[無視できない]IEのContent-Type無視:教科書に載らないWebアプリケーションセキュリティ(2)(1/2 ページ)
XSSにCSRFにSQLインジェクションにディレクトリトラバーサル……Webアプリケーションのプログラマが知っておくべき脆弱性はいっぱいあります。そこで本連載では、そのようなメジャーなもの“以外”も掘り下げていきます(編集部)
無視できないIEの「Content-Type無視」問題
皆さんこんにちは、はせがわようすけです。
第2回では、Internet Explorer(以下、IE)の仕様でも特に悪名高い「Content-Type無視」について説明します。
IEのContent-Type無視問題は非常に複雑で、私自身も完全に説明できる自信はないのですが、それでもセキュアなWebアプリケーションを開発するうえで避けては通れない問題ですので、取り上げることにしました。もし記事内に間違いなどを見つけた場合は、ぜひご指摘いただけると幸いです。
なお、本稿では特に明記していない限り、IE6およびIE7を対象としています。
Content-Type無視によるXSS
IEのContent-Type無視問題は、Webアプリケーションの開発や検査にかかわる方であれば一度は耳にしたことがあると思います。
例えば、以下のような「テキストファイル」をIEで開いたとします。
HTTP/1.1 200 OK
Content-Type: text/plain
<br/>
これはテキストファイルです。
<script>alert("xss");</script>
この場合、IEは“text/plain”と指定されたContent-Typeヘッダに従わず、コンテンツ内に含まれる内容から「HTML」であると判断して、そこに含まれるスクリプトを実行してしまいます。
この場合、IEは“text/plain”と指定されたContent-Typeヘッダに従わず、コンテンツ内に含まれる内容から「HTML」であると判断して、そこに含まれるスクリプトを実行してしまいます。
例えば、Wikiなどのプレーンテキストを表示するような機能を持つWebアプリケーションに上記のファイルをアップロードすると、攻撃者によるクロスサイトスクリプティング(XSS)攻撃が可能となってしまいます。これは、HTMLではないコンテンツであるにもかかわらず、IEが「HTMLである」と判断してしまうために発生する問題です。本質的にはWebブラウザ側(IE)で修正されるべき問題なのですが、これも第1回と同じように、互換上の問題から、なかなか対応が進まないようです。
以下、IEがコンテンツを最終的にどのような種類のドキュメントとして扱うかを「ファイルタイプ」と書くことにします。「IEではContent-Typeやコンテンツの内容を基にファイルタイプを決定している」と考える方がスムーズに理解できるからです。
さて、IEがContent-Typeだけでなく、ファイルタイプを決定するためにコンテンツの内容をスキャンする動作は「Content sniffing」と呼ばれており、Content-Typeで指定された値やコンテンツに含まれる内容に応じて複雑に変化します。
Content sniffing自体に関する詳細な説明はここでは省きますが、例えば「Mime Signatures - Web Security Research at Berkeley」および「Secure Content Sniffing for Web Browsers or How to Stop Papers from Reviewing Themselves
」という資料では、IEに限らずさまざまなWebブラウザがどのように内容をスキャンし、ファイルタイプを決定しているのかを詳しく説明しています。
これまでも経験則として「text/plainおよびimage/bmpの動的生成は避ける」といったことが行われてきたと思います。
このような、Content sniffingによってファイルタイプがHTMLと判断されてXSSが発生することを防ぐには、
- IE側では「拡張子ではなく、内容によってファイルを開くこと」を「無効にする」に設定する
- サーバ側のレスポンスヘッダに X-Content-Type-Options: nosniff を追加する(IE8向け)
という対策を行い、Content sniffingを無効にします。
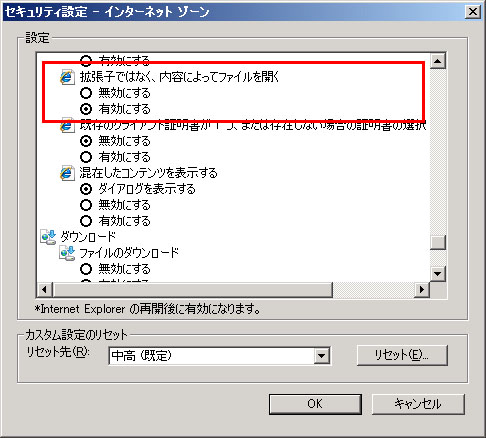
ファイルタイプをどのように判断するのか
前記のような方法でContent sniffingの設定を変更できますが、Content sniffingはコンテンツの処理方法を決定するための要因の1つにすぎず、Content sniffingが無効になっている場合でも、HTMLではないものがHTMLと判断されXSSを引き起こす場合があります。
IEがコンテンツの処理方法を決定するための要因としては、少なくとも以下の3種類が使われています。
- サーバのレスポンスヘッダで指定されたContent-Type
- コンテンツ自身の中身(Content sniffing)
- URL
IEは、これら3種類の情報と、レジストリ(HKCR\Mime\Database\Content Type)に登録されている情報によってファイルタイプを決定していると考えられます。
レジストリ(HKCR\Mime\Database\Content Type)には、IEが扱うことのできるContent-Typeの一覧が格納されており、サーバからのレスポンスヘッダによって返されたContent-Typeが、レジストリに登録されているかどうかでIEの動作は大きく変わります。
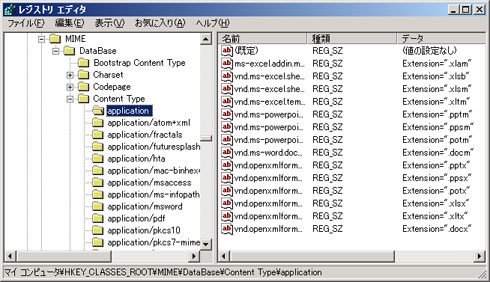
●レジストリに登録されている場合
サーバの指定したContent-Typeがレジストリ(HKCR\Mime\Database\Content Type)に登録されている場合は、その登録内容に基づき以下のように処理されます。
・IE以外のアプリケーションが処理する場合
PDFのように外部プラグインを呼び出すか、プラグインが見つからない場合はダウンロードダイアログが表示されます。
・Content sniffingが有効な場合
前述のとおり、Content sniffingに基づきファイルタイプが決定されます。
・Content sniffing が無効な場合
サーバ側で指定されたContent-Typeに従って、IE自身がそのコンテンツを処理します。
●レジストリに登録されていない場合
サーバの指定したContent-Typeがレジストリ(HKCR\Mime\Database\Content Type)に登録されていない場合は、IEは以下のようにファイルタイプを決定します。ここで、「URL拡張子」はURL中のパス名に含まれる拡張子部分を、「QUERY_STRING」はURL中の?以降を指すものとします。例えば、URLが「http://example.com/search.cgi?q=text」であった場合、URL拡張子は“.cgi”を、QUERY_STRINGは“q=text”を示します。
・URL拡張子が“.exe”または“.cgi”であった場合
QUERY_STRINGの末尾部分の“.xxx”の部分が拡張子として使われ、それに基づくファイルタイプが選択されます。例えば、URLが“http://example.com/search.cgi?q=abcd.html”であった場合、拡張子は“.html”となり、ファイルタイプとしてはHTMLが選択されます。
ファイルタイプに対応するハンドラとして外部プラグインが登録されている場合は、該当するプラグインが呼び出されます。選ばれたファイルタイプがIE自身で処理できず、外部プラグインの登録もない場合は、ダウンロードダイアログが表示されます。
ファイルタイプとして“.txt”などが選択された場合には、Content sniffingが無効に設定されていてもContent sniffingが働き、これによりファイルタイプが決定されます。
QUERY_STRINGに拡張子に該当する文字列が含まれない場合は、後述の「URL拡張子が“.exe”および“.cgi”以外の場合」のように処理されます。
・URL拡張子が“.exe”および“.cgi”以外の場合
URL拡張子がそのままファイルタイプの決定に使われます。例えば、URLが“http://example.com/search.pl?q=abcd.html”であった場合、拡張子は“.pl”となり、ファイルタイプとしては“.pl”が選択され、それに応じたハンドラがレジストリから検索されます。
ファイルタイプに対応するハンドラとして外部プラグインが登録されている場合は、該当するプラグインが呼び出されます。選ばれたファイルタイプがIE自身で処理できず、外部プラグインの登録もない場合は、ダウンロードダイアログが表示されます。
また、例えばURLが“http://example.com/search.pl/a.txt?q=abcd”であった場合など、ファイルタイプとして“.txt”などが選択された場合には、Content sniffingが無効に設定されていてもContent sniffingが働き、これによりファイルタイプが決定されます(大抵のCGIプログラムであれば、余分なPATH_INFOを付与しても動作します)。
Copyright © ITmedia, Inc. All Rights Reserved.