いまさら聞けないHadoopとテキストマイニング入門:テキストマイニングで始める実践Hadoop活用(1)(3/3 ページ)
Hadoopとは何かを解説し、実際にHadoopを使って大規模データを対象にしたテキストマイニングを行います。テキストマイニングを行うサンプルプログラムの作成を通じて、Hadoopの使い方や、どのように活用できるのかを解説します
Hadoopを使うためのセットアップ
手元のマシンで手軽に試してみたいという用途ならば、セットアップ済みのVMwareのイメージが公開されていて便利ですので、こちらの使用方法を解説します。
ただ、本格的に使用するには、複数台のUNIX環境のサーバを用意することをお勧めします。
UNIX環境をお持ちの方は、Hadoopのオフィシャルページなどを見てセットアップしてください。オフィシャルページの日本語訳もあります。
また、「Cloudera's Distribution for Hadoop」を利用すると、apt-getやyumなどのコマンドでインストールができ、より簡単にセットアップすできます。Web上にCloudera's Distribution for Hadoopのセットアップ方法の日本語記事が多数見つかりますので、そちらを参照してください。
サーバを用意できないという方は、「Amazon Elastic MapReduce」というサービスの使用がおすすめです。これは、Amazonの仮想サーバでHadoopの処理を行えるサービスで、Hadoopのセットアップの手間がほとんど要りません。100台を1時間程度使用しても、大体1000円程度で使えます。
まずは、手元のVMWare上で小さいデータでテストして、Amazon Elastic MapReduceで、大規模なデータを解析するという使い方がよいでしょう。
Windows用のHadoop VMをセットアップ
Windows環境を対象に、Yahoo!から配布されている「Hadoop 0.20.S Virtual Machine」をセットアップする手順を説明します。
Mac環境でもVMWare Fusionを使えば、動かすことが可能です。「Yahoo! Cloud Virtual Machine Appliance − Yahoo! Hadoop Blog」に詳しく解説されています。
- 「VMWare Player」をインストールVMWare Player」をインストール
- 「Hadoop 0.20.S Virtual Machine」をダウンロードHadoop 0.20.S Virtual Machine」をダウンロード
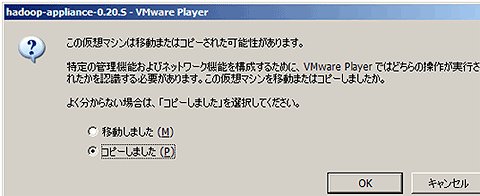
- ダウンロードしたファイルを解凍し、hadoop-appliance-0.20.S.vmxをダブルクリック
- 「移動しました」「コピーしました」という選択画面が現れるので,「コピーしました」を選択
起動すると、以下のようにHadoop VMに関する情報が表示されます。
** Welcome to Apache Hadoop tutorial by Yahoo Inc. ** Linux : Ubuntu 8.04 Java : JRE 6 Update 7 (See License info @ /usr/jre16/) Login: hadoop-user, Passwd: hadoop (sudo privileges are granted). The other logins are hdfs and mapred (passwd: hadoop). To start/stop hadoop: login as hadoop-user and run 'sudo /etc/init.d/hadoop restart' (also 'sudo /etc/init.d/hadoop' gives the usage) To format the HDFS & clean all state/logs: login as hadoop-user and run 'sudo reinit-hadoop' To shutdown Virtual Machine: login as hadoop-user and run 'sudo poweroff' To access hdfs and run mapreduce jobs, login as hadoop-user and run kinit. The password is hadoopYahoo1234. Environment for 'hadoop-user' (set in /home/hadoop-user/.profile) $HADOOP_HOME=/usr/local/hadoop $HADOOP_CONF_DIR=/usr/local/etc/hadoop-conf $PATH=/usr/local/hadoop/bin:$PATH IP Address of this Virtual Machine: 192.168.0.213
VirtualMachineには、rootとhadoop-userというアカウントが設定されていて、パスワードは、それぞれroot、hadoopです。hadoop-userでログインしてください。
なお、起動画面の、「IP Address of this Virtual Machine: 」と表示されているアドレスにPuTTYなどのSSHクライアント経由で接続すると、より便利です。
すでにHadoopは起動された状態ですので、円周率を計算するサンプルを実行してみます。セキュリティ対応のHadoopなので、kinitでパスワードを入力してから実行します。パスワードは、hadoopYahoo1234です。
hadoop-user@hadoop-desk:~$ cd hadoop hadoop-user@hadoop-desk:~$ kinit Password for hadoop-user@LOCALDOMAIN: hadoopYahoo1234 hadoop-user@hadoop-desk:~/hadoop$ bin/hadoop jar hadoop-examples-0.20.104.1.1006042001.jar pi 10 1000000
実行すると以下のような円周率が計算されると思います。
…… Job Finished in 61.415 seconds Estimated value of Pi is 3.14158440000000000000
なお、Cloudera's Distribution for HadoopでもVMWare用のイメージが公開されています。
次回は、テキストマイニングプログラミング開始!
今回は、Hadoopとテキストマイニングの概要と、Hadoopのセットアップ方法について解説しましたが、いかがでしたでしょうか。
次回はいよいよ、テキストマイニングのMapReduceプログラムの作成に入っていきたいと思いますので、お楽しみに。
Copyright © ITmedia, Inc. All Rights Reserved.