Java言語の特長は、プログラム内で簡単にマルチスレッドを利用できる点にあります。しかしこれは、いわば諸刃の剣です。なぜならマルチスレッドを不用意に使うと、OSに過大な負荷を与えたり、またはスレッド同士の競合によって逆に性能が低下したりといった事態を招くからです。そこでマルチスレッドを使う場合には、OSやJVMが備える各種の計測機能を活用することが肝心です。
マルチスレッド利用の注意点
例えば図1は、HP-UXのOSに付属するツールGlance/gpmを利用して、実行中のJVMプロセス内で動作するすべてのスレッドを表示した例です。
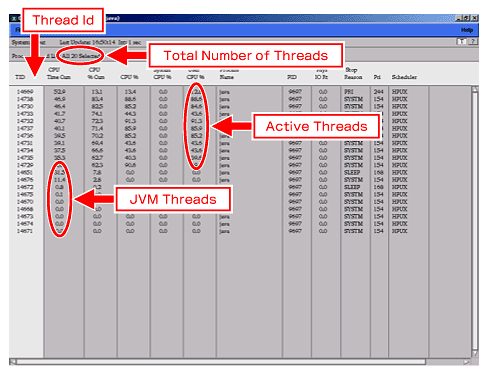
ここでは、JVMが内部的に使用する11のスレッドに加えて、Javaアプリケーションの実行に伴い生成された複数のスレッドが表示されています。こうしたスレッドを多用するJavaアプリケーションのプログラミングでは、スレッドを無制限に生成しないよう配慮する必要があります。また、以下の2つのポイントに気を付けなくてはなりません。
OSの上限数を超えるスレッドを作成しない
大半のJVMでは、OSのスレッドを利用してJavaスレッドを実装しています。よって、Javaスレッドをあまりに大量に生成すると、OSが定める1プロセス当たりのスレッド数の制限を超えてしまいます。こうした場合、Javaプログラムの実行中にOutOfMemoryエラーが発生したり、「スレッドが多過ぎる」と指摘するメッセージが表示されたりします。
もっとも、この問題への対処は比較的簡単です。例えばHP-UXの場合、HPが提供するツール「HPjconfig」(用語解説を参照)を利用することで、カーネル・パラメータ「max_thread_proc」に設定すべき推奨値を算出できます。この値を基に、HP-UXの管理ツール「SAM」を利用して同パラメータの変更を行います。
ロックを長時間保持しない
複数のスレッド間でリソースを共有するアプリケーションでは、あるスレッドがリソースのロックを長い間保持してしまうと、ほかのスレッドの処理が停止してしまいます。この状態をロック競合といいます。ロック競合の起こりやすさは、ロックを獲得しようとするスレッドの数と、獲得の頻度によって決まります。ロック競合が過大に発生すると、スレッドは有意義な作業を進めることができず、ロックの解放待ちに大半の時間を費やしてしまいます。
この2つのうち、Javaのパフォーマンス・チューニングでは、ロック競合の軽減が重要なポイントになります。ロック競合はアプリケーションの設計の不具合に起因して発生するため、設計変更によってその大半は解消できます。そこで以下、このロック競合問題の検出と解決の方法について説明します。
Glanceによる解析
ロック競合問題に対処するための最初の手掛かりは、Glance/gpmのようなOS付属のモニタリング・ツールにより得られます。
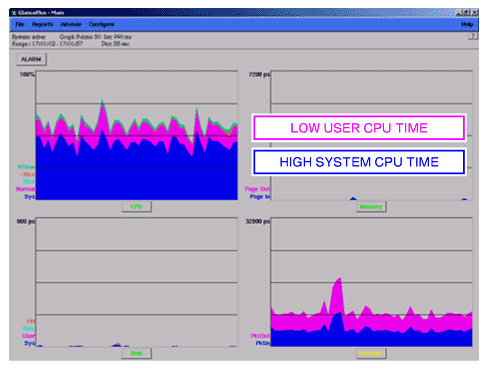
図2は、Javaアプリケーションによるロック競合が発生している状態でGlance/gpmによる計測を行った例です。これを見れば、ほとんどのCPU時間が青色の「System」(OSコード)によって消費され、紫色の「User」(アプリケーション・コード)の割合が低くなっていることが分かります。しかし本来、Javaアプリケーションの動作が正常であれば、CPU時間の大半をUserが占めていなくてはなりません。これは、ロック競合の多発を示す1つの指標となります。
ここで再びGlance/gpmを利用し、JVMプロセスによって呼ばれているシステム・コールを観察してみます。
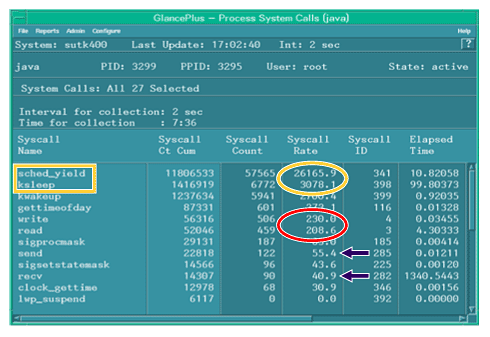
図3 ロック競合を示すシステム・コールの呼び出し回数。囲みの「sched_yield」や「ksleep」などのシステム・コールがかなりの頻度で呼び出されている。一方、矢印で示す「send」と「recv」の呼び出し回数はかなり低いことが分かる
ここでは、「Cumulative system call count」の項目に注目します(図3)。すると、「sched_yield」や「ksleep」などの特定のシステム・コールがかなりの頻度で呼び出されていることが分かります。また、これらに比較して、図3の矢印で示される「send」と「recv」の呼び出し回数はかなり低くなっています。この2つのシステム・コールは、Javaアプリケーションのネットワーク処理をつかさどるため、本来であればもっと高い頻度で呼び出されなくてはなりません。つまり、アプリケーション設計の不具合によるロック競合の影響で、呼び出される回数が低く抑えられているのです。
ちなみに、ネットワーク機能を利用するJavaアプリケーションでは、図3のような状況がしばしば発生します。その原因は、ネットワーク・コネクションのオープンに伴うスレッドの大量生成にあります。つまり、数百や数千といった多数のTCPソケットをオープンすると、同じ数だけスレッドが生成されてしまい、オーバーヘッドが極めて高くなってしまうのです。この問題は、JDK 1.4で導入された非同期I/Oの利用により、スレッド数を減らすことで解決できます。ただし、本連載の範囲を超えるため、その詳細については省略します。
JVMによるスタックトレース出力
Java仮想マシン(JVM)は、Javaのスレッドの挙動を分析するための非常にシンプルで強力な手段を提供しています。その使い方はとても簡単で、動作中のJVMプロセスに対してSIGQUITシグナルを送信する(WindowsであればCtrl+Breakを押す)だけです。これにより、JVMの動作には影響を与えることなく、その時点で存在するすべてのスレッドの詳細情報を記したスタックトレースを取得することができます。
では、HP-UXにおける実際の手順を紹介しましょう。まずは、以下のコマンドを実行し、JVMプロセスのプロセスIDを特定します。
# ps -ef | grep java
続いて、以下のコマンドを実行し、JVMプロセス対してSIGQUITシグナルを送ります(コマンドの実行にはスーパーユーザー権限が必要な場合もあります)。
# kill -SIGQUIT <JVMのプロセスID>
これにより、標準出力に以下のようなスタックトレースが出力されます。場合によっては大量のスタックトレースが表示されるため、そのときはJVMの起動時に標準出力からファイルへのリダイレクトを指定しておけばよいでしょう。
"Worker Thread 17" prio=9 tid=0x1310b70 nid=41 lwp_id=14165 suspended[0x1194d000..0x11948478] at fields.FieldPropertiesLibraryLoader.forClass (FieldPropertiesLibraryLoader.java:67) - waiting to lock <0x3ca45848> (a java.lang.Object) at fields.FieldsServiceImpl.getFpl(FieldsServiceImpl.java:75) at fields.FieldsServiceImpl.getFpl(FieldsServiceImpl.java:64) at base.core.BaseObject.getFpl(BaseObject.java:2930) at base.core.BaseObject.getFieldProperties(BaseObject.java:2661) at core.BaseObject.getFieldProperties(BaseObject.java:2670) at fields.FieldProperties.getFieldsInGroup(FieldProperties.java:1157) at fields.FieldProperties.getFieldsInGroup(FieldProperties.java:1107)
この例では、あるスレッドがスリープ状態にあり、オブジェクトのロックの解放を待ち続けている様子が示されています。こうしたスタックトレースを調べていくことで、ロックを長時間保持しているスレッドを見つけ出し、JVM全体のスローダウンの原因を突き止めることができます。
Copyright © ITmedia, Inc. All Rights Reserved.