスのインスタンスに一度数値を入れてから、それを格納する必要がある。Visual Basic 6.0のVariant型は何でも格納できるのだが、その代わり、値を入れるときは普通の代入、参照を代入する場合はsetステートメントと使い分ける必要がある。
これに対して、C#は、すべてのクラスのスーパークラスをたどっていくと最後にたどり着くobject型に、すべてのデータの参照を格納することができる。ちなみに、objectはSystem.Objectの別名である。実際に、整数、実数、文字列、構造体、クラスの5種類の情報を1個のobject型の配列に代入できる例をList 5-7に示そう。
1: using System;
2:
3: namespace Sample007
4: {
5: public struct 構造体1
6: {
7: // 中身はない
8: }
9:
10: class Class1
11: {
12: [STAThread]
13: static void Main(string[] args)
14: {
15: object [] test = new object[5];
16: test[0] = (int)1;
17: test[1] = (float)0.1;
18: test[2] = (string)"Hello!";
19: test[3] = new 構造体1();
20: test[4] = new Class1();
21: for( int i=0; i<5; i++ )
22: {
23: Console.WriteLine( "Class={0}, Value={1}", test[i].GetType().FullName, test[i].ToString() );
24: }
25: }
26: }
27: }
見慣れない記述もあると思うので解説する。23行目のGetType()はデータ型に関する情報を得るためのメソッドである。どのオブジェクトに対しても使用できる。そして、FullNameは、そのデータ型のnamespaceを含むフルネームを得るためのプロパティである。
もう1点補足するなら、クラスや構造体に対して、ToString()を呼び出すと、特にほかの機能が定義されていないかぎり、そのクラスや構造体の名前を返す機能がC#には備わっている。
このコードは、これまでの解説から考えればありえないコードである。なぜなら、objectはクラスであり、クラスは参照型であって、値型とは違うからだ。値型の整数が簡単に代入できるわけがない。つまり、値型である整数、実数、文字列、構造体はobject型に代入できないのが筋なのである。
にもかかわらず、これはコンパイルでき実行できる。実行結果をFig.5-7に示す。
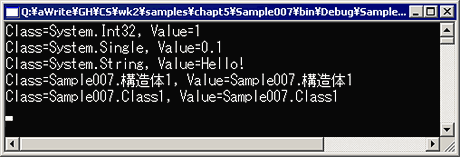
種明かしをしよう。これは、ボックス化という機能によって実現されている。値型の値をobjectなどの参照型に代入しようとすると、ボックス化という機能が自動的に挿入される。ボックス化は、値型を包み込むクラスを自動的に生成する。クラスは参照型なので、そのまま参照型として利用できる。この機能により、object型の変数には、C#のあらゆる型のデータへの参照が代入できるのである。これにより、どんなデータ型でも収納できる便利なクラスが非常に作りやすくなっている。また、ソース・コードもすっきりと見通しがよくなる。
ただし、ボックス化は万能ではないことに注意してほしい。ボックス化とは要するに、暗黙のうちにクッションとなるインスタンスを自動的に生成して、その中に値型の値をコピーすることを意味する。つまり、もともとの値型の値を参照するわけではないのである。また、あくまでボックス化はデータをコピーする行為であるため、もとのデータを変更しても、それが反映されるわけではない。
このようにボックス化は便利ではあるが、込み入った使い方をしようとすると、トラブルのもとになる場合もある。値型と参照型の違いは、きちんと意識して利用するようにしよう。
Column - UnicodeとシフトJIS -
本連載は文字コードの解説書ではないので、文字に関する詳細な説明には踏み込まない。しかし、多くのC#入門者が迷う問題でもあるので、簡単に文字の問題に触れておく。
CやC++では、プログラミング言語で扱う文字の種類は特に決められていない。そのため、UNIXワークステーション上ではEUC-JPというコード体系を扱い、PC上ではシフトJISというコード体系を扱っていることも珍しくはない。これに対して、Javaやバージョン4以降のVisual Basicでは、文字はUnicodeによって扱われることが決められている。
Unicodeとは、全世界で使用される主要な文字を集めた文字集合である。UnicodeはUnicode Consortiumという有志企業の集まりにより作成されているが、ほぼ同等の国際規格として、ISO/IEC 10646も存在する。多くの標準規格や標準仕様からはISO/IEC 10646のほうが参照されている。日本では、JIS X 0221としてJIS規格にもなっている。ここでは、それらを代表して、Unicodeという名前で表記する。
Unicodeには世界中の文字が収録されているが、それはコードに割り当てられているということであり、フォントにすべての文字が収録されているという保証はない。多くのフォントは、特定の目的に必要な文字群のみを収録している。例えば、Windowsに標準で付属するMSゴシックなどは、日本語で使用される文字を中心に収録されており、すべての言語のすべての文字が収録されているわけではない。そのため、表示する内容によってはフォントの切り替えを必要とする。
Unicodeには、従来日本で多く使われてきたJIS X 0201、0208、0212などの文字規格に含まれる文字がすべて収録されており、EUC-JPやシフトJISからUnicodeに切り替えることで、使用できる文字の種類が減ることはない。そのため、何となく漠然と使っていると、Unicodeを使っているという実感が湧かないままUnicodeを使用してしまう可能性もありうる。しかし、異なるコード体系であるため、挙動に相違する部分があることに注意が必要である。
まず、Unicodeは、すべての文字が16ビットを単位とする値の組み合わせによって表現されることに注意が必要だ。16ビットを単位とする、ということは、1文字がいくつかの16ビットの単位の組み合わせで表現されるということを意味する。日本語で使用される主要な文字は、ほとんどすべて16ビットの単位1つで表現できるため、「1文字=16ビット」と理解するのが最も手っ取り早い。しかし、これは、すべての言語、すべての文字に適用することはできない原則なので、注意が必要である。
さて、単位が16ビットである以上、1バイト文字や2バイト文字という概念は、Unicodeには存在しない。例えばコンソール上に表示する文字幅を計算するために、1バイト文字と2バイト文字を区別したいという状況はしばしば発生するが、これを文字のバイト数の違いとして取得することはできない。CやC++プログラマーなら、文字「A」は長さが1で、文字「あ」は長さが2と理解していたかもしれないが、C#においては、どちらも長さは1である。C#における1は16ビットに相当する。もし、表示幅の違いを調べたいなら、フォントの情報を調べ、個々の文字ごとの文字幅(ピクセル値)を調べるか、一度シフトJISに変換したうえでバイト数をカウントする必要がある。
シフトJISに変換して調べるには、シフトJISの文字コード体系(エンコーディング)を内容として持つSystem.Text.Encodingクラスのインスタンスを取得しなければならない。そのためには、System.Text.EncodingクラスのSystem.Text.Encoding.GetEncodingメソッドを使用する。そして、System.Text.EncodingクラスのGetByteCountメソッドが、変換後にそれが何バイトになるかをカウントしてくれる。以下はそれを用いた例である。
1: using System;
2:
3: namespace Sample008
4: {
5: class Class1
6: {
7: [STAThread]
8: static void Main(string[] args)
9: {
10: System.Text.Encoding encoding = System.Text.Encoding.GetEncoding("Shift_JIS");
11: Console.WriteLine( encoding.GetByteCount("A") );
12: Console.WriteLine( encoding.GetByteCount("あ") );
13: Console.WriteLine( encoding.GetByteCount("\x4e02") );
14: }
15: }
16: }
このサンプル・ソースの実行結果を以下に示す。
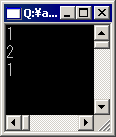
見てのとおり、「A」に対応する値が1で、「あ」に対応する値が2となることが分かる。しかし、シフトJISに変換できない文字は正しく処理できない。13行目の「\x4e02」とは、Unicodeに収録された漢字の1つを示すコードを16進数表記したものだが、これに対応する文字がシフトJISにはないため、半角「?」に変換され、結果として「1」が出力されてしまっている。
ファイルなどを読み書きする場合も注意が必要だ。C#から.NET Frameworkのクラス・ライブラリを呼び出してファイルなどを作成した場合、何も指定せず文字列を書き込むと、それはシフトJISではなく、UTF-8で書き込まれる。
Unicodeはそのままでは文字に番号を与えたものにすぎず、それを具体的にどのようなビット表現に置き換えるかは、いくつかの選択がある。主な手段としては、UTF-8とUTF-16がある。UTF-8は、US-ASCIIコードに互換性があるもので、0x00〜0x7fの範囲はUS-ASCIIと同様であり、0x80以上の値をうまく使って、そのほかのコードを収めている。そのため、文字の種類によって1文字を表現するバイト数が増減する。それに対して、UTF-16は16ビット単位で保存する方法で、C#プログラム内で扱われる文字の値に非常に近い。しかし、保存する際には、上位8ビットを先に書く方法と、下位8ビットを先に書く方法があり、選択を間違えると正常に読み込めない恐れがある。
UTF-8を用いると、かなは2バイト、主要な漢字は3バイトで表現されることになる。やや記憶効率が悪いように思えるかもしれないが、現在作られつつあるインターネットの標準規格などではUTF-8が主流となっており、今後、全世界的にUTF-8が主流となることが予想される。特にUTF-8以外を使わなければならない強い理由がなければ、文字はUTF-8で読み書きするようにプログラムを作成するとよいだろう。そのほうが、ソース・コードも少しだけ単純になる。
どうしてもシフトJISなどを読み書きする必要がある場合は、System.IO.StreamReaderクラスなどのインスタンスを作成する際に、上記サンプル・ソースで示したようなSystem.Text.Encodingクラスのインスタンスを指定する必要がある。
『新プログラミング環境 C#がわかる+使える』
本記事は、(株)技術評論社が発行する書籍『新プログラミング環境 C#がわかる+使える』から許可を得て一部分を転載したものです。
【本連載と書籍の関係について 】
この書籍は、本フォーラムで連載した「C#入門」を大幅に加筆修正し、発行されたものです。連載時はベータ版のVS.NETをベースとしていましたが、書籍ではVS.NET製品版を使ってプログラムの検証などが実施されています。技術評論社、および著者である川俣晶氏のご好意により、書籍の内容を本フォーラムの連載記事として掲載させていただけることになりました。
→技術評論社の解説ページ
ご注文はこちらから
Copyright© Digital Advantage Corp. All Rights Reserved.