node.jsの衝撃とWebSocketが拓く未来:WebSocketで目指せ! リアルタイムWeb(1)(1/2 ページ)
今回から3回の予定でWebSocket登場の背景、基本的な使い方の解説、応用サービスの例、ブラウザの実装状況などを解説します(編集部)
ご挨拶
こんにちは、ロンドンのNew Bambooという会社でWebエンジニアとして働いている@makoto_inoueです。ここのところ、PusherというWebSocketのクラウドサービスの開発に関わっています。今回から3回に渡ってWebSocketに関する短期連載を担当させていただきます。
私を含めたNew Bambooの面々(我々は自分たちのことをBambinoと呼んでいます)がWebSocketになぜ興味を持ったかということからはじまり、実際にクラウドサービスを始めるまでにいたったストーリーをお話ししたいと思います。そのストーリーを通じて、WebSocketが切り開く「リアルタイムWeb」な世界への可能性や技術的課題を皆さんと共有できればと思っています。
WebSocketで目指せ! リアルタイムWeb バックナンバー
- 第1回 node.jsの衝撃とWebSocketが拓く未来
- 第2回 WebSocketの現状と技術的課題
- 第3回 WebSocketでWebは変わる? 大胆予想!
途中でいくつかのサンプルコードをJavaScript(サーバサイドはnode.jsを使います)かRubyで掲載しますが、そのほかの言語で使えるツールやフレームワークも同時に紹介します。また、弊社のサービス「Pusher」は言語非依存ですので、好きな言語で試せます。
そして連載の最後で、WebSocketで作られたオープンソースプロジェクトのいくつかを紹介するとともに、今後リアルタイムWebがどのような変化をもたらすかを自分なりに大胆予測してみます。これをきっかけに、少しでも多くの方がWebSocketにトライしてみようと思っていただければと思います。

リアルタイムWebてどんなもの?
そもそも「リアルタイムWebって、どんなもの?」と読者の皆さんは思われるかもしれません。例は身近にたくさんあります。FacebookチャットやGmailでオンラインのユーザーが見えるプレゼンス機能などがその例といってよいでしょう。Twitterがワールドカップの期間中に各試合ごとのリアルタイムツイート実況ページを開設していたのも記憶に新しいと思います。また、最近開発が中止されたGoogle Waveですが、チャットの入力が1文字ごとに更新される模様に度肝を抜かれたのをご記憶の方も多いのではないかと思います。
そうなんです、Google、Facebook、Twitterといった大手のプレーヤーは、すでにリアルタイムWebをサービスの要に投入しているのです。もちろんユーザーとしては彼らのサービスをただ使うだけで十分楽しいのですが、やはり開発者やサイトオーナーであれば、そういった機能を自分のサイトにも取り入れてみたいですよね。ただ彼らが使っている技術の詳細は断片的にしか漏れていませんし、特にJavaScriptレベルでの共通した規格というのはGoogle Waveプロトコルを除いてはほぼ皆無でした。
そこに登場したのがWebSocketです。これはリアルタイムWebを実現するHTML5の準規格の1つで、私たちもすぐに興味を持ちました。

まず初めに、私たちが自社のアプリにWebSocketを利用してリアルタイムWebの機能を取り入れた例を見ていきましょう。
最初の例はプロジェクト管理アプリの「TrueStory」です。もともと自分たちのクライアントプロジェクトの管理をするために社内で使っていたのをサービス化したものです。左右に並べたブラウザの左側でプロジェクトを変更すると、右側でも変更されているのを見ていただけるでしょうか。

次の例はドラッグ&ドロップ操作と最近アジャイル開発手法の1つとして再び注目を集めている「Kanban」の文字を掛け合わせて作った「Draggan」というアプリのプロトタイプです。
 Dragganの動画(クリックで再生)
Dragganの動画(クリックで再生)先ほどの例と同じく、変更がリアルタイムで更新されるのが見ていただけると思います。
こういった日頃から使うアプリケーションは、ずっとブラウザのタブで開きっぱなしになっていることも多いと思いますが、いざ自分が更新するときになって、更新しようと思っていたデータがすでになくなっていて、エラーが出てしまったりすると非常に不便に思ったりすることはないでしょうか?
私たちが実装した2つの例では、WebSocket対応によって何か機能が変わったということはありません。しかし、刻々と変わりゆく情報をリアルタイムに更新することで、ユーザーの利便性が飛躍的に向上しています。ちょうどGmailやGoogle MapがAjaxを全面的に導入することでユーザーエクスペリエンスを劇的に向上し、Web2.0という言葉まで生み出したのに匹敵するぐらいのインパクトがリアルタイムWebにはあるのではないか、と思っています。
それではリアルタイムWebを作り上げるのに必要な基礎技術の数々を私たちが体験した順にたどっていきましょう。
node.jsの衝撃
昨年の2009年11月に話はさかのぼります。イギリス南部Brightonという町で「Full Frontal 2009」 というJavaScriptのカンファレンスに参加しました。BBCやYahoo!といった著名な会社のトップレベルのエンジニアたちが、JavaScriptの最新テクニックやトレンドについて語るイベントだったのですが、そのときにPythonのWebフレームワーク、Djangoの開発者であるSimon Willisonさんがnode.jsとついて熱く講演した内容が、その日の参加者の話題を独り占めしました。
もともと彼はJSONPを使ったクロスドメインスクリプティングについて話す予定だったのですが、講演の2週間前にnode.jsのことを知り、急遽トピックを変えたそうです。そこまで彼を駆り立てたnode.jsとはいったい何なのでしょうか?
「Node.js is genuinely exciting.」(node.jsは本当にエキサイティングだ)というタイトルの彼のブログから引用するnode.jsの説明は以下の通りです。
A toolkit for writing extremely high performance non-blocking event driven network servers in JavaScript.
「とてもハイパフォーマンスでイベント駆動なネットワークサーバをJavaScriptで書くための一連のツール群」
はっきり言って、これを最初に読んだときには「なんのこっちゃ」という印象しか残りませんでした。
「ハイパフォーマンス」というのは分かりますが、「イベント駆動なネットワークサーバ」と言われてもピンときません。
そこで彼は既存のWebサーバをウサギ、 イベント駆動のネットワークサーバをタコに例えて説明してくれました。以下の図を見てください

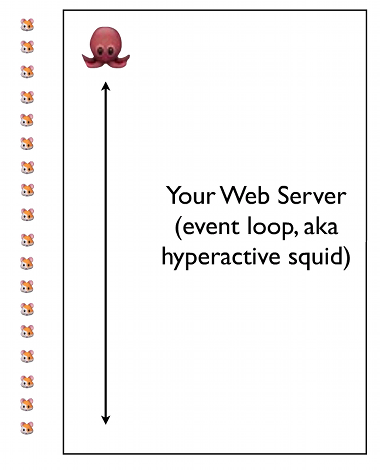
最初の例ではたくさんのウサギたちが並んでいて、次々に来るリクエスト(ネズミ)をさばいています。各ウサギは
- A:ネズミを受け取って
- B:何か処理をして
- C:それをレスポンスとして返す
という一連の処理をしています。実際にはAはHTTPリクエスト、Bはデータベースクエリ、CはHTTPレスポンスということになるでしょう。
ここで重要な点は、ウサギは1匹のネズミに対してA〜Cの処理が終わるまで、次のネズミの処理に取りかかれないことです。ここでもしBの処理が重かったりすると、徐々に順番待ちのキューが膨れ上がってしまいます。これに対処するには、複数のウサギを用意する必要があります。これが現在、多くのWebアプリケーションが取っている構成で、ウサギに相当するHTTPサーバを複数並べることで、並列性を高めています。
一方、2つ目の例として出てくるイベント駆動はタコです。タコもネズミを1匹ずつ処理するのに変わりないのですが、A〜Cまでのすべての処理が終わるのを待ったりはしません。Aのリクエストを受け取ると、データベースクエリを投げたまま、結果を待たずに次のネズミの処理に入ります。そして先ほどのデータベースクエリの結果が返ってきたら、それをキャッチしてレスポンスとして戻します(複数のリクエストを同時にさばくという意味で、タコなのでしょう。タコには手(足?)がたくさんあるので、一度に多くの処理ができそうです)。 こうすることで、タコは1人であるにもかかわらず、大量のネズミをさばくことができるのです。
これを実際のコードでベンチマークしてみましょう。
もし実際に試してみたい方は、node.jsをインストールしてください。UNIX系のOSの場合、インストールは非常に簡単です。node.jsのサイトからソースをダウンロードし、makeコマンドを以下のように実行するだけです。
$ ./configure $ make $ make install
ここではデータベースアクセスのかわりにsetTimeoutファンクションを使用しています。
Simonさんのブログは昨年のもので、node.jsのAPIはかなり変更されているため、最新のもの(v0.1.104)のAPIを使用したものに変更してみました。
まずは通常のHTTPリクエスト/レスポンスの例です。
var sys = require('sys'),
http = require('http');
var count = 0;
http.createServer(function (request, response) {
count ++
sys.log(count);
response.writeHead(200, {'Content-Type': 'text/plain'});
response.end('Hello\n');
}).listen(8124);
sys.log('Server running at http://127.0.0.1:8124/');
上のコードをhello.jsという名前で保存し、サーバとして立上げてみましょう。
$ node hello.js
このサーバに対して、ab(Apache Bench)で1000回(並列度100)のアクセスをしてベンチマークを計測します。私のマシンはMacBook ProでCPUコアは2つです。
結果は以下の通りです。
$ ab -n 1000 -c 100 'http://127.0.0.1:8124/' Time taken for tests: 0.285 seconds Requests per second: 3505.71 [#/sec] (mean) Time per request: 28.525 [ms] (mean)
次に2秒の待ち時間を加えた例です。
var sys = require('sys'),
http = require('http');
var count = 0;
http.createServer(function (request, response) {
count ++
sys.log(count);
setTimeout(function() {
response.writeHead(200, {'Content-Type': 'text/plain'});
response.end('Hello Sleep\n');
}, 2000);
}).listen(8125);
sys.log('Server running at http://127.0.0.1:8125/');
結果は以下の通りです。
Time taken for tests: 20.128 seconds Requests per second: 49.68 [#/sec] (mean) Time per request: 2012.764 [ms] (mean)
Time per request がTimeoutタイマーと同じほぼ2秒だというのが見て取れます。
「最初の例が0.2秒しかかかっていないのに、今回は100倍の20秒も時間かかっている。それって遅くない?」と思ったあなた、では次のコードを見てみてください。これはSimonのブログには載っていない例ですが、Timeoutファンクションの代わりにSleepをするファンクションに付け替えてしまいました。
var sys = require('sys'),
http = require('http');
var count = 0;
// Thanks to http://www.ozzu.com/programming-forum/javascript-sleep-function-t66049.html
var sleep = function (naptime){
var sleeping = true;
var now = new Date();
var alarm;
var startingMSeconds = now.getTime();
while(sleeping){
alarm = new Date();
alarmMSeconds = alarm.getTime();
if(alarmMSeconds - startingMSeconds > naptime){ sleeping = false; }
}
return "finished"
}
http.createServer(function (request, response) {
count ++
sys.log(count);
result = sleep(2000);
response.writeHead(200, {'Content-Type': 'text/plain'});
response.end('Hello Blocking Sleep ' + result + ' \n');
}).listen(8126);
sys.log('Server running at http://127.0.0.1:8126/');
結果は以下の通りです。
Time taken for tests: 2001.206 seconds Requests per second: 0.50 [#/sec] (mean) Time per request: 200120.554 [ms] (mean)
2秒×1000リクエスト=2000秒という結果と同等なのが見て取れますね。せっかくabの並列度を100にしているのに、まったくそれが生かされていない結果となりました。
逆にsetTimeoutの方は2秒×1000リクエスト/100=20秒と並列性が有効であることが分かります。並列度さえ上げれば、もっと速くなることでしょう。
両者を分けた違いは、setTimeoutがノンブロッキングなファンクションで、Sleepがブロッキングなファンクションであることにあります。setTimeoutが実行された後、JavaScriptは結果を待たずに次の処理に取りかかり(これを非同期処理と呼びます)、 setTimeoutに渡された関数(これをコールバック関数と呼びます)は2秒経った後に実行されます。
このコールバック、非同期処理を主体としたイベント駆動プログラミング手法は、通常のWebサーバを書くときには使わない概念ですが、ブラウザ上で実行されるJavaScriptはシングルスレッドしか使えないので日常的に使われています(ブラウザ上で先ほどのようなsleepファンクションを実行するとブラウザが固まってしまいます)。
このコールバック、非同期処理をサーバ側で全面に打ち出したフレームワークとして登場したのがnode.jsなのです。
「なるほど、イベント駆動でノンブロッキングだと、たくさんの同時アクセスがある場合にパフォーマンスが高いのか。でも私のサイトはそんなに同時アクセスがないから関係ないよね」。そう思われた方もいらっしゃるかもしれません。しかし、ノンブロッキングが真価を発揮するエリアがいくつかあります。
ファイルのアップロード
ビデオなど、大きなファイルアップロードというのは大変に難しい問題です。先ほどのTimeOutの例では2秒のブロックでしたが、何百MBにもなるようなファイルを送るとすると、何十秒、場合によっては分単位でのブロッキングが発生します。またアップロードの最中に、進捗具合をリアルタイムで知りたいという要求も出てきます。これまでにも進捗具合を表示するFlashベースのSWFUploadや、Webサーバのモジュールがありましたが、自分に合うようにカスタマイズするのが難しかったりします。
node.jsの初期からのコントリビューターであるFelix Geisendorferさんは、こうした処理が、node.jsを使っていかに簡単にできるかについてのブログを書いています。彼の会社が最近リリースしたTransloaditは、ファイルのアップロードと変換を提供するクラウドサービスなのですが、これはnode.jsで構築された最初の商業サイトの1つです。
チャット
以前「Lingr」というチャットサービスがあったのですが、作者の江島健太郎さんが「Lingr and Comet - 技術解説編」の中でチャットサービスのスケーリングの難しさを以下のように述べています。
通常、Apacheなどの一般的なウェブサーバは、短い応答時間で返せる処理を大量にこなすというスループット重視の前提で設計されています。このため、リクエストを受けたらそのリクエストに対してプロセスまたはスレッドをあてがい、最後まで面倒を見るという方式が一般的です。
ところが、先ほども言ったようにCometではコネクションはつなぎっぱなしになっていますから、いつまで経ってもプロセスやスレッド(およびメモリ資源)が解放されません。しかも、それらのスレッドは仕事もせずにアイドリングしており、メモリとCPUを浪費しているだけです。これは重大な問題です。どのぐらい重大かというと、そもそも千や万のオーダーの同時接続を実現することができません。
「複数のスレッドやプロセスを用いて同時接続を実現する」というのはリソースの浪費になるのですが、node.jsのイベント駆動の場合、立ち上げているプロセスは1つだけなので、リソースの観点から大変効率の良いモデルといえます。そしてこの「接続をつなぎっぱなしにする」チャットモデルは、これからお話しするWebSocketの世界と密接に関係してきます。
Copyright © ITmedia, Inc. All Rights Reserved.