āCāōā^ü[āŖāģü[āh: TwitteréŲRüFÄ└æHüI Ré┼ŖwéįōØīvēÉ═é╠ŖŅæbüi5üjüi1/2 āyü[āWüj
ŹĪē±é═TwitteréŲéóéżÉgŗ▀é╚æĶŹ▐éÄgé┴é─üARé╔éµéķāfü[ā^ĹÅWéŲē┬Äŗē╗ééŌé┴é─é▌é▄éĘüBRé╠¢LĢxé╚āēāCāuāēāŖéÄgé”é╬łėŖOé╔ÄĶīyé╔é┼é½é▄éĘüB
ŹĪē±é═ŖįætōIé╔ITŖ±éĶé╠śbæĶé
ü@é▒é╠śAŹ┌é═üŚITé╠śAŹ┌é┼éÓé®é╚éĶ¢čÉFé╠łßéżōÓŚeé┼éĘüBé╗éĻé╔éÓé®é®éĒéńéĖæOē±é▄é┼é╠4ē±é═üAōØīvōIī¤ÆĶééóé½é╚éĶō▒ō³éĄéĮéĶüAō·¢{ÉŁĢ{éŌÉóŖEŗŌŹsé╠īoŹŽōØīvé╔āAāNāZāXéĄé─é▌éĮéĶüAé│éńé╔é═WikiLeaksé╠¢\śIāfü[ā^éōØīvēÉ═éĄé─é▌éĮéĶéŲüAé®é╚éĶānü[āhāRāAé╚ōÓŚeé╔æ¢é┴é─éĄé▄éóé▄éĄéĮüB
ü@æµ4ē±é╠üuéĀéŲé¬é½üvé┼é═ō»éČśHɳé┼ō╦é┴æ¢éļéżéŲéóéżé▒éŲéÉ\éĄÅŃé░é─éóéĮé╠é┼éĘé¬üAŹĪē±é═ŖįætüiāCāōā^āŖāģü[āhüjéŲéĄé─üAéµéĶüŚITéńéĄéŁüAITŖ±éĶé╠śbæĶéĵéĶÅŃé░éĮéóéŲÄvéóé▄éĘüB
TwitteréŲR
ü@Twitteré╠ÉlŗCé═ÉóŖEōIé╔é▄éŠé▄éŠæ▒éóé─éóéķéµéżé┼éĘüB2010öN8īÄīŃö╝é╔öŁĢ\é│éĻéĮ2010öN6īÄĢ¬é╠ōØīvé╔éµéĻé╬üAī╗Ź▌é═āCāōāhālāVāAéŌāuāēāWāŗüAāxālāYāGāēé╚éŪé╠ÉVŗ╗Źæé╠ÉLéčé¬éĘé▓éóé╗éżé┼éĘüB
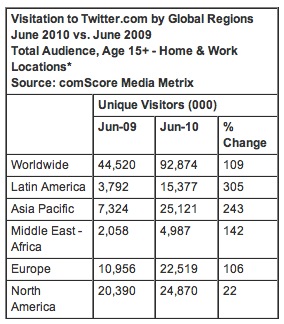
ü@ō·¢{é┼éÓé▄éŠ17üōéŲéóéżŗ}ɼÆĘéæ▒é»é─éóé▄éĘüBĢ─Źæé┼é═Twitteré╠ɼÆĘé¬Ä~é▄é┴éĮéŲéóéżś_Źlé¬ēĮōxéÓÅoé─éóé▄éĘé¬üAÄ└é═āéāoāCāŗéŖ▄é▀éĮōØīvéī®éķéŲüAé▒é┐éńéÓé▄éŠé▄éŠÉLéčæŃé¬Å\Ģ¬é╚éµéżé┼éĘüB
ü@é│é─üAé╗é╠ÉlŗCé╠Twitteré┼éĘé¬üAé▒é╠éµéżé╔āåü[āUü[é╠ÉöéŌŚśŚpĢpōxé¬æÕé½éŁé╚é┴é─éŁéķéŲüAéŠé±éŠé±éŲō·ÅĒÉČŖłé╔īćéŁé▒éŲé╠é┼é½é╚éóÄąē’ŖųīWÄæ¢{üisocial capitalüFÄąē’é╔é©éóé─ÉlüXé¬ÄØé┬ÉlŖįŖųīWéŌÉMŚŖŖųīWé╠é▒éŲüjé╠āCāōātāēāXāgāēāNā`āāü[é╠éµéżé╚æČŹ▌é╔é╚é┴é─é½é─éóéķéŲīŠé”éķé┼éĄéÕéżüBéĀéķ¢╩é┼é═üAī┬Élé╠ÜnŹDüiéĄé▒éżüjéŌæIŹDüAÄąē’é╠ī╗Ź▌é╠āgāīāōāhé╚éŪé¬Ŗiö[é│éĻé─éóéķüAÉlŖįŖųīWŗyéčī┬Élé╠ÜnŹDé╠Ŗ╚łšōIé╚āfü[ā^āxü[āXéŲŹlé”éķé▒éŲéÓé┼é½é╗éżé┼éĘüBé╗é╠éµéżé╔Źlé”éķéŲüATwitteré╠āåü[āUü[ō»Ämé╠ŖųīWéŌō·üXéŌéĶéŲéĶé│éĻéķ¢cæÕé╚tweetéāfü[ā^ā}āCājāōāOéŌāfü[ā^ēÉ═é╔ŚśŚpéĘéķé▒éŲé┼ŚLŚpé╚ÅŅĢ±éōŠéķé▒éŲé¬é┼é½é╚éóé®üAéŲéó鿏lé”é¬Åoé─éŁéķé▒éŲéŲÄvéóé▄éĘüBŹĪē±é╠ŗLÄ¢é┼é═üAānü[āhāRāAé╚āfü[ā^ā}āCājāōāOéŌāfü[ā^ēÉ═é═Źséóé▄é╣é±é¬üAé╗é╠ā}āCājāōāOéŌēÉ═ééĘéķō³éĶī¹é▄é┼é╠āAāvāŹü[ā`éƱĔéĘéķé▒éŲé¢┌ōIéŲéĄé▄éĘüB
ü@Twitteréāfü[ā^āxü[āXéŲéĄé─ŚśŚpéĄüARéÄgé┴é─é╗é╠āfü[ā^ēÉ═ééĘéķéĮé▀é╔é═üARéŲTwitteréśAīgé│é╣éķĢKŚvé¬éĀéĶé▄éĘüBé╗é╠éĮé▀é╠āpābāPü[āWé¬CRANé╔éĀéĶé▄éĘüBé╗éĻé¬twitteRé┼éĘüBtwitteRé═Twitteré╠REST APIéāēābāsāōāOéĄé─éóéķāpābāPü[āWé┼üAé▒éĻ錜ŚpéĘéķéŲRéTwitteré╠āNāēāCāAāōāgé╔éĘéķé▒éŲé¬é┼é½é▄éĘüB
üEtwitteR
ü@é▒é▒é®éńé═üAtwitteR錜ŚpéĄé─üATwitteré®éńł°é½Åoé╣éķÅŅĢ±é╠ē┬Äŗē╗éŲāeāLāXāgā}āCājāōāOé╠āCāōāgāŹā_āNāVāćāōéŹséóéĮéóéŲÄvéóé▄éĘüB
ü@é▄éĖtwitteRéāCāōāXāgü[āŗéĄé▄éĘüBRé╠æ╬śbāvāŹāōāvāgé®éńinstall.packagesŖųÉöéī─éčÅoéĄé▄éĘüBCRANāTāCāgé╔é┬éóé─é═üAŚßé”é╬ügJapnüiTukubaüjühéæIæéĄé─éŁéŠé│éóüB
> install.packages("twitteR")
ü@ŹĪē±é═é▒é╠twitteRł╚ŖOé╔éÓüAigraphéŲRMeCab錜ŚpéĄé▄éĘüBé▒éĻéÓé▒é▒é┼āCāōāXāgü[āŗéĄé─éĄé▄éóé▄éĄéÕéżüBéĮéŠéĄüARMeCabé╔é┬éóé─é═üAinstall.packagesŖųÉöé┼āCāōāXāgü[āŗé┼é½é▄é╣é±üBé▒éĻé═üAīŃé┘éŪŗLÅqéĄé▄éĘé¬üAā_āEāōāŹü[āhāTāCāgéµéĶāoāCāiāŖātā@āCāŗéā_āEāōāŹü[āhéĄé─üAāŹü[āJāŗāfāBāXāNé®éńāCāōāXāgü[āŗéĘéķé▒éŲé╔é╚éĶé▄éĘüB
> install.packages("igraph")
friendséŲfollowerséē┬Äŗē╗éĘéķ
ü@é│é─üAé▒é╠twitteRé╠ŚśŚpĢ¹¢@é┼éĘé¬üAĢüÆ╩é╠āNāēāCāAāōāgéŲō»éČéµéżé╔üATwitteré╠āAāJāEāōāgüiāAāJāEāōāg¢╝éŲāpāXāÅü[āhüjé¬ĢKŚvé┼éĘüBé▄éĖüAtwitteRéTwitterāNāēāCāAāōāgéāXā^ü[āgé│é╣éķéĮé▀é╔āZābāVāćāōéŖJÄnéĘéķĢKŚvé¬éĀéĶé▄éĘüBé╗éĻé╔é═initSessionŖųÉö錜ŚpéĄé▄éĘüB
> library(twitteR)
> session <- initSession("YOURNAME", "YOURPASS")
> session
An object of class ügCURLHandleüh
Slot "ref":
<pointer: 0xa50000>
ü@ YOURNAMEéŲYOURPASSé╔é═é╗éĻé╝éĻüAé▓Ä®Égé╠TwitterāAāJāEāōāg¢╝éŲāpāXāÅü[āh錜ŚpéĄé─éŁéŠé│éóüBinitSessionŖųÉöé®éńĢįé│éĻéķé╠é═Unixé╠CURLāRā}āōāhéāēābāvéĄéĮügCURLHandleühāIāuāWāFāNāgé┼üAtwitteRé╠ŖųÉö錜ŚpéĘéķéŲé½é╔é▒é╠āIāuāWāFāNāgéł°Éöé╔ōnéĄé─éŌéķĢKŚvé¬éĀéĶé▄éĘüB
ü@Twitteréō┴ÆźōIé╔éĄé─éóéķéÓé╠é╠1é┬é╔üATwitteré╠ÄQē┴Äęé╠Ŗįé┼following/follwerŖųīWéŲéóéż¢cæÕé╚Äąē’ŖųīWé¬āCāōā^ü[ālābāgÅŃé╔Ź\Æzé│éĻé─éóéķüAéŲéóéżé▒éŲé¬ŗōé░éńéĻéķéŲÄvéóé▄éĘüBé╗é╠łė¢Īé┼üATwitteré═Äąē’ŖųīWÄæ¢{üisocial capitalüjé╠āCāōātāēāXāgāēāNā`āāü[é╔é╚éĶōŠéķéŲüAé▒é╠Źeé╠¢`ō¬é┼Åqéūé▄éĄéĮüBé▒é▒é┼é═é╗é╠Twitteré╠follwing/followerŖųīWéē┬Äŗē╗éĄéĮéóéŲÄvéóé▄éĘüB
ü@twitteRé┼é═üAÄ®Ģ¬éŌæ╝é╠ÉlŖįé╠followingéĄé─éóéķÉlĢ©éā^ü[āQābāgéŲéĄé─üAé╗é╠ā^ü[āQābāgé╠āŖāXāgéōŠéķé╔é═userFriends錜ŚpéĄé▄éĘüBæµ1ł°Éöé╔é═Æ▓éūéĮéóāAāJāEāōāgéāXāgāŖāōāOé®twitteRé╠userāIāuāWāFāNāgéō³éĻüAæµō±ł°Éöé╔é═Ź┼æÕÆlüAæµÄOł°Éöé╔é═ɵé┘éŪĵōŠéĄéĮāZābāVāćāōāIāuāWāFāNāgéō³éĻé▄éĘüBāåü[āUé╠āŖāXāgé¬Ģįé│éĻé▄éĘüBé▒é▒é┼ÆŹłėō_é┼éĘé¬üAæµō±ł°Éöé╠né100ł╚ē║é╔éĄé─éÓ100ī┬é╠āŖāXāgé¬Ģįéķéµéżé╚ÄdŚlé╔é╚é┴é─éóéķéµéżé┼éĘüB
> target <- "hatoyamayukio" > friends.obj <- userFriends(target, n = 100, session) > head(friends.obj) [[1]] [1] "barthkoch" [[2]] [1] "rimaruko" [[3]] [1] "sean_fuji" [[4]] [1] "gu_cci" [[5]] [1] "usavich3" [[6]] [1] "amanecs"
ü@Ä└Ź█é╔ōŪÄęé╠ŖFé│é±é╠ēµ¢╩é╔Ģ\Ä”é│éĻéĮīŗē╩é═üAÅŃé╠éÓé╠éŲé═ł┘é╚éķé®éÓÆméĻé▄é╣é±üBé╗éĻé═üATwitteré╔é©é»éķŖųīWé═Ä×üXŹÅüXĢŽē╗éĄé─éóéķéĮé▀é┼éĘüBō»Ślé╔followerséĵōŠéĘéķé╔é═üAuserFollowers錜ŚpéĄé▄éĘüBé│é─üAé▒é▒é┼ā^ü[āQābāgé╠followingéŲfolloweré╠āŖāXāgéĵōŠéĄüAé╗é╠āfü[ā^éāOāēātĢ\ī╗é┼ÄŗŖoē╗éĄéĮéóéŲÄvéóé▄éĘüBé╗é╠éĮé▀é╔üAfollwingéŲfollwersé╠āAāJāEāōāg¢╝é1é┬é╠āfü[ā^ātāīü[āĆé╔Ŗiö[éĄé▄éĘüBuserFriendséŌuserFollowersé®éńĢįé│éĻéķāŖāXāgāIāuāWāFāNāgé╠ÆåÉgéī®é─é▌éķéŲł╚ē║é╠éµéżé╔é╚é┴é─éóé▄éĘüB
> str(friends.obj) List of 100 $ :Formal class 'user' [package "twitteR"] with 14 slots .. ..@ description : chr "" .. ..@ statusesCount : num 17 .. ..@ followersCount: num 20 .. ..@ favoritesCount: num(0) .. ..@ friendsCount : num 80 .. ..@ url : chr(0) .. ..@ name : chr "barthkoch" .. ..@ created : chr "Thu Aug 20 21:03:33 +0000 2009" .. ..@ protected : logi FALSE .. ..@ verified : logi FALSE .. ..@ screenName : chr "barthkoch" .. ..@ location : chr "Brazil" .. ..@ id : num 67424072 .. ..@ lastStatus :Formal class 'status' [package "twitteR"] with 10 slots ...
ü@éŪéżéŌéńüAscreenNameé¬āåü[āUé╠āAāJāEāōāg¢╝é╠éµéżé┼éĘüBé▒é▒é┼@é┼Äné▄éķéÓé╠é¬āŖāXāgé╔Ŗiö[é│éĻé─éóéķæ«É½āIāuāWāFāNāgé┼üAæ«É½āIāuāWāFāNāgé═üuāLü[üvéŲüuÆlüvé╠āyāAé╔é╚é┴é─éóé▄éĘüBæ«É½āIāuāWāFāNāgé®éńæ«É½ÆléĵéĶÅoéĘé╔é═üAé╗é╠āLü[éŖųÉöéŲéĄé─ōKŚpéĄé▄éĘüBÄÄéĄé╔āŖāXāgé®éń1é┬¢┌é╠æ«É½āIāuāWāFāNāgéŠé»éĵéĶÅoéĄé─üAé╗é╠āLü[screenNameéŖųÉöéŲéĄé─ōKŚpéĄé─é▌é▄éĄéÕéżüB
> screenName(friends.obj[[1]]) [1] "barthkoch"
ü@é▒éĻé┼üAuserFriendséŌuserFollowersé®éńĢįé│éĻéķāŖāXāgāIāuāWāFāNāgé╔Ŗiö[é│éĻé─éóéķāAāJāEāōāg¢╝éĵéĶÅoéĘĢ¹¢@é¬Ģ¬é®éĶé▄éĄéĮüBé▒éĻéæSé─é╠āŖāXāgé╔ōKŚpéĄüAwé┬é╠āfü[ā^ātāīü[āĆé╔ōØŹćéĘéķé╔é═Ĥé╠éµéżé╔éĄé▄éĘüBfollowersé╠āŖāXāgéÓé┬éóé┼é╔ĵōŠéĄé─é©é½é▄éĄéĮüB
> followers.obj <- userFollowers(target, n = 100, session)
> friends <- sapply(friends.obj, screenName)
> followers <- sapply(followers.obj, screenName)
> relationsdf <- merge(data.frame(User = target, Follower = friends),
+ data.frame(User = followers, Follower = target),
+ all = T)
> head(relationsdf)
User Follower
1 hatoyamayukio 178REIJI
2 hatoyamayukio 3hit
3 hatoyamayukio 921_u3u3
4 hatoyamayukio a_ikenag
5 hatoyamayukio ace_champ
6 hatoyamayukio achora
> tail(relationsdf)
User Follower
195 YoshidaFumitaka hatoyamayukio
196 yoshitada9646 hatoyamayukio
197 ysugihara1221 hatoyamayukio
198 yuki70424b hatoyamayukio
199 yunikonnyaku hatoyamayukio
200 yutakakanagawa hatoyamayukio
ü@é▒é▒é┼üAfollowingāŖāXāgāIāuāWāFāNāgéŲfollowersāŖāXāgāIāuāWāFāNāgé╔screenNameéłĻŖćōKŚpéĘéķéĮé▀é╔sapply錜ŚpéĄé▄éĄéĮüBé▄éĮüAāfü[ā^ātāīü[āĆéŹņɼéĘéķé╔é═data.frameüAŹņɼéĄéĮ2é┬é╠āfü[ā^ātāīü[āĆéōØŹćéĘéķé╔é═mearge錜ŚpéĄé▄éĄéĮüB
ü@headéŲtailé┼Ź┼Åēé╠Ģ¹éŲŹ┼īŃé╠Ģ¹é╠User-FollowerŖųīWéé▌é▄éĘéŲüAÉ│ÅĒé╔āfü[ā^ātāīü[āĆé¬é┼é½é─éóéķéµéżé┼éĘüB
ü@Ĥé═é▒é╠User-FollwerŖųīWé╠ÄŗŖoē╗é┼éĘüBé▒éĻé═User -> FollowerŖųīWé╔é╚é┴é─éóéķé╠é┼üAāOāēātŚØś_é╠ŖTöOé┼éóéżéŲé▒éļé╠ŚLī³āOāēāté┼éĘüBRé┼ŚLī³āOāēātéÄŗŖoē╗éĘéķé╔é═igraphāpābāPü[āW錜ŚpéĘéķé╠鬳ĻöįÄĶé┴ĵéĶæüéóé┼éĘüB
üEigraph
ü@igraphāpābāPü[āW錜ŚpéĘéķéĄé─āOāēātéĢ`ēµéĘéķé╔é═üAÆ╩ÅĒé╠āfü[ā^ātāīü[āĆéÆĖō_éŲĢėé╠æ«É½éĢté»ē┴é”éĮāfü[ā^ātāīü[āĆé╔ĢŽŖĘéĘéķĢKŚvé¬éĀéĶé▄éĘüBé▒éĻéŹséżé╠é¬graph.data.frameé┼éĘüB
> library(igraph)
> g <- graph.data.frame(relationsdf, directed = T)
> g
Vertices: 201
Edges: 200
Directed: TRUE
Edges:
[0] 'hatoyamayukio' -> '178REIJI'
[1] 'hatoyamayukio' -> '3hit'
[2] 'hatoyamayukio' -> '921_u3u3'
[3] 'hatoyamayukio' -> 'a_ikenag'
...
ü@ŹĪē±é═graph.data.frameé╔directed = TéŲéóéżĢ¹ī³Ģté»āIāvāVāćāōéÄwÆĶéĄéĮé╠é┼üAUser -> FollowerŖųīWé¬Ģ\ī╗é┼é½é▄éĄéĮüBé▒é╠gé¬igraphé┼ŚśŚpéĘéķāfü[ā^ātāīü[āĆé┼éĘé¬üAÆĖō_āIāuāWāFāNāgéŲĢėāIāuāWāFāNāgéĵéĶÅoéĘé╔é═üAVéŲE錜ŚpéĄé▄éĘüBVé═"V"ertecüiÆĖō_üjüAEé═"E"dgeüiĢėüjéłė¢ĪéĄé▄éĘüBÆĖō_é╠āIāuāWāFāNāgé╠¢╝æOéĵéĶÅoéĘé╔é═$nameé╔éµéĶĵéĶÅoéĄé▄éĘüB
> head(V(g))
Vertex sequence:
[1] "20100912pm3" "24KinKiKids51" "313so" "9_nanatuki" "Airi0419" "ak3161"
> head(E(g))
Edge sequence:
[1] hatoyamayukio -> 3hit
[2] hatoyamayukio -> 921_u3u3
[3] hatoyamayukio -> a_ikenag
[4] hatoyamayukio -> ace_champ
[5] hatoyamayukio -> achora
[6] hatoyamayukio -> ahoneko_tom
> head(V(g)$name)
[1] "hatoyamayukio" "20100912pm3" "24KinKiKids51" "313so" "9_nanatuki" "Airi0419"
> V(g)$label
NULL
> V(g)$label <- V(g)$name
ü@Ź┼īŃé╠āRü[āhé═üAāOāēātéÅæéóéĮéŲé½é╔ŗLÅqé│éĻéķÆĖō_é╠āēāxāŗ$labelé╔$nameæ«É½é╔éĀéķāAāJāEāōāg¢╝éé╗é╠é▄é▄ō³éĻé▄éĄéĮüBé▒éĻé┼āOāēātéĢ`éŁÅĆö§éé¬É«éóé▄éĄéĮüBāOāēātéĢ`éŁé╠é═Ä└é═éĘé▓飌ełšé┼üAłĻöįŖ╚ÆPé╚āOāēāté═plotŖųÉöéāOāēātāfü[ā^ātāīü[āĆé╔ōKŚpéĘéķéŠé»é┼éĘüB

ü@éĄé®éĄüA100ł╚ÅŃé╠ÆĖō_āIāuāWāFāNāgé¬éĀéķÅĻŹćüAāIāuāWāFāNāgé¬Ådé╚é┴é─éĄé▄éóé▒éĻé┼é═éµéŁĢ¬é®éĶé▄é╣é±üBé╗é▒é┼öõŖrōIŹéŗ@ö\é╠āOāēātĢ`ēµŖųÉöé┼éĀéķtkplot錜ŚpéĄé─é▌é▄éĘüBé▒éĻé═tkāOāēātāBābāNāēāCāuāēāŖÅŃé╔Źņɼé│éĻéĮāOāēātāvāŹābāgāēāCāuāēāŖé┼éĘüB
> tkplot(g)
ü@tkplotŖųÉöé┼é═üAüAügLayoutühāüājāģü[é®éńāOāēāté╠özÆuéĢŽŹXéĘéķé▒éŲé¬é┼é½é▄éĘüBŚßé”é╬üAKawada-KawaiāAāŗāSāŖāYāĆéæIé±é┼āvāŹābāgéĘéķéŲł╚ē║é╠éµéżé╚āOāēāté╔é╚éĶé▄éĘüB

ü@é▒é╠tkploté┼Ģ`é®éĻéĮāOāēātÅŃé╠āIāuāWāFāNāgé═ā}ājāģāAāŗé┼özÆué¬ĢŽŹXé┼é½é▄éĘüBé▄éĮĢėéæIéūé╬é╗é╠Ģėé¬ānāCāēāCāgéĄé▄éĘéĄüAÆĖō_éæIéūé╬ÆĖō_é¬ānāCāēāCāgéĄüAÆĖō_Ŗįé╠ŖųīWé¬éĀéķÆ÷ōxĢ¬é®éķéµéżé╔é╚é┴é─éóé▄éĘüB
ü@ł╚ÅŃé¬üATwitteré╠Äąē’ŖųīWéÄŗŖoē╗éĘéķéĮé▀é╔üAtwitteRé®éńĵōŠéĄéĮfollwing/followeré╠āŖāXāgéāOāēātē╗éĄéĘéķłĻśAé╠ÄĶÅćé┼éĘüB
Index
āCāōā^ü[āŖāģü[āh: TwitteréŲR
Page1
ŹĪē±é═ŖįætōIé╔ITŖ±éĶé╠śbæĶé
TwitteréŲR
friendséŲfollowerséē┬Äŗē╗éĘéķ
Page2
TwitterāeāLāXāgā}āCājāōāOé╠ō³¢Õé╠ō³¢Õ
Ĥē±é╔é┬éóé─
Copyright © ITmedia, Inc. All Rights Reserved.