ここが大変だよBigtableとGoogle App Engine:分散Key-Valueストアの本命「Bigtable」(3)(1/2 ページ)
RDBとは別の、クラウド時代のデータベースとして注目を浴びている「分散Key-Valueストア」。その本命ともいえる、Googleの数々のサービスの基盤技術「Bigtable」について徹底解説
月間3000万PVの大規模サイトの運用費が月額4万円!?
月間3000万PV相当の膨大なトラフィックを楽々とさばく大規模サイトが、月額4万円弱で運用されている。
Google App Engine(以下、App Engine)が普及するにつれて、そんな驚愕の国内事例も登場しつつあります。GClueがApp Engine上で実装したmixiアプリモバイルモバイルには、1日100万PV以上のアクセスが集中している状態でもサービスのレスポンス低下やダウンは皆無だそうです。1日の運用コスト(グーグルへの支払い料金)は$12程度で、プログラマ以外に専任のサーバ管理者などはまったく不要とのことです。
こうしたApp Engineのけた違いのスケーラビリティやコストパフォーマンスといった大きな「価値」を得るには、われわれエンジニアがそれ相応の「発想の転換」を受け入れる必要があります。
前回の「素朴なBigtable、できること できないこと」でも説明したとおり、App Engineの中核をなすデータストア「Bigtable」は、「キーを指定して値を読み書きする」という単純な機能しかサポートしていない分散Key-Valueストア(分散KVS)です。この素朴なデータストアの大きな制約を受け入れ、そのうえで複雑なWebアプリケーションのロジックをいかにして実装できるか工夫していくことが、この発想の転換へのはじめの一歩となります。
繰り返すが、Bigtableの検索機能は「スキャン」だけ
前回も説明したとおり、Bigtableは、リレーショナルデータベース(RDB)におけるクエリやジョインを一切サポートしておらず、以下の2種類の機能だけを提供しています。
- キーに基づく行のCRUD
- キーに基づく「スキャン」
「キーに基づく行のCRUD」とは、個々の行に割り当てられた「キー」を指定して、行のCRUD(追加、取得、更新、削除)を行うことです。一方、「キーに基づくスキャン」とは、キーの前方一致検索、もしくは、範囲指定検索により、複数の行を一括取得する機能です。
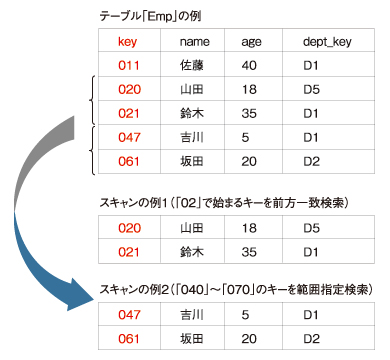
例えば上記の「スキャンの例1」では、テーブル「Emp」に対して、キーが「02」で始まる行を前方一致検索でスキャンし、「山田」「鈴木」という2行を取得しています。また「スキャンの例2」では、キーが「040」から「070」までの行を範囲指定検索でスキャンし、「吉川」「坂田」の2行を得ています。
Bigtableが備える唯一の検索は、このスキャンだけです。つまり、値を条件とした検索は一切実行できません。Bigtableについて学び始めた当初、筆者は「これでどうやってアプリケーションロジックを書くのだろう」と悩みました。しかし、App Engineでは、この問いに答えるソリューションを提供しています。それは、Bigtable上でRDBライクなクエリ機能を実装する「Datastoreサービス」です。
Datastoreサービスと3つのAPI
Datastoreサービスとは、App Engine上で動作するPythonもしくはJavaアプリケーションがBigtableにアクセスするためのサービスであり、主に以下の3つの機能を提供します。
- キーに基づくエンティティのCRUD
- エンティティに対するクエリ
- 数エンティティを対象としたトランザクションのACID保証
ここで「エンティティ」とは、PythonやJavaの個々のオブジェクトを保存したBigtableの行を表します。Datastoreサービスでは、このエンティティに対してキーに基づくCRUDが可能です。加えて、RDBライクな「クエリ」によるエンティティの検索を実行できるのが重要なポイントです。App EngineのJava版の場合、これらのDatastoreサービスの機能は、以下の3つのAPIを通じて利用できます。
- JDO(Java Data Objects)
- JPA(Java Persistence API)
- 低レベルAPI(Low-level API)
これらのうち、「JDO」および「JPA」は、JCP(Java Community Process)を通じて策定された標準のデータ永続化APIです。とはいえ、JDOやJPAの機能をフル実装しているわけではなく、あくまで「Bigtableで実装できる機能のみ標準APIに合わせて提供している」といった位置付けです。
一方、低レベルAPI(以下、LL)はApp Engine独自のAPIであり、ほかの2つのAPIに比べてより“生の”Bigtableに近い機能を提供します(なお、以下ではJDOに基づいて説明を続けますが、これら3つのAPIのいずれを選択すべきかについては、本稿最後の章をご覧ください)。
キーに基づく行のCRUD
さて、1つめの機能である「キーに基づくエンティティのCRUD」は、先に記したBigtableの「キーによる行のCRUD」と同じ機能です。以下は、JDOによるエンティティ保存の記述例です。
PersistenceManager pm = PMF.get().getPersistenceManager();
Emp e = new Emp("山田", 18, "D5");
try {
pm.makePersistent(e);
} finally {
pm.close();
}
この例のように、PersistentManagerクラスのmakePersistent()メソッドに続いてcloseメソッドを呼び出すことで、JavaオブジェクトであるEmpをBigtableの1行として保存できます。ちなみに、こうしたCRUD処理に要する平均時間は数10ms程度で、前回説明したとおり、たとえ数千万件のエンティティが保存されていても処理時間は変化しません。
またBigtableでは、ACID特性の保証の範囲が行単位であったのに対し、Datastoreサービスでは「エンティティ・グループ」と呼ばれる複数のエンティティの集まりを対象としてACID特性の保証が可能です。よって、例えば「Deptエンティティ」と「Empエンティティ」を同じエンティティ・グループに含めておけば、トランザクションの競合時でも不整合の発生を防ぐことができ、一般的なRDBと同等の信頼性を確保できます。
Datastoreサービスの「クエリ」
Datastoreサービスのもう1つの機能である「クエリ」とは、エンティティのプロパティ(フィールド)の値を条件とする検索機能です。以下は、JDOを用いてクエリを実行するコードの例です。
uery query = pm.newQuery("select from Emp " + "where age >= _startAge & age <= _endAge " + "order by age asc " + "parameters int _startAge, int _endAge")List<Emp> results = (List<Emp>) query.execute(20, 40);
この例では、JDOが定めるSQLライクなクエリ言語である「JDOQL」でクエリ条件を記述し、Queryオブジェクトのexecute()メソッドを呼び出してクエリを実行しています。上記のクエリは「ageプロパティが20〜40のEmpエンティティ一覧を取得し、ageプロパティの昇順でソートする」という意味です。こうしたクエリは、通常150〜200ms程度の時間で処理されます。
このように、一見するとDatastoreではRDBのような「テーブルのカラム値を条件とした検索」が実行できているように見えます。しかし繰り返し説明したとおり、Bigtableはあくまで「スキャン」しか実行できません。この間を埋めるカギが、「シングルプロパティインデックス」です。次ページで解説します。
Copyright © ITmedia, Inc. All Rights Reserved.