前回はBNFでプログラム言語S1sを定義しました。今回は、この定義に従って記述されたプログラムをコンパイルするに当たり、最初に実行する処理である字句解析について解説をします。
「字句解析」とは何ぞや?
前回、プログラミング言語S1sを次のように定義しました。
<program> ::= main '{' <expression> '}'
<expression> ::= <term>{ <opeas> <term> }
<term> ::= <factor>{ <opemd> <factor> }
<factor> ::= <number>|( <expression> )
<number> ::= <digit>{<digit>}
<opeas> ::= + | -
<opemd> ::= * | /
<digit> ::= 0|1|2|3|4|5|6|7|8|9
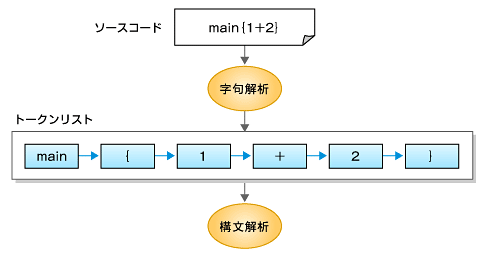
この定義から、S1sのプログラムを構成する文字列が分かります。具体的には、文字列をダブルクオーテーションマーク「"」で囲って表現すると、"main"、"{"、"}"、"("、")"、"+"、"-"、"*"、"/"、"0"、"1"、"2"、"3"、"4"、"5"、"6"、"7"、"8"、"9"、" "となります。最後の文字列は空白です。プログラムをコンパイルするに当たっては、どんな文字列が、どういった順番で記述されているのかが重要です。
ソースコードからトークンのリストを作成
記述されたソースコードが正しいかどうかを判定するに当たっては、そもそもプログラムを構成する文字列はどうなっているかを確認する必要があります。
例えば、"a"や"function"といった文字列はS1sでは使えない文字列ですから、使えない文字列が出てきた時点でプログラムにはエラーが含まれているということが分かります。
コンパイラでは、こういったチェックをしやすくするために、字句解析という処理を最初に行います。字句解析プログラムは、ソースコードを字句のリストと見なして、それからトークンのリスト(トークン列ともいいます)を生成します。
トークンの種類
プログラミング言語における字句とは、自然言語における単語に相当するもので、プログラム内で意味のある文字列の最小単位となるものです。トークンとは、文法上の構成単位で、"123"は数値ですし、"main"は予約語となります。"("や")"のような括弧もトークンです。
トークンのリストを生成する理由
トークンのリストを生成する理由は、文字列の認識処理が簡単になるからです。Javaの文法を例として考えてみましょう。
long length = 256;
このような文字列があるときに、先頭から1文字ずつ"l"、"o"、……と認識するよりも、データ型("long")、変数名("length")、等号記号("=")、数値("256")、セミコロン(";")のトークンで構成されるリストとして扱えた方が分かりやすいはずです。
生成されたトークンのリストは、字句解析の次に実行される構文解析において、文法的に正しいのかチェックされます。簡単な例としては、S1sのソースコードは、最初に"main"という文字列から始まっている必要があります。最初が"makn"になっていたり、"msin"となっていたら、それはエラーだということになります。
Javaで1行ずつ読み込むには?
字句解析をするためには、ソースコードが記述されたファイルを開いてプログラムを1文字ずつ読む必要があります。ですから、字句解析のプログラムをそのように作成してもよいのですが、普通は実行時の効率性を考えて、1行ずつ読み込んでバッファリングをし、そこから1文字ずつ読み込んで処理をします。
Javaで1行ずつ読み込むためには、java.io.BufferedReaderクラスのインスタンスを参照するreaderを使って、次のように記述します。
String s = null;
while ((s = reader.readLine()) != null) {
current++;
if (s.length() == 0) {
continue;
} else {
// トークンリストの作成
(略)
}
}
Tokenクラスを定義する
トークンのプログラミング上での表現については、いろいろな方法がありますが、ここではTokenクラスを用意することにしましょう。数値か予約語かといった情報をフィールドtypeで保持します。typeの値が数値の場合はフィールドnに値を持ち、そのほかの場合はフィールドsに値を持ちます。
また、このトークンが出現する行番号をlineNumberに保持し、トークンがlineNumber行の先頭から何番目から開始するのかのインデックスをindexNumberに持ちます。なお、必要なアクセッサメソッドのみ用意しておきます。実際のプログラムは次のようになります。

public class Token {
private int type;
private String s;
private double n;
private int lineNumber;
private int indexNumber;
public Token(int t, char c) {
type = t; this.s = Character.toString(c);
}
public Token(int t, String s) { type = t; this.s = s; }
public Token(int t, double n) { type = t; this.n = n; }
public int getType() { return type; }
public String getS() { return s; }
public double getN() { return n; }
public void setLineNumber(int n) { lineNumber = n; }
public void setIndexNumber(int n) { indexNumber = n; }
public int getLineNumber() { return lineNumber; }
public int getIndexNumber() { return indexNumber; }
}
TokenUtilクラスを定義する
このTokenクラスを使用するに当たっては、次のようなTokenUtilクラスを用意することにします。数値なのか、予約語なのか、といったタイプについては、このクラスで宣言しておきます。対象記号や予約語を増やす場合には、このクラスに変更が入ることが多いと考えたためですが、このあたりの判断は、処理系の設計方針や好みによって変わってきます。

(略)
public class TokenUtil {
public static final int NUMBER = 1;
public static final int OPE_AS = 2; // + -
public static final int OPE_MD = 3; // * /
public static final int L_PAREN = 4; // (
(略)
public static final int KEYWORD = 8; // 予約語
public static final int IDENTIFIER = 9; // 識別子
private static final String[] symbolsArray = {
"+", "-", "*", "/", "(", ")", "{", "}",
};
(略)
public static final List<String> symbols
= Arrays.asList(symbolsArray);
public static boolean isSymbols(String s) {
return symbols.contains(s);
}
(略)
public static String toPrintFormat(Token t) {
StringBuilder sb = new StringBuilder();
sb.append("\tline :" + t.getLineNumber() + "\n");
(略)
}
return sb.toString();
}
なお、言語の設計では識別子については考えていませんでしたが、字句解析処理ではよく出てくるはずなので、入れてあります。プログラムの抜粋には書いてありませんが、予約語の判定用に、List<String>型のkeywordsを用意してあります。また、それを使って記号判定用のsymbolsと同様な処理で判定するメソッドisKeywordsも実装しています。toPrintFormatメソッドは、Tokenクラスのオブジェクトからディスプレイへ表示する文字列を作成するものです。
Copyright © ITmedia, Inc. All Rights Reserved.