OracleとSQL Server、チューニングの違いを知る:RDBMSアーキテクチャの深層(5)(1/2 ページ)
本連載はOracleを使ったデータベースシステムの開発・運用管理にある程度の知識を持つ読者を対象に、Oracle以外の商用RDBMSであるMicrosoft SQL ServerとIBM DB2とのアーキテクチャの違いを明らかにし、マルチベンダに対応できるデータベースシステムの設計・開発・運用ノウハウを紹介していく。(編集局)
はじめに
主な内容
--Page 1--
はじめに
今回扱うRDBMSとその対象内容
SQLの書き方とインデックス
--Page 2--
オプティマイザと統計情報
ディスク・ファイルとメモリの領域管理
今回のまとめ
RDBを使用するシステムにおいては、蓄積されるデータの肥大化に伴って、ほとんどのデータベース管理者の方が、パフォーマンスの問題を経験されていることと思います。今回は、OracleとSQL Serverにおけるパフォーマンス・チューニング方法の違いについて解説していきます。どちらもRDBMSとしての根本的な構造はよく似通ったものがありますが、パフォーマンス・チューニングのアプローチは随分と異なります。
なお、以降では特に断りのない限り、「Oracle」はOracle9i Enterprise Edition、「SQL Server」はSQL Server 2000の各製品に関する説明とします。
今回扱うRDBMSとその対象内容
今回は、すでにOracleまたはSQL Serverでのアプリケーションの開発経験があり、今後どちらかへの移行を検討されているアプリケーション開発者・データベース管理者向けに、パフォーマンス・チューニングのアプローチを解説します(図1)。
RDBMSは、その構造上、蓄積するデータが増えれば増えるほど、注意深く設計しないとパフォーマンスが劣化した際のインパクトが大きくなります。パフォーマンスの劣化を最小限にとどめるためには、データベースの機能をよく理解し、初期のフェイズから、RDBMSのパフォーマンス特性を意識した設計・開発を行う必要があります。
今回はパフォーマンス・チューニングの観点から、以下の3つに絞って比較を行います。
- SQLの書き方とインデックス
- オプティマイザと統計情報
- ディスク・ファイルとメモリの領域管理
SQLの書き方とインデックス
ここではパフォーマンスを意識したSQLの書き方について、OracleとSQL Serverの振る舞いの違いを含めて解説します。
「SELECT * FROM ……」は使わずに、列名・テーブル名を明記する
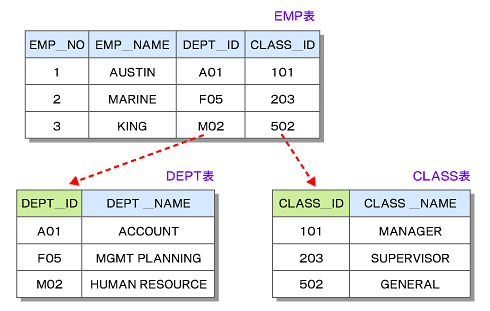
例えば以下のような場合です(図2)。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
SQLで列名を書かずに「*」ですべての列を取得してしまうと、
- テーブルに含まれるすべての列名を取り出し
- FROMで指定した順番で並べる
という処理になります。明示的に列名を指定すれば、2.の処理だけで済みます。明示的に列名を指定することにより、1.の処理が省略され、パフォーマンスが向上することは、双方のRDB製品ともに、同様となります注1 。
注1
この段落は、より正確に記事の意図が伝わるよう、表現の一部を修正しました(2004年10月28日)。
また、SELECT句やWHERE句の中で列名を指定する際にテーブル名を省略した場合、どのテーブルに含まれる列なのか識別できず、複数のテーブルに同じ列名があると(上記の例でDEPT_IDやCLASS_ID)、どちらの製品もエラーとなります。
このように列名やテーブル名を省略するとパフォーマンス上も不利なだけでなく、同じSQLでも製品によって挙動が異なり、列が追加された場合などメンテナンス面からも不利になります。どちらの製品においても、列名とテーブル名は省略せず、明示的に書きましょう。SELECT文だけでなく、INSERT/UPDATE文でも同様です。
FROM/WHERE句に記述する順序を考慮する
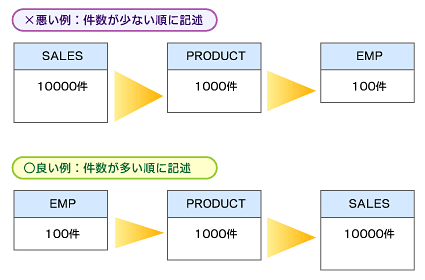
件数が少ないテーブルから順に連結させる
例えばテーブルの件数がEMP:100件、SALES:10000件、PRODUCT:1000件あるとします。Oracleの場合、連結処理はFROM句の最後に書いたテーブルから順に行われるので、レコードが多い順に記述します(図3)。SQL Serverの場合は自動で最適化されます。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
ただしOracleでは、オプティマイザ・モードがコストベースであり、なおかつ統計情報が取得してあれば、自動的に最適な順序で実行されます。製品によらず最適なパフォーマンスを出すためには、FROM句ではレコードが多いテーブル順に記述する習慣をつけましょう。
なるべくインデックスが使われるように記述する
これも双方の製品に共通な事項ですが、せっかくインデックスを作っても、SQLの書き方次第では使用されないことがあり、それではただの領域の無駄遣いです。以下のポイントに気を付けましょう。
- インデックスを付与した列には関数を使わない(図4)
名前が「S」で始まる人を検索する例です。EMP表のEMP_NAME列にインデックスが付与してあるとします。
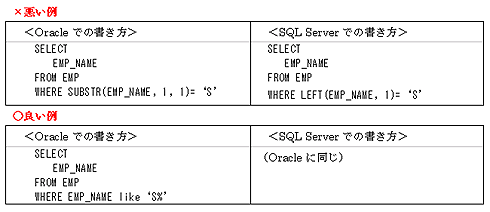
悪い例ではインデックスが使用されない(表のすべてのデータを読み取ってしまう)ばかりか、読み取ったEMP_NAME列から最初の1文字を取り出して、「S」であるか全行比較するという処理を行います。それに対して良い例では、まず「S」で始まる値をインデックスから探し、当てはまる行だけを返します。結果を返すまでの手間がまったく違うことが想像できると思います。同じような理由で、以下も気を付けましょう。
- 文字型の列を連結して検索条件に指定しない
(例:FIRST_NAME||LAST_NAME like 'A%T') - 数値型の列を演算して検索条件に指定しない
(例:PRICE*AMOUNT > 100000)
どうしても必要であれば、計算結果を使ったインデックスも作成できますが、その分だけ更新処理のパフォーマンスが落ちること、ディスク領域を消費することを忘れないでください。
Point
- SQLには列名・テーブル名を常に明記する。
- FROM句ではレコードが多い順にテーブルを記述する。
- WHERE句ではインデックスが使われるように条件を記述する。
Copyright © ITmedia, Inc. All Rights Reserved.