HelloWorld!アプリケーションの実装
対象データの取得はコーディングレス
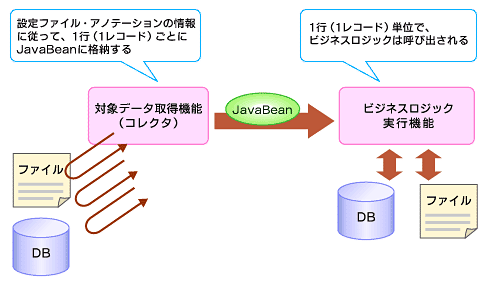
1ページ目の「TERAバッチの特徴」の「TERAバッチのアーキテクチャ」でも述べましたが、TERAバッチでは、入力処理と業務ロジック(出力処理を含む)を別のモジュールにて設定・実装します。入力処理は、「対象データ取得」機能(「コレクタ」と呼ぶこともあります)を利用し、業務ロジックは、「ビジネスロジック実行」機能を利用します。
「対象データ取得」機能には、ファイルやDBから順次データを読み込むための実装があらかじめ用意されています。業務開発者はごく簡単な設定ファイルやアノテーションを記述するだけで、対象リソースからのレコード読み取り、業務入力クラス(JavaBean)への値詰め替え、ビジネスロジックの呼び出しを行うことができます。
ではこれから、業務入力クラスの実装と、「対象データ取得」機能の設定を行っていきます。
繰り返しますがTERAバッチでは、ファイルからJavaBeanへのマッピングを、アノテーションとして記述します。すなわち、「対象データ取得」機能(コレクタ)から、ビジネスロジックに引き渡されるJavaBeanさえ実装すれば、CSVファイルから値を読み込み、内容をビジネスロジックに渡すことができるわけです。
「sources」フォルダ配下に「jp.terasoluna.batch.sample.uc0001.JB0001Data」クラスを以下のとおり作成します。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
簡単に、上記のプログラムを解説します。import文では、利用するアノテーションをインポートしています。クラスに付いているアノテーション「@FileFormat」により、フレームワークは、このクラスが入力フォーマット情報を持つことを認識します。
フィールドに付いているアノテーション「@InputFileColumn」により、CSVのカラム情報とのマッピングを図ります。このアノテーションにより、フレームワークは、CSVファイルの1カラム目をidフィールドへ、2カラム目をnameフィールドへ、3カラム目をmessageフィールドへ格納します。
続いて、ジョブBean定義ファイル「JB0001.xml」に対象データ取得処理の定義を追加します。利用するコレクタをジョブBean定義ファイルの<beans></beans>ネスト内に追加します。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
今回の例では、CSVファイルの読み込みなので、「対象データ取得」処理(コレクタ)として「fileChunkCollector」を、ファイルアクセス用クラスとして「csvFileQueryDAO」を利用しています。固定長ファイルやそのほかのファイル、DBから読み込むときには、ほかのコレクタ、DAO()を利用します。
以上で、入力処理(対象データ取得処理)の実装は完了です。
ビジネスロジックの実装
ビジネスロジッククラスには、前ページで定義したアプリケーションの仕様のとおり、入力データを標準出力に出力するクラスを実装します。「sources」フォルダを配下に、「jp.terasoluna.batch.sample.uc0001.JB0001BLogic」クラスを作成し、下記の実装をします。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
ビジネスロジッククラスは、「BLogic」インターフェイスを実装します。ジェネリック型の第1パラメータには、対象データ取得処理で利用したJavaBeanを指定します。第2パラメータには、ジョブ前処理や後処理に情報を受け渡す際に利用するコンテキストクラスを指定します。今回は、複数の処理間で持ち回る情報がないため、デフォルトのコンテキストクラス「JobContext」を利用します。
リターンコードとして、「NORMAL_CONTINUE」を指定します。リターンコードにはこれ以外に、「NORMAL_END」「ERROR_CONTINUE」「ERROR_END」があります。
最後に、ジョブBean定義ファイル「JB0001.xml」にビジネスロジックの定義を追加します。以下の定義を<beans></beans>ネスト内に追加します。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
実際に動作確認
それでは、実際に動かしてみましょう。Eclipse上でJavaアプリケーションとして起動します。Eclipseの[実行]ダイアログを開き、[メイン]タブの[プロジェクト]に「terasoluna-batch-blank」を指定、[メイン・クラス]にTERAバッチが提供する「jp.terasoluna.fw.batch.springsupport.init.JobStarter」を指定します。
そして、[引数]タブの[プログラムの引数]において、第1引数にジョブID(JB0001)、第2引数にジョブBean定義ファイルのパス(sample/UC0001/JB0001.xml)を入力して、実行します。以下のようなログが出力されれば、成功です。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
次回はDBを利用したバッチアプリケーション
今回は、CSVファイルから1行ずつデータを読み込み、ビジネスロジックを呼び出すアプリケーションを実装しました。TERAバッチの特徴とアプリケーション作成時に必要な作業を理解していただけましたか?
次回以降は、DBを利用したバッチアプリケーションを作成していきます。
今回作成したアプリケーションのファイルは、SourceForgeからダウンロードできます。こちらのページからダウンロードしてください。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
- バッチ処理でデータベースアクセスを効率化する
Java TIPS - 20世紀のJavaの歴史と21世紀への5つの提案
[コラム]米持幸久のJava Issue(2) - 開発存続の危機で分かったSEに必要なスキル
開発現場で学べること(6) - Webと企業システムをつなぐアーキテクチャ
[連載]Webと企業システム結ぶ実践的アーキテクチャ(1)