Javaバッチフレームワークで多重実行、非同期実行:Javaバッチ処理は本当に業務で“使える”の?(4)(1/3 ページ)
最終回は、TERAバッチの特徴的な機能の紹介
連載第3回の「Eclipseで作る! DBを使った実践的なJavaバッチ」では、オープンソースのJavaバッチフレームワークの1つである「TERASOLUNA Batch Framework for Java」(以下、TERAバッチ)を利用した本格的なバッチアプリケーションの実装を通して、TERAバッチの実践的な利用方法を学びました。
編集部注:「Batch Framework for Java」を含むTERASOLUNAフレームワーク全体について詳しく知りたい読者は、特集「Java、.NET、Ajax開発の“銀の弾丸”オープンソース?」をご覧ください。
今回はTERAバッチが提供する特徴的な機能である、「多重実行」と「非同期実行」の2つの機能を実際に利用することで、TERAバッチのさまざまな利用方法を学んでいきましょう。
バッチの分散処理? 「多重実行」とは?
連載第2回「OSSのJavaバッチフレームワークでHello World!」でも少し触れましたが、バッチ処理では、大量件数データの処理を限られた時間で処理する必要があるときに、ジョブの多重化を行うことが一般的です。「ジョブの多重化」とは、あらかじめジョブスケジューラなどに同じジョブを複数個登録し、それらを同時に実行することでバッチ処理全体のスループットを向上させる手法のことを指します。
もう少し具体的に説明すると、例えば全国各地にある銀行の支店の残高更新処理を行う際に、「残高更新処理」ジョブを夜間に実行するとしましょう。これを1時間以内に終わらせないと後続処理に影響が出てしまうけれど、単純に「残高更新処理」ジョブを実行すると2時間かかってしまう。そこで、「残高更新処理(東京都)」「残高更新処理(大阪府)」といった形で都道府県ごとに処理を行うジョブを作成して、並列に実行することで処理時間の短縮を行おうというものです。
この多重実行をジョブスケジューラで行う際に問題になるのは、主にジョブの管理面で、ジョブスケジューラに登録するジョブ数が膨れ上がって管理が煩雑になったり、大規模システムなどではジョブスケジューラへのジョブ登録の上限を超えてしまったりすることもあります。
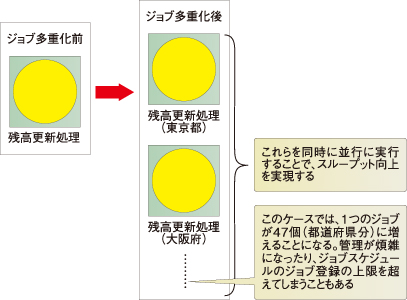 図1 全国各地にある銀行の支店の残高更新処理を行う場合
図1 全国各地にある銀行の支店の残高更新処理を行う場合そこで、TERAバッチでは、多重実行をフレームワークでサポートすることで、これらの問題に対処できるようにしています。
どうやって「多重実行」するの?
実際にアプリケーションを作成する前に、前回までに説明したTERAバッチのアーキテクチャについて、もう一歩理解を深めていきたいと思います。
TERAバッチには、「コレクタ」(対象データ取得処理)と「ワーカ」(業務処理)という役がいるという説明をしましたが、実はもう1つ「マネージャ」という、その名のとおりコレクタとワーカを制御する役が存在します。この構造がTERAバッチの基本的な構造となります。
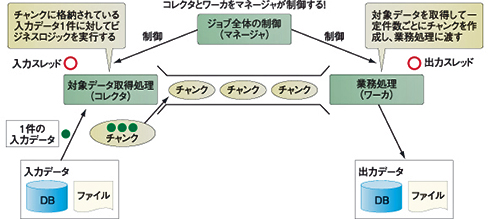 図2 TERAバッチの基本的な構造
図2 TERAバッチの基本的な構造ここで、「基本的な構造」といったのは、構造を変えることができるということです。以下のようにフレームワークの構造を変更することでジョブの多重化をフレームワークで実現可能となります。

このように、処理対象データを分割するキー(先ほどの例でいうところの「東京都」「大阪府」に当たる)を取得するコレクタを用意し、その分割キーごとにジョブを実行します。分割キーごとに実行されるジョブを「子ジョブ」または「分割ジョブ」と呼び、ジョブ全体を制御しているジョブを「親ジョブ」と呼びます。この構造の変更は、TERAバッチが提供するひな型ファイルを切り替えることで簡単にできます。ぜひ、この構造を踏まえて以降のアプリケーションの作成を行っていきましょう。
Javaバッチアプリケーション作成の準備
では、多重実行を行うバッチアプリケーション作成の準備をしていきましょう。今回は前回のアプリケーションに近い仕様のサンプルに手を加えていき、多重実行を実現させたいと思います。
なお、TERAバッチで実装しなければならないソースコードや開発環境の構築の際に必要となるEclipseやJDKのセットアップについては、連載第2回を参考にしてください。この説明の中では、Windows上での開発を想定しています。
今回作成するJavaバッチアプリケーションの仕様
今回利用する多重化バッチアプリケーションの仕様は以下のとおりとします。前回のアプリケーションの仕様と異なる点は、入金テーブルの仕様のみとなります。
1.入金テーブルから処理対象となるデータを読み込み、ビジネスロジックに渡す
| 表1 入金テーブルの形式 | |||||||||||||||
|
2.渡されてきた入力データの顧客IDにひも付く残高を、残高テーブルを基に算出し更新する。その際に、残高テーブルに入力データの顧客IDがない場合は新規に追加する
| 表2 残高テーブルの形式 | |||||||||
|
3.残高テーブルに対して更新した件数、新規に追加した件数をそれぞれコンソールに出力する
多重化前の処理フロー、処理前後でのテーブルの変化のイメージ、コンソール出力のイメージは前回を参考にしてください。上記で示した仕様に基づいた多重化前のサンプルは用意しましたので、次からの手順によって多重実行を実現するアプリケーションを作っていきましょう。
EclipseにJavaバッチのプロジェクトを準備
今回のアプリケーションを開発する環境を準備します。SourceForgeのサイトから、今回のアプリケーション開発の基となるサンプルプロジェクトをダウンロードします。こちらから、ZIPファイルをダウンロードし、Eclipseの「Workspace」フォルダ配下に展開してください。このプロジェクトは、通常のブランクプロジェクトに今回利用するDBを追加したものです。
プロジェクトのインポート
ブランクプロジェクトを、Eclipseにインポートします。Eclipseメニューの[ファイル]→[インポート]から、[インポート]ウィザードを開き、[一般]→[既存プロジェクトをワークスペースへ]から、[ルートディレクトリの選択]を選びます。その後、[参照]ダイアログから、先ほど展開したブランクプロジェクトがあるWorkspaceフォルダを選択してください。[プロジェクト]欄に「terasoluna-batch-blank-foratmarkit04」があることを確認し、[終了]を押下します。
接続するDBの起動・確認
次に、接続するDB(純正JavaのDBであるHSQLDBを使う)の起動・確認をします。プロジェクトに入っている「hsqldb.zip」をデスクトップなど任意のフォルダにコピー・展開し、「(任意のフォルダ)\hsqldb\terasoluna\startDBManager.bat」を実行してDBを起動します。続いて、正しく起動しているか確認します。「(任意のディレクトリ)\hsqldb\terasoluna\startDBManager.bat」を実行します。[HSQL Database Manager](以下、DBManager)が起動し、[connect]画面が表示されるので、以下のように入力します。
- Type:HSQL Database Engine Server
- Driver:org.hsqldb.jdbcDriver
- URL:jdbc:hsqldb:hsql://localhost/terasoluna
- User:sa
- Password:(なし)
DBの接続後、画面左のテーブル一覧に以下があること、入金テーブル・残高テーブルの内容を確認します。
- テーブル:「NYUKINTABLE」 カラム:"ID""SITEN""KOKYAKUID""NYUKIN"
- テーブル:「ZANDAKATABLE」 カラム:"KOKYAKUID""ZANDAKA"
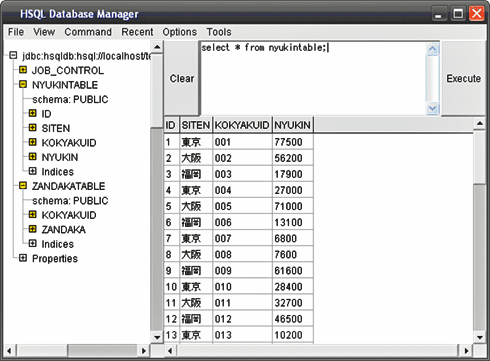 図4 データの確認
図4 データの確認DBは起動したままにしておいてください。以上で準備完了です。
次ページ以降では引き続き、TERAバッチでジョブの多重化をしていき、TERAバッチのもう1つの特徴的な機能である「非同期実行」について解説します。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。