検索エンジンの常識をApache Solrで身につける:ビッグデータ処理の常識をJavaで身につける(1)(4/4 ページ)
Hadoopをはじめ、Java言語を使って構築されることが多い「ビッグデータ」処理のためのフレームワーク/ライブラリを紹介しながら、大量データを活用するための技術の常識を身に付けていく連載
Solrを使いこなすために今後学ぶべきこと
前節までにSolrを起動して利用するまでを、ざっと見てきました。しかし、今説明した部分はSolr全体の非常に限られた部分です。実際にサービスなどで利用するには、まだまだたくさん学ぶ必要があります。今後Solrを本格的に学ぶ前に知っておくと便利なトピックと簡単な説明を列挙しておきます。
設定ファイル
Solrの設定ファイルはSolrのインストールディレクトリ内の「conf」ディレクトリにあります。その中で以下の2つが特に重要な設定ファイルです。
- schema.xml
インデックスの構成を表す。どのようなフィールドを持ったインデックスを作るのかを設定できる - solrconfig.xml
インデックス構成以外の多くの設定を行う。具体的にはキャッシュサイズや分散設定、利用するサブコンポーネントを設定
便利な機能3選
Solrは多様な便利機能を提供しています。以下はSolrが提供する機能の一例です。もちろんSolrに頼らなくても、これらの機能は自作できますが、バグが入りやすい個所でもあるので、検索エンジン自体がサポートするのはユーザーとして非常に頼もしいと感じるのではないでしょうか。
- 【1】インデックスのレプリケーション
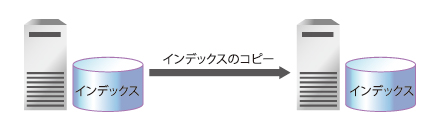
1つのインスタンスで生成したインデックスを他のSolrインスタンスに自動でコピーできます。これによって、1つのインスタンスが落ちた場合でも同一のインデックスを保持するインスタンスで検索処理を継続できるようになります。
また、インデックスを行うインスタンスと、ユーザーからの検索を引き受けるインスタンスを分けることで、「インデックス中にも検索性能の劣化が起こらない」というメリットもあります。
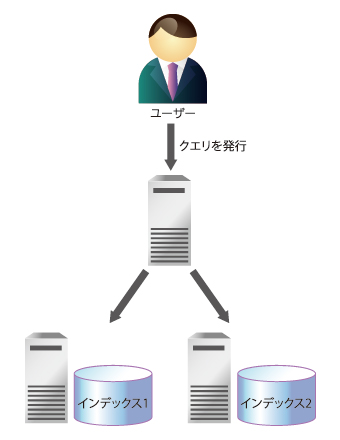
- 【2】shardインデックス
1つのインスタンスで非常に大きなインデックスを保持すると、インデックスがメモリに載り切らないため、検索性能が劣化する恐れがあります。この問題に対処するためにSolrは、複数の計算機に分散しているインデックス集合から返される検索結果を、まとめる仕組みを持ちます(図6参照)。
- 【3】クエリパラメータ
Solrに発行するクエリにクエリパラメータを付加することで、ソートしたり、走査するフィールドを限定できたりします。非常に、たくさんのパラメータがあるので、ぜひ一度調べてみてください。
Solrのチューニング個所
- JVM(Java Virtual Machine)
SolrはJVMのチューニングを行わなくても、ある程度高速に動作します。しかしインデックスが大きい場合や、非常に利用ユーザー数が多い場合には、ある程度JVMのチューニングが必須です。
高負荷状況でチューニングや計算機リソースが十分でないと、最悪JVM がFull GC処理から返らない「Stop The World」という状態になり、検索結果をまったく返さなくなります。
- キャッシュ
検索結果や、インデックスに存在する文書をキャッシュに載せておくことで、高い性能を獲得できます。Solrでは、キャッシュの大きさをシステム、計算機に合わせて設定できます。
- インデックスサイズ
一台で処理するインデックスサイズがあまりにも大きい場合、インデックスを複数の計算機に分割して保持することで検索性能を著しく向上できます。
日本語トークナイザ
現状Solrは日本語用の単語単位のトークナイザ(形態素解析器)をデフォルトではサポートしません。「検索エンジンで利用する主な手法」で紹介した「(文字)N-Gramトークナイザ」を利用することで、日本語文書をインデックスして検索サービスを構築できます。
しかし、もし単語単位のトークナイザを利用して日本語文書をインデックスしたい場合は、日本語形態素解析器をSolrで利用できるように自分で設定する必要があります。
現在無料で利用できる形態素解析器としては「Sen」「Gosen」「Kuromoji」が有名です。また、Basis Technology社が提供するトークナイザも有料ですが利用できます。
検索エンジンとSolrをより深く理解するために
Solrは、かなり大きなコンポーネントです。そのため、前節「Solrを使いこなすために今後学ぶべきこと」で列挙したトピックだけを知っていれば大丈夫というわけにはいきません。実際にシステムを構築する際、もしくはシステムの運用中に問題に遭遇することが必ずあると思います。このようなときSolrコミュニティの大きさが助けとなります。
具体的には、Solrのメーリングリストで質問することで、Solrプロジェクトのコミッタを含め多くの人からアドバイスを受けられます。Solrユーザーのメーリングリストは「solr-user@lucene.apache.org」です。ぜひ登録してみましょう。
またSolrは、技術者用Wikiページを整備しており、Solrの持つ各機能やTipsなど広範囲に及ぶ技術的トピックをカバーしています。Solrの扱いに慣れたころに読んでみると、Solrが提供する機能に関して多くの発見があると思います。
またSolrは、バグ修正や今後のタスクを「Jira」というプロジェクトマネジメントツールで開発しています。開発者でなくてもJiraを閲覧できるので、ぜひチェックしてみましょう。このページをチェックすることで現在のSolrの開発や今後のリリース予定について、状況が俯瞰できます。
本もいくつかありますが、中でも筆者のオススメは、RONDHUIT社の関口宏司氏が中心となって執筆した、『Apache Solr入門』です。この本はSolrの機能や使い方を非常に分かりやすく解説しています。
最後に、筆者は「Anuenue」というSolrのラッパーを開発しています。Anuenueは比較的簡単にSolrクラスタを構築するためのツールです。現在ミクシィが提供する「mixi ページ」というサービスで利用しています。AnuenueはOSSプロジェクトとして公開しているので、興味のある方は利用してコメントをいただけると幸いです。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
- オープンソースの検索エンジン登場
[コラム]安藤幸央のランダウン(23) - ユーザーの満足度を向上させるプラグイン活用
RoRでCGMサイト構築虎の巻(6) - “最適な”全文検索システムの選択
RoRでCGMサイト構築虎の巻(5) - 全文検索を実装したソースコードを読もう
Railsコードリーディング〜scaffoldのその先へ〜(6) - 全文検索エンジン「Lucene.Net」を使う
連載:VBで実践! 外部コンポーネント活用術 - 見つけて得するソースコード専用の検索エンジン
安藤幸央のランダウン(33) - Javaで覚えるIT技術者の40の常識
新人プログラマ/SEは覚えておきたい“まとめ”