まとめてたくさん処理したい! を解決する「Capistrano」:特集 DevOps時代の必須知識
インフラ運用の自動化を実現し、DevOpsを支援するツールはいくつかあります。ここではその中から「Capistrano」というツールについて、サンプルを用意しつつ紹介します。
はじめに
インフラ運用の自動化を実現するツールには「Chef」や「Puppet」などいろいろあります。今回の記事ではそういったツールのうち、Capistranoというツールを簡単なサンプルを用意しつつ紹介します。
Capistranoとは
Capistranoとは簡単にいうと、オープンソースで提供されている、複数のサーバ上で同時にスクリプトを実行するためのソフトウェアツールです。主に、同じ役割のサーバが複数台存在するような環境での自動化であったり、アプリケーションのデプロイ自動化に利用されています。
特にRuby On Railsを利用したアプリケーションのデプロイには標準で対応しており、簡単な設定ファイルを用意するだけで複数台のサーバで構成される環境におけるデプロイの自動化を簡単に実装できることから、Railsアプリケーションのデプロイに広く利用されています。個々の環境での作り込みは必要となりますが、Ruby以外の言語やフレームワークを利用して書かれたアプリケーションのデプロイ自動化にも利用できます。
Chefとの違いは、Chefは主にプル型といわれるアーキテクチャであるのに対し、Capistranoはプッシュ型です。従って対象のサーバ上にエージェントのようなものをインストールする必要はありません。SSHでアクセス可能であればすぐに利用できます。
利用事例
筆者は「eXcale」というクラウドサービスに携わっているのですが、実は、このサービスではCapistranoを積極的に利用しています。
eXcaleとは、TISが2012年10月よりβサービスとして開始したプラットフォームサービスで、開発者はアプリケーションを公開するためのサーバやネットワークを考えることなくインターネット上にアプリケーションを簡単・迅速に公開可能です。特徴の1つにオートスケールがあり、特別な設定をしなくてもアプリケーションの負荷に応じて、「自動」でスケールアウトできます。
こういった処理をアプリケーションから制御する上で、Capistranoを有効活用しています。状況に応じて、タイムラグを可能な限り小さく抑えつつサーバの構成を行うためには不可欠なコンポーネントとなっています。なお、eXcaleは現在はβサービスのため、全て無償で利用可能です。
このようにeXcaleというサービスを提供する上で、ユーザーの環境に合わせた自動構成を行うためにCapistranoを利用していますが、同じくらい有用なシチュエーションとして挙げられるのが、運用作業における自動化です。
eXcaleでは何らかの運用作業をする場合、数十台以上のサーバに対して一斉に同じ作業を行うことが多々あります。これを人手でやる場合、非常に時間もかかりますし、同じ作業を繰り返し行うことによる気の緩みからミスも誘発しがちです。
そこでCapistranoを使って必要な運用作業をスクリプト化し、一回の実行で全サーバを対象に作業する、といったことを行っています。
また、eXcaleではインフラとしてAWSを利用しており、オートスケールなどクラウドのメリットを最大限に活かしたインフラを構成しています。従って同一の役割のサーバでも、昨日と今日とで、台数はもちろんIPアドレスも異なっている可能性があります。Capistranoは実行する処理内容をRubyで記述しますので、こういった動的な処理に関しても比較的容易に対応可能です。
eXcaleでは、AWSが提供するRuby用のSDKを利用して各インスタンスに付与したタグを基にIPアドレスを取得し、その時点での処理対象サーバを動的に設定する、といった処理を多く行っています。このように、普段Rubyで開発を行っているWebアプリケーションの開発者にとっては、比較的なじみやすいと思われます。
Capistranoの使い方、サンプル
ここからは実際にCapistranoの使い方のごく基本的な部分について簡単に紹介していきます。
環境
今回の記事における筆者の環境は以下のようになっています。
| 環境 | バージョン |
|---|---|
| OS | Mac OS X Mountain Lion |
| Ruby | 1.9.3-p392 |
| Capistrano | 2.14.2 |
以降の解説は、特に断りがない限り上記の環境にて説明しています。お使いの環境が異なる場合は、適宜環境に合わせて読み替えてください。
導入
Capistranoの利用にはRubyが必須となります。Rubyが導入されていない場合は公式サイトなどを参考に導入しておいてください。CapistranoはRubyGemsによって配布されているため、以下のコマンドでインストール可能です。インストールを行うのはCapistranoを実行するマシンだけです。
$ gem install capistrano
インストールが完了し、capコマンドが実行できればインストールは完了です。
$ cap -V Capistrano v2.14.2
Capistranoを利用するための条件
Capistranoを使った自動化を行うためには、2つの条件を満たす必要があります。1つはCapistranoをインストールしたマシンからSSH接続可能なことであり、もう1つは同時に実行するサーバのユーザー/パスワードが同じであること、もしくは鍵ファイルを用いたパスワードなしの接続が可能になっている必要があります。このとき、不正ログインを防ぐためパスワードは適切に管理する必要があり、公開鍵認証による運用が推奨されています。
基本的な使い方
Capistranoでは、capfile(もしくはCapfile)と呼ばれるファイルに実行する処理内容を記述します。このファイル内に必要となる処理をタスクとして実装していきます。1つのcapfile内に複数のタスクを定義しても問題ありません。
では、早速簡単なサンプルを用意して実行してみます。以下の内容を記述したファイルを「capfile」という名前で用意してください。
task :count_dirs, :hosts => "192.168.1.1" do run "ls -l / | grep ^d | wc -l" end
上記の例では1つのタスクを定義しています。このタスクは192.168.1.1というサーバを対象にしており、リモートサーバ上で"/"直下のディレクトリの数をカウントしています。カレントディレクトリにcapfileがある場合は以下のコマンドで実行できます。
$ cap count_dirs
この場合、実行すると対象サーバのパスワードが聞かれますので、正しいパスワードを入力すると処理が行われます。
また、複数のタスクの定義や、実行対象のホストとして複数サーバをセットすることは当然ですが、実行対象のホストをグルーピングしてタスクごとに切り替えて指定することも可能です。
role :web, "192.168.1.1", "192.168.1.2" role :db, "192.168.2.1", "192.168.2.2" task :count_dirs, :roles => :web do run "ls -l / | grep ^d | wc -l" end task :count_processess, :roles => :db do run "ps aux | sed -e '0,1d' | wc -l" end
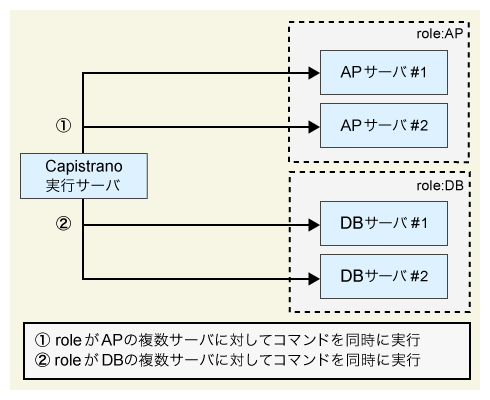
Capistranoでは実行対象のサーバに「ロール」を設定し、特定のロールに所属する複数のサーバ全てに対して処理を実行することが可能です。
上記の例では、webとdbというロールに対し、それぞれ複数サーバを指定しています。その上で、各タスクで実行対象の指定にロールを使用し、「count_dirsを実行する場合はweb」「count_processesを実行する場合の対象はdb」というロールを指定して、それぞれ実行対象を切り替えています。
こちらも先ほどと同じように実行してみてください。先ほどと同じようにパスワードを聞かれますが、入力したパスワードですべてのサーバに対して接続を試みます。そのため、先述の通り同時に実行するすべてのサーバでユーザー/パスワードが同じである必要があります。
なお、タスクでロールを指定していない場合、定義されている全てのロールに対して処理が実行されます。
タスクの実装
タスクの実装についてですが、Rubyをご存知の方であれば難しいことはなく、通常のRubyによるプログラミングと変わりません。
Capistranoでは、主にrunというメソッドを利用してサーバ側で実行する処理をタスクとして記述していきます。このrunというアクションの引数として対象サーバ上で実行したいコマンドを指定します。先ほどの例ではcount_dirsの中でrunメソッドの引数に対象サーバ上で実行するコマンドとして"ls -l / | grep ^d | wc -l"を指定しています。
このrunメソッドが基本となりますが、その他にも利用可能なものとしてupload、putといったファイル転送に関するものや、captureというコマンドを実行した上で結果の標準出力を取得するメソッドが存在します。このあたりの詳細は、公式ドキュメントの該当ページを参考にしてください。
最後に
以上、駆け足でCapistranoについて紹介してきました。
Capistranoでできることは非常にシンプルですが、その分使い方も簡単です。Rubyを使える方であればタスクの実装もそれほど難しく感じないでしょう。
ただし、実際に自動化を実現する際には、CapistranoだけではなくChefとの組み合わせなど、いろいろなツールを適材適所で組み合わせる必要があります。複数のサーバに対してプッシュ型で同時並行で処理を行いたい場合などにCapistranoは非常に向いていると思われます。ぜひこの点を理解して、使いこなしてください。
関連特集:DevOpsで変わる情シスの未来
今やクラウド、ビッグデータに次ぐキーワードになったDevOps。だが前者2つが通過したようにDevOpsも言葉だけが先行している段階にあり、その意義や価値に対する理解はまだ浸透しているとはいえない。ではなぜ今、DevOpsが必要なのか? DevOpsは企業や開発・運用現場に何をもたらすものなのか?――本特集では国内DevOpsトレンドのキーマンにあらゆる角度からインタビュー。DevOpsの基礎から、企業や情シスへのインパクト、実践の課題と今後の可能性までを見渡し、その真のカタチを明らかにする。
Copyright © ITmedia, Inc. All Rights Reserved.