Internet Explorerよりも速くソートできたよ:コーディングに役立つ! アルゴリズムの基本(5)(2/4 ページ)
プログラマたるものアルゴリズムとデータ構造は知っていて当然の知識です。しかし、教科書的な知識しか知らなくて、実践的なプログラミングに役立てることができるでしょうか(編集部)
マージソートの実装
それでは実装してみましょう。一見複雑ですが再帰で実装すると意外にシンプルなコードになります。
第4回で作成したプログラムの末尾(30行目)の「末尾6」とコメントをした部分の次の行に以下のコードを追加してください。
<hr/>
マージソート<br/>
<span id="merge"></span>
<script type="text/javascript">
Array.prototype.mergeSort = function(compare, arg_array) {
arg_array = (arg_array === undefined) ? this : arg_array;
if (arg_array.length <= 1) { return arg_array; }
var middle = Math.floor(arg_array.length / 2);
var left = this.mergeSort(compare, arg_array.slice(0,middle));
var right = this.mergeSort(compare, arg_array.slice(middle));
//merge
var l = 0;
var r = 0;
for (var i = 0; i < arg_array.length; i++) {
if ((!(r < right.length)) ||
((l < left.length) && (compare(left[l],right[r]) < 0))) {
arg_array[i] = left[l];
l++;
} else {
arg_array[i] = right[r];
r++;
}
}
this.display(arg_array);
return arg_array;
}
var merge = arrayForDisplay.clone();
merge.view_id = "merge";
merge.display();
merge.mergeSort(compare);
var mergeForTime = arrayForTime.clone();
func = function() { mergeForTime.mergeSort(compare); }
time(func, "マージソート", "merge");
</script><!-- 末尾7 -->
プログラムを解説します。
5行目
マージソートのメソッドを定義しています。引数arg_arrayに配列を指定できるようにしているのは再帰で呼び出しするときのためです。
6行目
引数のarg_arrayがなかったら自分自身をマージソートの対象にするようにしています。マージソートを最初に呼び出したときはarg_arrayを指定しないためです。
7行目
配列の要素数が1個だけだったらそのまま値を返します。これは配列が分割されて要素数が1個だけになった場合です。
9〜12行目
配列を分割します。半分ずつに分け、leftとrightとします。leftとrightは再帰的にマージソートが呼び出され、最終的にはソートされた状態の部分配列がセットされます。
15〜26行目
分割したそれぞれの部分配列をマージします。lはleftの配列の中で着目するインデックス、rはrightの配列の中で着目するインデックスです。
18、19行目
ifでl、rとleft.length、right.lengthを比較しているのは、lとrが一番右まで行ったときに配列の長さ+1になる場合があるためです。
それでは実行してみましょう。いつもどおりソースコードをhtmlファイルとして保存しWebブラウザで開きます。セキュリティの警告が出た場合は実行を許可するようにしてください。
結果はクイックソートやシェルソートと同等だったと思います。惜しいところまでいきましたが、まだ及びません。
ヒープソート―完全二分木の活用
マージソートはやや複雑でしたがヒープソートはより複雑です。ヒープソートはヒープというデータ構造を作成することによりソートするアルゴリズムです。まずヒープというデータ構造について説明したいと思います。
ヒープは完全二分木の一種です(完全二分木については第2回「データ構造の選択次第で天国と地獄の差」を参照してください)。ただし、「親ノードは子ノードよりも大きい」という特徴を持ちます。つまり、最上位の親ノードであるルートノードは最大の値を持つことになります。
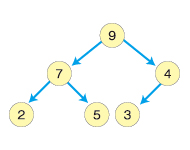
親ノードが子ノードよりも大きい場合は最大ヒープといいます。親ノードが子ノードよりも小さい場合のヒープもあります。この場合は最小ヒープと呼びます。
なお、ヒープというとプログラムで使用するメモリ領域のことを指す場合があります。データ構造のヒープは同じ言葉ですが内容はまったく別で関係はありません。
ヒープの再構築
ヒープをゼロから構築する方法の前に、ヒープの再構築について説明します。できあがっている状態のヒープがあるとします。そのヒープのうちの1つの要素が入れ替わると、順序関係が壊れてしまいヒープではなくなります。再度ヒープの状態にするには次のような再構築を実施します。
例えば上のヒープのルートノードが9から6に変わったとします。
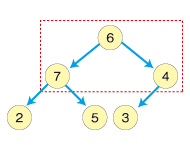
まず、入れ替えたノードと左右の子ノードを比較します。左の子ノードが最も大きいので6と7を交換します。
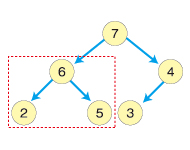
今度は入れ替えたノードに注目します。同じように左右の子ノードと比較します。6が最も大きいので入れ替えの必要はありません。これで再構築は完了し、ヒープが出来上がりました。
もし、入れ替えたノードが一番大きくなかったら一番大きいノードと交換します。そして同じように子ノードに下って比較を行っていきます。子ノードがなくなったらそこで終了です。
ヒープをゼロから構築する
では、ヒープをゼロから構築する方法を考えてみましょう。
まず、ヒープになっていない完全二分木があったとします。この木のすべてのノードに順に着目して先に説明したヒープの再構築を行えば全体がヒープになるはずです。
注意しなければならないのは下位のノードから順に再構築を行う必要があることです。再構築をする際には着目しているノード以下がヒープになっていなければならないからです。
また、下位のノードといっても子ノードがない末端の葉ノードは再構築処理をしても何も変わらないので再構築を行う必要がありません。
Copyright © ITmedia, Inc. All Rights Reserved.