Œ¸‚葱‚¯‚é—ک—p‰آ”\ƒپƒ‚ƒٹپcپc‚»‚µ‚ؤ‚آ‚¢‚ةƒٹƒuپ[ƒgپIپFLinuxƒgƒ‰ƒuƒ‹ƒVƒ…پ[ƒeƒBƒ“ƒO’T’م’cپ@”شٹO•زپi2پjپi1/3 ƒyپ[ƒWپj
پ@NTTƒOƒ‹پ[ƒv‚جٹeژذ‚إ–آ‚炵‚½‰´‚½‚؟Linuxƒgƒ‰ƒuƒ‹ƒVƒ…پ[ƒeƒBƒ“ƒO’T’م’c‚حپAٹeژذ‚إ”|‚ء‚½OSSٹضکA‹Zڈp‚ًژè‚ةپANTT OSSƒZƒ“ƒ^‚ةڈW‚ك‚ç‚ꂽپB•پ’i‚حٹî–{“I‚ةNTTƒOƒ‹پ[ƒv‚ج‚ف‚ً‘ٹژè‚ةٹˆ“®‚µ‚ؤ‚¢‚é‚ھپA‚»‚ꂾ‚¯‚إڈI‚ي‚鉴‚½‚؟‚¶‚ل‚ ‚ب‚¢پBپ@
ƒ\پ[ƒXƒRپ[ƒh‚³‚¦‚ ‚ê‚خ‚ا‚ٌ‚بƒgƒ‰ƒuƒ‹‚إ‚à‰ًŒˆ‚·‚é–½’m‚炸پA•s‰آ”\‚ً‰آ”\‚ة‚µپA‘½‚‚جƒoƒO‚ً•²چس‚·‚éپA‰´‚½‚؟Linuxƒgƒ‰ƒuƒ‹ƒVƒ…پ[ƒeƒBƒ“ƒO’T’م’cپIپ@ڈ•‚¯‚ًژط‚肽‚¢‚ئ‚«‚حپA‚¢‚آ‚إ‚à‚¢‚ء‚ؤ‚‚êپI
OSپFچ‚“c“Nگ¶
‰´‚حƒٹپ[ƒ_پ[پAچ‚“c“Nگ¶پBLinux‚ج’BگlپB‰´‚ج‚و‚¤‚ةƒ\پ[ƒXƒRپ[ƒhƒŒƒxƒ‹‚إOS‚ً—‰ً‚µ‚ؤ‚¢‚éگlٹش‚إ‚ب‚¯‚ê‚خپA•SگيکB–پ‚جLinuxƒgƒ‰ƒuƒ‹ƒVƒ…پ[ƒeƒBƒ“ƒO’T’م’c‚جƒٹپ[ƒ_پ[‚ح–±‚ـ‚ç‚ٌپB
WebپF•ںژR‹`گm
‰´‚حپA•ںژR‹`گmپBWeb‹Zڈp‚ج’Bگl‚³پBApache‚ج‚و‚¤‚بWebƒTپ[ƒo‚©‚çTomcatپAJBoss‚ف‚½‚¢‚بJavaپAƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“‹Zڈp‚ـ‚إپA‰½‚إ‚à–â‘è‚ً‰ًŒˆ‚µ‚ؤ‚ف‚¹‚é‚؛پB
DBMSپF‰؛ٹ_“O
‰؛ٹ_“OپBPostgreSQL‚ج’Bگl‚¾پBٹJ”‚©‚çƒTƒ|پ[ƒg‚ـ‚إ‰½‚إ‚à‚â‚ء‚ؤ‚ف‚¹‚ç‚ںپB‚إ‚à–^ڈ¤—pDBMS‚¾‚¯‚حٹ¨•ظ‚بپB
HAپF“c’† گ’چK
‚و‚§پI ‚¨‘ز‚؟‚ا‚¤پB‰´‚³‚ـ‚±‚»HAƒGƒLƒXƒpپ[ƒgپBHeartbeat‚ًژg‚ء‚ؤƒNƒ‰ƒXƒ^‚ًچ\گ¬‚·‚éکr‚ح“V‰؛ˆê•iپI HA‚ھچD‚«‚ب‚ٌ‚ؤٹïگlپH •دگlپH ‚¾‚©‚牽پH HaHaHaHa!!
پ@”شٹO•ز‘و1‰ٌ‚إ‚حپAƒپƒ‚ƒٹژg—p—ت‚ة‚آ‚¢‚ؤ‚جٹî–{“I‚بچl‚¦•û‚ًگà–¾‚µ‚½پBچ،‰ٌ‚ح‰½‚©‚ئŒë‰ً‚ج‘½‚¢پA‰¼‘zƒپƒ‚ƒٹ‚ئ•¨—ƒپƒ‚ƒٹ‚جˆل‚¢‚ً’†گS‚ةگà–¾‚·‚é‚؛پI
ٹضکA‹Lژ–پF
کAچع‹Lژ– پuLinuxƒgƒ‰ƒuƒ‹ƒVƒ…پ[ƒeƒBƒ“ƒO’T’م’cپv
http://www.atmarkit.co.jp/flinux/index/indexfiles/tsindex.html
‚»‚ê‚إ‚àŒ¸‚葱‚¯‚éژg—p‰آ”\ƒپƒ‚ƒٹ
پ@‘و1‰ٌپuŒ¸‚葱‚¯‚éƒپƒ‚ƒٹژc—تپI ‰ت‚½‚µ‚ؤ‚»‚جŒ´ˆِ‚ح!?پv‚إڈذ‰î‚µ‚½‚ئ‚¨‚èپAƒپƒ‚ƒٹ‚ةٹض‚·‚éƒgƒ‰ƒuƒ‹‚ة‚آ‚¢‚ؤŒع‹q‚ة‰ٌ“ڑ‚ً•ش‚µ‚ؤ‚©‚çگ”“ْپcپcپB“¯‚¶ƒvƒچƒWƒFƒNƒg‚©‚çپA‚³‚ç‚ة’ا‰ء‚جژ؟–â‚ھ—ˆ‚ـ‚µ‚½پB
پ@پu‚¢‚ي‚ꂽ‚ئ‚¨‚è/proc/meminfo‚ًٹm”F‚µ‚ؤ‚ف‚½‚ھپAMemFreeپ{Inactive‚àŒ¸‚葱‚¯‚ؤ‚¨‚èپAswap‚àڈo‘±‚¯‚ؤ‚¢‚éپB‚±‚ê‚ح‚ا‚¤‚¢‚¤‚±‚ئ‚©پHپv
پ@MemFree‚ئInactive‚ھŒ¸‚é‚ئ‚¢‚¤‚±‚ئ‚حپAƒVƒXƒeƒ€‚إ—ک—p‰آ”\‚ب•¨—ƒپƒ‚ƒٹژg—p—ت‚ھŒ¸‚ء‚ؤ‚«‚ؤ‚¢‚邱‚ئ‚ًˆس–،‚µ‚ـ‚·پB‚±‚ê‚ھگiچs‚·‚é‚ئپA‘ه•د‚ب‚±‚ئ‚ة‚ب‚é‚ج‚إ‚ح!?پ@•s‰¸‚ب‹َ‹C‚ًٹ´‚¶ژو‚ء‚½‚ي‚ê‚ي‚ê‚حپAگV‚½‚ةژو“¾‚µ‚½/proc/meminfo‚جƒچƒO‚ًٹî‚ة’²چ¸‚ًژn‚ك‚½‚ج‚إ‚·‚ھپA‚»‚±‚ة’ا‚¢‘إ‚؟‚ًٹ|‚¯‚é‚و‚¤‚ة1–{‚ج“dکb‚ھ‚©‚©‚ء‚ؤ‚«‚½‚ج‚إ‚·پI
پ@پuƒVƒXƒeƒ€‚ج—ک—p‰آ”\‚بƒپƒ‚ƒٹ‚ھ‚ب‚‚ب‚ء‚ؤƒٹƒuپ[ƒg‚µ‚½پBŒ´ˆِ‚ً‹†–¾‚µ‚ؤ‚ظ‚µ‚¢پv
پ@–â‘è‚حگV‚½‚بپA‚و‚èگ[چڈ‚بƒtƒFپ[ƒY‚ةˆع‚ء‚½‚و‚¤‚إ‚·پB‚±‚ê‚ح‚à‚¤ƒچƒO‚ًŒ©‚ؤ‚¢‚邾‚¯‚إ‚ح‚ç‚؟‚ھ–¾‚©‚ب‚¢‚ج‚إپA‚ي‚ê‚ي‚ê‚حŒ»’n‚ة•‹‚«پAژ–ڈî‚ً•·‚‚±‚ئ‚ة‚µ‚ـ‚µ‚½پB
‚ـ‚¸‚حژ–ڈî’®ژوپB”ئگl‚ح’N‚¾!?
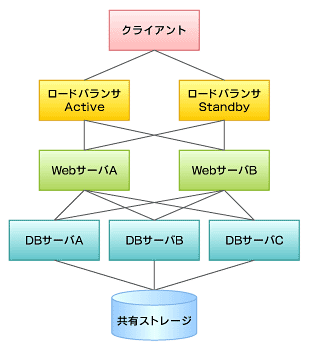
پ@Œ»’n‚ة“’…‚µ‚½‚ي‚ê‚ي‚ê‚حپA‚ـ‚¸ƒVƒXƒeƒ€چ\گ¬‚ة‚آ‚¢‚ؤƒqƒAƒٹƒ“ƒO‚ًچs‚¢‚ـ‚µ‚½پB‚±‚±‚إ•·‚«ڈo‚·‚±‚ئ‚ھ‚إ‚«‚½ڈî•ٌ‚حگ}1پA•\1پA•\2‚ج‚و‚¤‚ب‚à‚ج‚إ‚µ‚½پB
| “à—e | |
|---|---|
| WebƒTپ[ƒo | Apache |
| DBƒTپ[ƒo | Oracle 10g R2 |
| OS | Red Hat Enterprise Linux 4 AS Update2 |
| •\1پ@ژه‚بƒ\ƒtƒgƒEƒFƒAچ\گ¬ | |
| ƒTپ[ƒo | CPU | ƒپƒ‚ƒٹ |
|---|---|---|
| WebƒTپ[ƒo | Dual Core Xeonپ~2 | 16GB |
| DBƒTپ[ƒo | Dual Core Xeonپ~2 | 48GB |
| •\2پ@ƒnپ[ƒhƒEƒFƒAچ\گ¬ | ||
پ@‚±‚ج‚¤‚؟ƒٹƒuپ[ƒg‚µ‚½‚ج‚حپuDBƒTپ[ƒoCپvپB‚و‚‚و‚•·‚¢‚ؤ‚ف‚é‚ئپA‚±‚±گ”ƒJŒژ‚ج‚¤‚؟‚ة‰½“x‚©پA1ƒJŒژ‚â2ƒJŒژ‚ئ‚¢‚¤ٹشٹu‚إƒٹƒuپ[ƒg‚ھ”گ¶‚µ‚ؤ‚¢‚é‚ئ‚ج‚±‚ئپB‚±‚ê‚حˆê‘هژ–‚إ‚·پB
پ@‚¾‚¢‚½‚¢‚جڈî•ٌ‚ح•·‚«ڈo‚¹‚½‚ج‚إپA•¨ڈط‚إ‚ ‚éƒچƒOƒtƒ@ƒCƒ‹‚ً—p‚¢‚½گط‚è•ھ‚¯‚ة“ü‚è‚ـ‚·پBƒچƒO‚ة‚ح‚ظ‚ئ‚ٌ‚ا‰½‚àژc‚ء‚ؤ‚¢‚ب‚©‚ء‚½‚ج‚إ‚·‚ھپAHPگ»‚جƒTپ[ƒoگ»•iپuPSPپvپi’چ1پj‚ً“±“ü‚·‚邱‚ئ‚إ—ک—p‚إ‚«‚éپuhplogپv‚ة‚و‚èپAˆب‰؛‚ج‚و‚¤‚بƒچƒO‚ًژو“¾‚إ‚«‚ـ‚µ‚½پB
ASR Detected by System ROM
پ@‚±‚جƒچƒO‚جˆس–،‚حپAHPگ»‚جƒTپ[ƒoگ»•i‚ة“‹چع‚³‚ê‚ؤ‚¢‚éڈلٹQŒں’m‹@”\پuASRپvپi’چ2پj‚ھ‹گ§ƒٹƒuپ[ƒg‚ًژہژ{‚µ‚½‚±‚ئ‚ًژ¦‚µ‚ؤ‚¢‚ـ‚·پB
پ@ASR‚حOS‚ة‘خ‚µ‚ؤ’èٹْ“I‚بƒVƒXƒeƒ€ƒ`ƒFƒbƒN‚ًچs‚ء‚ؤ‚¨‚èپAOS‚ھگ”•ھٹش‰“ڑ‚ً•ش‚³‚ب‚¢‚ئƒnƒ“ƒOƒAƒbƒv‚µ‚½‚ئ”»’f‚µپAƒnپ[ƒhƒEƒFƒAƒŒƒxƒ‹‚إ‹گ§“I‚ةƒٹƒuپ[ƒg‚ًٹ|‚¯‚ـ‚·پB‚ا‚¤‚â‚çƒٹƒuپ[ƒgژ‚ة‚حپAOS‚ھƒnƒ“ƒOƒAƒbƒv‚µ‚ؤ‚¨‚èپAƒnپ[ƒhƒEƒFƒA‚©‚ç‚جڈَ‘شŒں’m‚ًژَ‚¯•t‚¯‚ب‚¢ڈَ‹µ‚ة‚ب‚ء‚ؤ‚¢‚½‚و‚¤‚إ‚·پB
پ@‚µ‚©‚µپA‚½‚ء‚½‚±‚ꂾ‚¯‚جڈî•ٌ‚©‚çƒٹƒuپ[ƒgŒ´ˆِ‚ً’T‚é‚ج‚ح”ٌڈي‚ةچ¢“ï‚إ‚·پBˆêŒû‚ةOS‚جƒnƒ“ƒOƒAƒbƒv‚ئ‚¢‚ء‚ؤ‚à‚¢‚ë‚¢‚ë‚ ‚è‚ـ‚·پBƒnپ[ƒhƒEƒFƒA‚ة‘خ‚µ‚ؤپA‰½‚ھŒ´ˆِ‚إƒnƒ“ƒOƒAƒbƒv‚µ‚½‚ج‚©‚ً‰ًگح‚µپAƒچƒOڈo—ح‚µ‚ë‚ئ‚¢‚¤‚ج‚حچ“‚بکb‚إ‚µ‚ه‚¤پB
پ@ژc‚è‚جŒ´ˆِ‰ًگح‚حƒ\ƒtƒgƒEƒFƒA‚إ‰½‚ئ‚©‚·‚邵‚©‚ب‚¢‚ج‚إ‚·‚ھپAƒVƒٹƒAƒ‹ƒRƒ“ƒ\پ[ƒ‹‚âƒNƒ‰ƒbƒVƒ…ƒ_ƒ“ƒv‚جگف’è‚ب‚ا‚ً‚µ‚ب‚¢Œہ‚èپAپu‚ب‚؛ƒnƒ“ƒOƒAƒbƒv‚µ‚½‚©پv‚ح‰پX‚ة‚µ‚ؤƒچƒO‚ةژc‚è‚ـ‚¹‚ٌپB‚»‚ê‚حپA“–‚½‚è‘O‚إ‚·‚ھپuƒچƒO‚ً‹Lک^‚·‚éOS‚»‚ج‚à‚ج‚ھƒnƒ“ƒOƒAƒbƒv‚µ‚ؤ‚¢‚é‚©‚çپv‚إ‚·پB‚ـ‚½پAƒnپ[ƒhƒEƒFƒA‚ھŒجڈل‚µ‚ؤŒëŒں’m‚µ‚ؤ‚¢‚é‰آ”\گ«‚ـ‚إچl—¶‚ة“ü‚ê‚é‚ئپAƒnپ[ƒhƒEƒFƒAڈلٹQƒچƒO‚ج‚ف‚©‚猴ˆِ‚ً’f’è‚·‚é‚ج‚ح”ٌڈي‚ةچ¢“ï‚إ‚·پB
پ@ژc”O‚ب‚ھ‚畨ڈط‚ج‚ف‚إ‚حŒ´ˆِ‚ً“ء’è‚إ‚«‚ب‚©‚ء‚½‚ج‚إپAڈَ‹µڈط‹’‚ًڈW‚كپAƒٹƒuپ[ƒg‚جŒ´ˆِ‚ً—قگ„‚µ‚ؤ‚ف‚ـ‚µ‚ه‚¤پBڈَ‹µڈط‹’‚ئ‚ح‚·‚ب‚ي‚؟پu‚¨‹q‚³‚ـ‚جڈطŒ¾‚âƒٹƒuپ[ƒg‚ة‚ح’¼Œ‹‚µ‚ب‚¢ƒچƒOپv‚إ‚·پBچ،‰ٌ‚حپAڈd—v‚بڈطŒ¾‚ھ“¾‚ç‚ê‚ؤ‚¢‚ـ‚·پB‚·‚ب‚ي‚؟پA
پu‚¢‚ي‚ꂽ‚ئ‚¨‚è/proc/meminfo‚ًٹm”F‚µ‚ؤ‚ف‚½‚ھپAMemFreeپ{Inactive‚àŒ¸‚葱‚¯‚ؤ‚¨‚èپAswap‚àڈo‘±‚¯‚ؤ‚¢‚éپB‚±‚ê‚ح‚ا‚¤‚¢‚¤‚±‚ئ‚©پv
‚ئ‚¢‚¤‚â‚آ‚إ‚·پB‚±‚±‚إƒٹƒuپ[ƒg‚µ‚½ƒTپ[ƒoپiDBƒTپ[ƒoپj‚ج•¨—ƒپƒ‚ƒٹ“‹چع—ت‚ًژv‚¢ڈo‚µ‚ؤ‚ف‚ـ‚µ‚ه‚¤پi•\2پjپB‚»‚¤پA48Gbytes‚à‚ ‚é‚ج‚إ‚·پB‚±‚ꂾ‚¯‚ ‚é‚ج‚ةswapپiƒXƒڈƒbƒvپAŒمڈqپj‚ھڈo‘±‚¯‚é‚ئ‚¢‚¤‚ج‚حپA‚¢‚©‚ة‚à‚¨‚©‚µ‚¢کb‚إ‚·پB‚µ‚©‚àپAƒٹƒuپ[ƒgٹشٹu‚ح1〜2ƒJŒژ‚ئ‚¢‚¤‚±‚ئ‚ب‚ج‚إپAƒپƒ‚ƒٹ“‹چع—ت‚جگفŒv‚ةژ¸”s‚µ‚½‚ئ‚àژv‚¦‚ـ‚¹‚ٌپB‚â‚ح‚èپAƒپƒ‚ƒٹ‚ًچإڈd—v—e‹^ژز‚ة‚µ‚ؤ–â‘è‚ًچi‚èچ‚ق‚ج‚ھ‚و‚¢‚إ‚µ‚ه‚¤پB
’چ1پFProLiant Support Pack‚ج—ھپBHP‚جƒTپ[ƒo—p‚جƒhƒ‰ƒCƒoپAƒGپ[ƒWƒFƒ“ƒgپAƒcپ[ƒ‹‚ب‚ا‚ً‚ـ‚ئ‚ك‚ؤ“±“üپEچXگV‚·‚邽‚ك‚جƒ†پ[ƒeƒBƒٹƒeƒB‚إ‚·پB
’چ2پFAutomatic Server Recovery‚ج—ھپBƒTپ[ƒo“à•”‚جچ‚‰·ڈَ‘ش‚âƒvƒچƒZƒbƒTƒ{پ[ƒhڈلٹQپAƒJپ[ƒlƒ‹–³‰“ڑڈَ‘ش‚ب‚ا‚جˆظڈي‚ًŒں’m‚µ‚½ڈêچ‡‚ةپAژ©“®“I‚ةچؤ‹N“®‚ًچs‚¢پAƒTپ[ƒo‚ً•œ‹Œ‚·‚é‹@”\‚إ‚·پB
Copyright © ITmedia, Inc. All Rights Reserved.