― .NET Frameworkがサポートする正規表現クラスを徹底活用する ―:基礎解説 スマートな文字列処理のための 正規表現入門(後編)(1/3 ページ)
テキストから特定の部分文字列を抜き出す処理はしばしば必要とされる。正規表現を使ってスマートに記述してみよう。

キャプチャ
前編では、正規表現の基礎的なルールを、実例を交えながら解説していった。後編となる今回は、その応用について解説していくことにしよう。まずは、最も利用価値の高い「キャプチャ」について解説する。
前回の冒頭に述べたように、正規表現の用途は単なる検索だけではない。むしろ、文字列の中から正規表現に一致する部分文字列を抜き出す作業でこそ、正規表現のありがたみが感じられる。それでは、部分文字列の抜き出しと正規表現は、どこで結びつくのだろうか。
■正規表現に一致した文字列
前回示したサンプル・プログラム「regex」では、指定した正規表現パターンに一致する文字列が含まれているか否かを調べることしかしていない。これは次のように、Regex.Matchメソッドの戻り値として得られるMatchオブジェクトのSuccessプロパティを参照することで判断可能だった。
Regex regex = new Regex(<正規表現パターンを含む文字列>);
Match m = regex.Match(<被検索文字列>);
if (m.Success) {
// パターンにマッチする文字列が1つ以上含まれていた場合の処理
}
この検索結果が格納されたMatchオブジェクトには、Successプロパティ以外にも多数のプロパティが納められている。そのうちの1つが、パターンにマッチした文字列が格納されているValueプロパティである。このValueプロパティをうまく使えば、文字列の中から特定の部分を簡単に抜き出すことができる。
例えば、与えられた文字列からIPアドレスと思われる部分を抜き出し、これを表示したいとしよう。これはリスト1に示すプログラム「regexip」のように、Valueプロパティを参照すれば簡単に実現できる。
using System;
using System.Text.RegularExpressions;
class Regexip {
static void Main(string[] args) {
if (args.Length < 1) {
Console.WriteLine("regexip <IP Address>");
} else {
Regex regex = new Regex(@"\d+\.\d+\.\d+\.\d+");
Match m = regex.Match(args[0]);
if (m.Success) {
Console.WriteLine(m.Value);
}
}
}
}
MatchオブジェクトのValueプロパティには、パターンにマッチした文字列が格納されている。
regexip.csのダウンロード
このregexipプログラムは、以下のように、コマンドラインのパラメータとして与えられた文字列からIPアドレスを抜き出し、表示するプログラムである。
C:\>regexip "http://192.168.0.1:8080/"
192.168.0.1
その処理内容はとても簡単だ。文字列から正規表現パターンである、
\d+\.\d+\.\d+\.\d+
を検索し、その結果戻されたValueプロパティを表示しているだけである。前回解説したとおり正規表現で“\d”は、任意の数字に一致するパターンなので、これによりピリオドで区切られた4つの数字を表現できる。各数値が256以上であってもマッチしてしまうので、厳密にはこれでIPアドレスを発見できるとはいいにくいが、その種のチェックは抜き出した後に行った方が簡単だろう。
もし、同じ処理を正規表現を使わずに実現しようとすると、どうなるだろうか。まず文字列の先頭から数字が見付かるまでスキャンする。見付かったら、今度はピリオドが見付かるまで読み進める。このとき、ピリオドよりも先に文字列の末尾に達する可能性も考慮しなければならない。そして、ピリオドが見つかったら、再び数字のチェックを行って……。この繰り返しで、ようやく目的の文字列が取得できる。
今回のサンプルはさほど複雑なパターンではないので、正規表現を使わなくてもそれほどの手間ではないが、それでも正規表現を使ったシンプルさには到底及ばない。それに正規表現ならば、データの書式が変更されても、パターンを修正するだけで対応できるが、コードで実現されていては、たやすい作業にはならないだろう。しかも、書式がどんなに複雑になろうとも、パターンが複雑になるだけで、コードの単純さは保たれるのだから、正規表現で表現できる限りは、もはやコードで文字列解析を行おうとは思わなくなるはずだ。
ところで、いまのリスト1を見ると、正規表現パターン文字列の前に「@」が指定されていることに注目してほしい。もしこの「@」がなければ、このパターン文字列を、
"\\d+\\.\d+\\.\\d+\\.\\d+"
としなければならないのはお分かりだろうか。“¥”を多用することが多い正規表現パターンのリテラル文字列には、文字列の前に「@」を付けてエスケープ処理を無効化する「逐語的文字列リテラル」をお勧めしたい。
ここまで、「部分文字列の抜き出し」と表現してきたが、正規表現では、特定のパターンにマッチした文字列を後で参照できるように保存しておくことを「キャプチャ」と呼ぶ。Regexクラスを使って検索を行うと、パターンに一致した文字列が暗黙的にキャプチャされ、Valueプロパティに格納されるのである。
■すべてのキャプチャ文字列へアクセスする
今度はregexipコマンドを次のように実行してみてほしい。すると、このパラメータにはIPアドレスが2つ含まれているのに、最初に見つかった「192.168.0.0」しか表示されないはずだ。プログラムが1つしか表示しないようになっているのだから当然だ。
regexip "192.168.0.0/24, 172.16.0.0/16"
しかし、このように1回の検索でパターンに一致する文字列が複数個見つかった場合、一致する文字列すべてをキャプチャすることも可能なので、簡単にすべてのIPアドレスを取得できる。ただし、Regex.MatchメソッドはMatchオブジェクトを1つ戻すだけだ。このため、2つ目以降のIPアドレスに対応するMatchオブジェクトへアクセスするには、Match.NextMatchメソッドを使って、キャプチャ・リストをたぐっていかなければならない。
キャプチャされたすべての文字列が表示されるように修正したregexipをリスト2に示す。
using System;
using System.Text.RegularExpressions;
class Regexip {
static void Main(string[] args) {
if (args.Length < 1) {
Console.WriteLine("regexip <IP Address>");
} else {
Regex regex = new Regex(@"\d+\.\d+\.\d+\.\d+");
Match m = regex.Match(args[0]);
while (m.Success) {
Console.WriteLine(m.Value);
m = m.NextMatch();
}
}
}
}
MatchオブジェクトのNextMatchメソッドにより、キャプチャされた2つ目以降のMatchオブジェクトにアクセスすることができる。
regexip2.csのダウンロード
まず以前どおりRegex.Matchメソッドを呼び出すと、先頭のIPアドレスに対応するMatchオブジェクトが戻される。その後NextMatchメソッドを呼び出すと、2つ目のIPアドレスに対応するMatchオブジェクトが戻されるので、2つ目のValueプロパティを表示する。もうこれ以上一致する文字列がなくなれば、Successプロパティの値はfalseになるので、ループは終了する。
■グループ
リスト1のregexipでは、IPアドレス全体を1つの文字列として抜き出した。しかしこれでは、各数値を調べるために、再び4つの数字に分割しなければならず、2度手間になってしまう。そこで、IPアドレス全体をキャプチャすると同時に、4つの数字も個々の文字列としてキャプチャされるようにしてみよう。
パターンに一致した文字列の中で、さらに範囲を限定してキャプチャするには、“( 〜 )”によるグループ化を利用する。このメタ文字は、前回ですでに解説したように“|”の範囲限定や、“*”や“+”といった量指定子で繰り返し適用されるパターンのグループ化に利用されるものだが、まったく意味が異なる「キャプチャ範囲の指定」という用途にも利用されるのである。
グループ化を利用して、4つの数字をキャプチャするregexipをリスト3に示す。
using System;
using System.Text.RegularExpressions;
class Regexip {
static void Main(string[] args) {
if (args.Length < 1) {
Console.WriteLine("regexip <IP Address>");
} else {
Regex regex = new Regex(@"(\d+)\.(\d+)\.(\d+)\.(\d+)");
Match m = regex.Match(args[0]);
if (m.Success) {
for (int i = 1; i < m.Groups.Count; i++) {
Console.WriteLine(
"Groups[" + i + "] = " + m.Groups[i].Value);
}
}
}
}
}
regexip3.csのダウンロード
このリスト3では、まず正規表現パターンが以下のように変更されている。“\d+”がそれぞれ括弧で囲われているのが分かるだろう。
旧)\d+\.\d+\.\d+\.\d+
新)(\d+)\.(\d+)\.(\d+)\.(\d+)
こうしておけば、Valueプロパティから参照できるパターン全体のキャプチャに加えて、括弧で囲われたグループもキャプチャ対象になり、MatchクラスのGroupsプロパティを通してアクセスできるようになる。
Groupsプロパティは、Groupオブジェクトを要素とするGroupCollectionコレクション・クラスのオブジェクトである。パターン内に指定したグループが1つのGroupオブジェクトと1対1に対応し、これがGroupsプロパティに格納される。パターンに指定したグループには、左側から順番に1、2、3とナンバーが振られ、これがGroupsコレクション・プロパティのインデックスとなる。
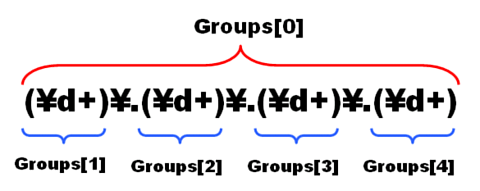
グループとGroupsプロパティ
パターンに指定したグループは、GroupオブジェクトとしてGroupsコレクション・プロパティから取得できる。また、Groups[0]には常にパターン全体に対応するグループが格納される。
なお、Groups[0]には常にパターン全体に対応するグループが格納される。明示的にグループが指定されていなくても、パターン全体が暗黙的にグループとして扱われているということだ。
Groupオブジェクトを取得したら、そのメンバであるValueプロパティへアクセスすれば、そのグループでキャプチャされた文字列を参照できる。
Copyright© Digital Advantage Corp. All Rights Reserved.