いまさら聞けないHadoopとテキストマイニング入門:テキストマイニングで始める実践Hadoop活用(1)(2/3 ページ)
Hadoopとは何かを解説し、実際にHadoopを使って大規模データを対象にしたテキストマイニングを行います。テキストマイニングを行うサンプルプログラムの作成を通じて、Hadoopの使い方や、どのように活用できるのかを解説します
Hadoopは、どのような場面で活用できるのか?
Hadoopの強みは、MapReduceを使って、数時間以上かかるようなバッチ処理を複数マシンに分散して、高速化できることです。つまり、1台だと少なくとも数時間以上かかるような、大量のデータを読み込んで解析する処理、大量の計算が必要な処理に向いているということになります。
例えば、Yahoo! JAPANでは、検索をする際のクエリなどのログ解析にHadoopを使用しています。
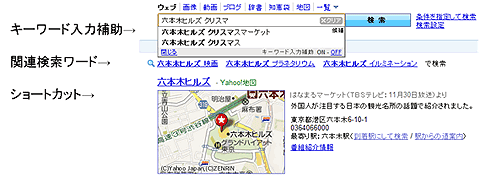
検索ログを解析することで、検索クエリに関連するワードを表示する「関連検索ワード」や、検索窓に一部の文字を入力するだけでキーワードが補完される「キーワード入力補助」、検索クエリに関連するYahoo! JAPANのサービスの情報を表示する「ショートカット」の表示制御などの機能を実現しています。
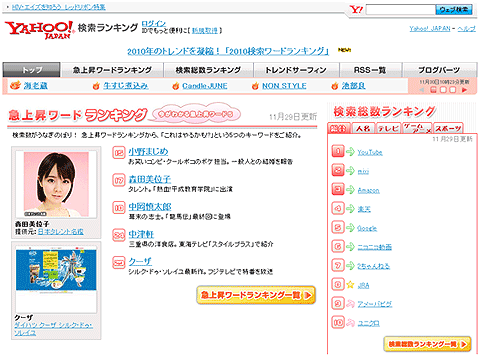
また、解析した結果を基に「Yahoo!検索ランキング」というサービスを提供していて、検索総数ランキングや急上昇ワードランキングなどを実現しています。
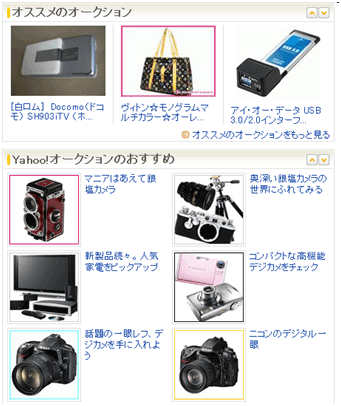
レコメンデーションの計算にもHadoopを使用しています。例えば、Yahoo!オークションのおすすめアイテムを表示する機能などに活用されています。
このように、大量のデータを解析し、有用な情報を生み出すことでサービスに活用することは、Hadoopの十八番であり、醍醐味(だいごみ)といえると思います。
そうした処理は、データマイニングなどと呼ばれますが、その中でも、Webページ(の本文)など、人間が書いた構造化されていないテキストを解析する「テキストマイニング」に焦点を当てて解説していきたいと思います。
未構造化テキストを解析する「テキストマイニング」
テキストマイニングとは、大量のテキストから、有用な情報や知識を発見することです。
例えば、数十件程度のテキストなら、人間の目で見て何らかの傾向が分かるかもしれませんが、100万件となると人間がすべて見るのは不可能です。しかし、テキストマイニングを使えば、コンピュータが大量のテキストからパターンや、関連、傾向などを分析し、それをさまざまな形で活用できます。
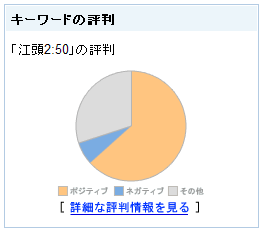
例えば、Yahoo!ブログ検索で、「キーワードの評判」という機能があります。
これは、検索したキーワードについて、評判や評価の表現をしていると思われる記事を抽出して解析し、キーワードがポジティブな評判が多いか、ネガティブな評判が多いかを表示しています。これは、テキストマイニングの典型的な例と言えるでしょう。
この例のようにWebからは大量のテキストデータが入手できるので、特にWebを対象としたテキストマイニングの重要性は増してきています。
構造化されていないテキストを構造化する「前処理」
データマイニングとは違い、テキストマイニングでは、人間が書いた構造化されていないテキストを対象としています。そのため、テキストマイニングでは、テキストを構造化された中間表現に変換する前処理が必要です。
前処理では、文字列を単語に切り分けたり、単語列に文としての構造を付与したり、構造を意味に結び付けたりする必要がありますが、これらの処理は、「自然言語処理」と呼ばれる分野の知識が必要になります。
前処理の中でも最もよく行われる形態素解析について見ていきましょう。
日本語の文字列を単語ごとに切り分ける「形態素解析」
日本語の文字列を単語ごとに切り分ける処理のことを形態素解析と言います。日本語は英語のように単語間に区切りがないので、品詞ごとに区切ることになります。
例えば、「男の中の男だね」という文は以下のような品詞に区切られます。
形態素解析を行うソフトウェアは、「Mecab」などオープンソースのものがたくさん存在し、Yahoo!JAPANでもWeb APIとして提供しています。
ベクトル化
形態素解析で、文字列を単語ごとに切り分けられましたが、この単語列をテキストマイニングで扱いやすいように構造化する必要があります。そこで、テキストをベクトルで表することを考えてみます。
ベクトル化できれば、例えば簡単にベクトル同士の近さを計算でき、テキストマイニングで扱いやすくなります。それぞれの単語がそのテキストでどの程度重要かを重み付けし、ベクトルで表してみましょう。
例えば、名詞の単語を抽出し、その単語のテキストでの頻度をベクトル化してみます。「男の中の男の中でも特に男臭い男は男の中の男の中の男となる」というテキストは、以下のようにベクトル化されます。
(男, 中) = (6, 4)
このようなベクトル化の方法は、「bag-of-words」と呼ばれます。単語の順番や、文の構造は無視して、単語の種類だけでテキストを表現するのが特徴です。
マイニング処理
前処理で、テキストを構造化された中間表現に変換できたので、いよいよマイニング処理に入ります。
マイニング処理では、相関関係を調べたり、繰り返し現れるパターンを発見したり、何らかの情報を抽出したり、目的によってさまざまな処理を行います。例えば、先ほどのYahoo!ブログ検索の「キーワードの評判」の例では、テキストから「かっこいい」「大嫌い」など、評判や評価に関する表現を抽出します。
このようにマイニング処理にもさまざまな種類がありますが、本連載ではその中でも「テキスト分類」を取り上げ、解説していきます。
テキストを自動的に分類する「テキスト分類」
テキスト分類は、テキストを何らかのカテゴリに自動的に分類する処理です。例えば、新聞記事を内容に応じて、「政治」「経済」「社会」「スポーツ」などのカテゴリに分類します。
テキスト分類は、さまざまな処理に応用されています。例えば、メールのスパムフィルタリング処理は、メールを「スパム」「スパムでない」の2つのカテゴリに分類する、テキスト分類処理です。
他にも、テキストの言語判定、テキストがアダルトかそうでないかのフィルタリング、テキストの著者判定、テキストの著者の属性推定などがあります。テキストの著者の属性推定は、テキストの著者の性別、年齢、地域、職業などを推定する処理です。
テキスト分類には、機械学習の手法を用いることが多いのですが、詳しい処理内容については次回以降に解説することにします。
次ページでは、本稿の最後にHadoopのセットアップ方法について簡単に解説します。
Copyright © ITmedia, Inc. All Rights Reserved.