並列分散処理の常識をHadoopファミリから学ぶ:ビッグデータ処理の常識をJavaで身につける(2)(1/3 ページ)
Hadoopをはじめ、Java言語を使って構築されることが多い「ビッグデータ」処理のためのフレームワーク/ライブラリを紹介しながら、大量データを活用するための技術の常識を身に付けていく連載
Hadoopが押し上げた「BigDataビジネス」
「複数のマシンに大量データ処理を分散して飛躍的に性能を向上する」といわれるJava言語のフレームワーク「Apache Hadoop」。ご存じの方も多いことでしょう。
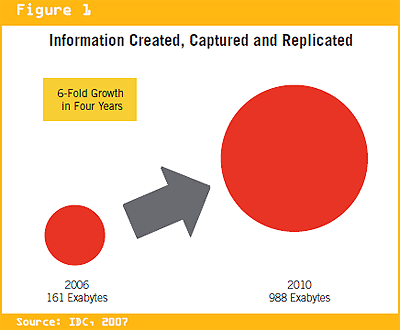
「情報大爆発」というフレーズがIDCレポートで登場したのは2007年でしたが、これを「BigDataビジネス」へと発展させたのは、おなじみのJava言語でテラバイト級のデータを処理できる「Hadoop」が、大きな役割を担っているのではないでしょうか。
しかし、Java言語がおなじみとはいえ、ITエンジニアからは「MapReduceプログラミングは難しい」という声もよく聞かれます。「MapReduce」という耳慣れない言葉と、「並列プログラミング」が古くから抱える問題が合わさって、余計に難度を上げているようです。
マルチコアや分散環境で動く並列プログラムを支援する技術は、コンパイラの自動並列化機能や、関数型言語などが登場しましたが、その難しさは今も解決されたとはいえません。
残念ながら「MapReduce」も、全ての課題を解決したわけではないのです。しかし、Hadoop/MapReduceは「分散」を意識せず「並列」化を安全に実現する優れたアーキテクチャを持っていて、「並列プログラミングの強力な武器」といえます。今回は、「並列分散処理」が持つ課題と、Hadoopとその関連プロダクトがどのように課題を解決しているかをひも解いていきます。
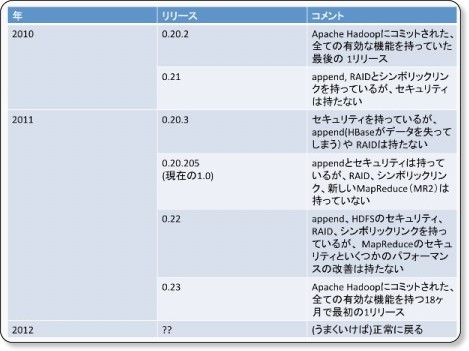
コラム「いまさら? Hadoop 1.0がリリース」
2011年12月27日にHadoopの1.0がリリースされました。「これだけ話題になっているのに、いまさら1.0?」と意外に思う方もいるかもしれませんが、ようやく安定版になったようです。詳細はHadoopのディストリビューションを提供しているCloudera社の下記ページを参照してください。
「Hadoopファミリ」が教えるHadoopの課題
複数のマシンに処理を分散させて大量データ処理を飛躍的に向上させる「Hadoop」は、一般にはHDFS+MapReduceだけを指して話すことが多いようですが、実体は複数のHadoopにかかわるプロジェクトが集まった「Hadoopファミリ」の総称です。
「HDFS(Hadoop Distributed File System)」「MapReduce」は、コアとなるサブプロジェクトであり、それ以外にも8つの関連プロジェクトや、関連プロジェクトに含まれない多数のプロジェクトがHadoopの課題を補っています。
まずは現在の「Hadoopファミリ」の家族構成を見てみましょう。
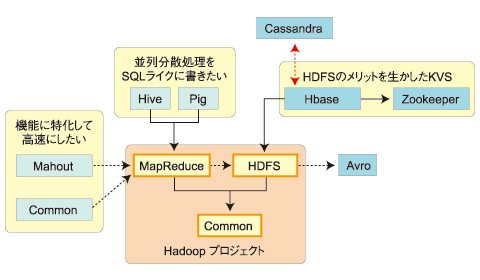
Hadoopプロジェクトは3つの「サブプロジェクト」で構成されています。
- Common:Hadoopの基本機能FileSystem、RPC、Serializationのライブラリ
- HDFS:分散ストレージを仮想的に1つに扱うためのファイルシステム
- MapReduce:膨大なデータセットをクラスタ上で分散処理するためのソフトウェアフレームワーク
これらが、「Hadoopファミリ」の核であり、並列分散処理機構を支えています。それ以外の「関連プロジェクト」は2011年12月時点では下記のようになっています。
- Avro:Commonの持つ機能を拡張したデータシリアライズシステム
- Cassandra:単一障害点のないスケーラブルなマルチマスタデータベース
- Chukwa:大規模な分散システムでのデータ収集システム
- HBase:大規模な構造化データをサポートする、スケーラブルな分散データベース
- Hive:データへのアドホッククエリを行う高レベル言語
- Mahout:スケーラブルな機械学習とデータマイニングのライブラリ
- Pig:高レベルデータフロー言語および実行フレームワーク
- ZooKeeper:分散アプリケーション用の高性能コーディネーションサービス
図2の実線と破線は関連プロジェクトの「サブプロジェクト」への依存関係を表しています。
破線が「関連はあるが独立」しているもので、MahoutやChukwaなどがこれに当たります。Hadoopのない環境でも単独で動かせるので、少量データでトライできます。もちろん、これらはHadoop上で動かすことを考慮した作りになっており、連携させることでスケールアウトします。AvroはHadoopから利用されるプロジェクトですが、他のシステムで利用されることも考慮されています。
実線は「サブプロジェクトに依存」するプロジェクトPigやHiveで、単独で動くのではなく、Hadoop上で生産性を向上させるために使います。
【検証】Hadoopは本当に速さが“売り”なのか
HDFS+MapReduceについては、すでに多くの情報が公開されているので、ここではRDBと比較して、その向き不向きに焦点を当てていきます。
ストアドプロシジャとMapReduceを比較
以前、RDBとHadoopの性質を調査するため、ある同じ処理をストアドプロシジャとMapReduceの双方で開発し、それらの性能、コード量を計測したことがあります。期待通り、Hadoopクラスタのノード増加に従って処理性能はリニアに向上し、28ノードのHadoopクラスタはRDBの16倍の性能を実現しました(参照:Apache Hadoop、身近な処理から使ってみませんか)。
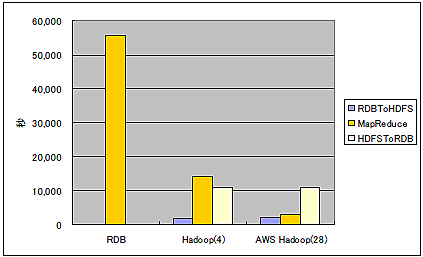
ところが、この結果を見たチームメンバからは「この結果はフェアじゃない」という異議が上がりました。ごもっともです。
RDBは1ノード、Hadoopは28ノードまでリソースを増強していますから、速いのは当たり前です。では、RDBにも同じリソースを与えて、RDBクラスタ環境で計測すればどうでしょう。比率を見ると、むしろRDBの方が速いかもしれません。
RDBにも同じリソースを与えてHadoopと比較
実際に検証を行った論文も紹介しておきましょう。論文「A Comparison of Approaches to Large-Scale Data Analysis」では、パラレルRDBMSとして「Vertica」とベンダの商用製品「DBMS-X」を採用し、Hadoopと性能比較を行っています。
例えば、図4は1TbytesのデータからSELECT処理で特定の文字列を抜き出す処理にかかった時間を示しています。ご覧のように、SELECT処理は全般に2〜5倍ほどRDBの方が高い性能を示しており、検索系の処理はHadoopが劣勢といえそうです。
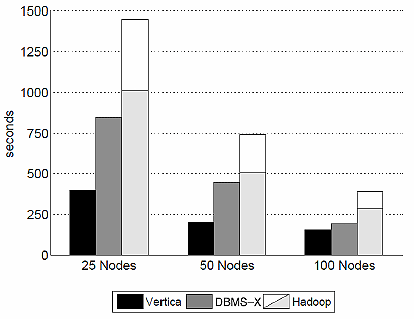
図4 「Grep Task Results - 1TB/cluster Data Set」(論文「A Comparison of Approaches to Large-Scale Data Analysis」より)
もっとも、全ての処理で同じ傾向ではなく、データ登録の性能についてはHadoopが5〜20倍ほど高い結果を示しています。登録処理が多いバッチ処理ではHadoopが優勢のようです。
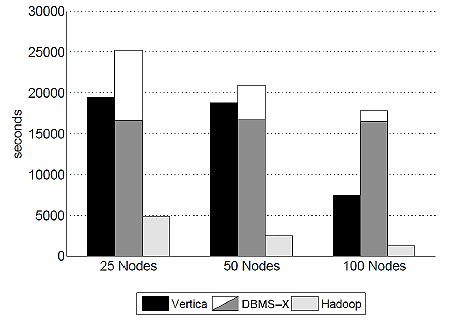
図5 「Load Times - Grep Task Data Set(1TB/cluster)」(論文「A Comparison of Approaches to Large-Scale Data Analysis」より)
RDBからデータ移行してまでHadoopを使うメリットとは
データの保守性を考えれば、処理の元データはRDBに格納する運用が多いことでしょう。その場合、Hadoopを使うためにはRDBからHadoopクラスタにデータを移行しなくてはいけません。その分余計な移行コストが掛かります。こうした点を踏まえて使う、Hadoopのメリットとは何でしょう?
次ページでは、まず、並列分散処理の課題から確認していきます。
Copyright © ITmedia, Inc. All Rights Reserved.