検索エンジンの常識をApache Solrで身につける:ビッグデータ処理の常識をJavaで身につける(1)(3/4 ページ)
Hadoopをはじめ、Java言語を使って構築されることが多い「ビッグデータ」処理のためのフレームワーク/ライブラリを紹介しながら、大量データを活用するための技術の常識を身に付けていく連載
現在利用できる主な検索エンジン9選
現在までに、さまざまな企業・団体が商用・OSS(オープンソース)のものを合わせて、多数の検索エンジンを開発しています。以下に、よく知られているものを集めました。
- 商用
- Sedue
Preferred Infrastructer社が開発した検索エンジン。アルゴリズムに接尾辞配列を利用している - Fast ESP
ノルウェーのファストサーチ&トランスファ社が開発した検索エンジン。高いスケーラビリティと柔軟なカスタマイゼーションを提供し、多くの大規模サービスで利用されている。マイクロソフト社に買収されたが、現在もマイクロソフト社から購入できる - ConceptBase Enterprise Search
ジャストシステム社が開発した検索エンジン。古くから日本語処理を開発してきた知見を生かした、高い検索精度に特徴を持つ
- Sedue
- OSS
- Apache Lucene(以下、Lucene)
Javaで書かれた検索エンジン。Luceneはインデックス部分のみの実装なので、Luceneをベースに検索システムを構築するには多くの手間が掛かる - Apache Solr
Luceneをベースにした検索エンジン。Luceneが提供するものも含め多様な機能を提供。多くの企業・組織で利用実績を持つ - Katta
Solrと同じくLuceneをベースにした検索エンジン。分散検索やクラスタ構成でリッチな機能を提供 - Sphinx
C++で記述された検索エンジン。非常に高速に動作します。欧米の検索サービスで導入実績がある - Senna
Cで記述された検索エンジン。MySQLとの親和性が高いという特徴を持つ - Namazu
日本のOSS検索エンジンの中では最も長い歴史を持つ
- Apache Lucene(以下、Lucene)
Solrクイックスタート!
それでは、検索エンジンを代表してSolrを実際に使用してみます。
JVM環境の準備
SolrはJVM環境で動作するため、Java実行環境をインストールする必要があります。初めに、JDK 1.5以上をダウンロードしてインストールした後、環境変数「JAVA_HOME」を設定しておいてください。
Solr 3.4のダウンロード&インストール
Solrの最新バージョン(原稿執筆時では3.4)をダウンロードページからダウンロードしてください。
Solrのインストールは非常に簡単です。では実際に利用してみましょう。初めに以下のコマンドでダウンロードしてきた「apache-solr-***.tar.gz」ファイルを解凍し、Solrの起動ディレクトリまで移動します。
$ tar zxvf apache-solr-3.4.0.tgz $ cd apache-solr-3.4.0/example
起動ディレクトリで、以下のコマンドを実行すると、Solrが立ち上がります。
$ java -jar start.jar &
この後、以下のようなログがターミナルに出ます。
2011-10-11 11:40:33.170:INFO::Logging to STDERR via org.mortbay.log.StdErrLog 2011-10-11 11:40:33.327:INFO::jetty-6.1-SNAPSHOT 2011-10-11 11:40:33.413:INFO::Extract file:apache-solr-3.4.0/example/webapps/solr.war to tmp/apache-solr-3.4.0/example/work/Jetty_0_0_0_0_8983_solr.war__solr__k1kf17/webapp 2011/10/11 11:40:34 org.apache.solr.core.SolrResourceLoader locateSolrHome ……
Solrがうまく起動できているのかをチェックために、Webブラウザを起動します。WebブラウザでURL「http://localhost:8983/solr/admin」と入力すると、以下のようなSolrのアドミニストレータ用ページが開きます。
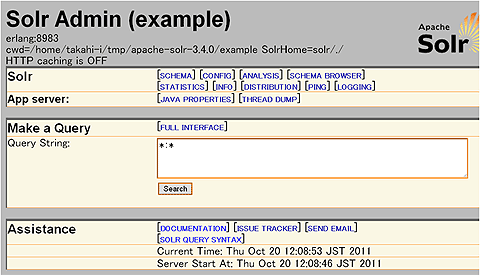
アドミニストレータ用UI内の[Query String]と記述のあるフォームにクエリを入力して[Search]ボタンを押すと、インデックスを検索できます。デフォルトの検索クエリ(検索クエリを入力するフォームに初めに表示)は「*:*」でインデックスされているすべての文書を取得します。残念ながら、まだ何もインデックスしていないため、図3のように検索結果は0件(numFound=0)となります。

文書のインデックスと検索
起動しているSolrに文書をインデックスしてみましょう。インデックスするサンプルデータと必要なプログラムは「exampledocs」ディレクトリにあります。以下のコマンドを実行してください。
$ java -jar exampledocs/post.jar exampledocs/*.xml
これでインデックスに文書を追加できました。うまくインデックスを検索できるかアドミニストレータUIで見てみましょう。アドミニストレータUIで[Search]ボタンを押すとインデックスされたすべての文書を検索します。図4のような検索結果が出ると、インデックスは無事生成できています。

次ページでは最後に、Solrを使いこなすために今後学ぶべきことを紹介します。
Copyright © ITmedia, Inc. All Rights Reserved.